Bloom-Filter的解析
Bloom Filter概念
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
基本原理
初始状态
Bloom Filter是一个m位的位数组,且数组被0所填充。同时,我们需要定义k个不同的hash函数,每一个hash函数都随机的将每一个输入元素映射到位数组中的一个位上。那么对于一个确定的输入,我们会得到k个索引。插入元素
经过k个hash函数的映射,我们会得到k个索引,我们把位数组中这k个位置全部置1(不管其中的位之前是0还是1)- 查询元素
输入元素经过k个hash函数的映射会得到k个索引,如果位数组中这k个索引任意一处是0,那么就说明这个元素不在集合之中;如果元素处于集合之中,那么当插入元素的时候这k个位都是1。但如果这k个索引处的位都是1,被查询的元素就一定在集合之中吗?答案是不一定,也就是说出现了False Positive的情况。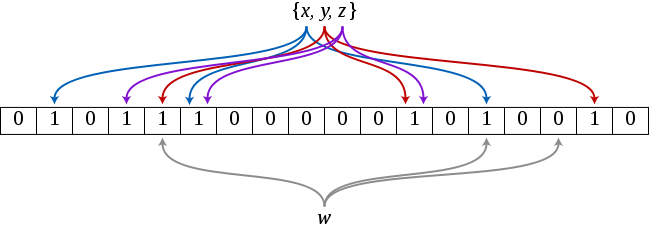
在上图中,当插入x、y、z这三个元素之后,再来查询w,会发现w不在集合之中,而如果w经过三个hash函数计算得出的结果所得索引处的位全是1,那么Bloom Filter就会告诉你,w在集合之中,实际上这里是误报,w并不在集合之中。
误报率估计

Bloom Filter的实现
纸上得来终觉浅,绝知此事要躬行。
若读者想深入研究Bloom Filter,可以去知网下载《基于LSM-tree键值系统读性能优化》(张月明)。
参考资料: