Notes about Cuckoo hashing
本文将mark下Cuckoo hashing相关notes。
1. Why
Cuckoo hashing is a scheme for resolving hash collisions of values of hash functions in a table(解决表中哈希函数值的哈希碰撞问题), with worst-case constant lookup time.
2. What
The name derives from the behavior of some species of cuckoo, where the cuckoo chick pushes the other eggs or young out of the nest when it hatches(这一名称源于某些种类杜鹃的行为,即杜鹃雏鸟在孵化时会将其他蛋或幼鸟推出巢外); analogously, inserting a new key into a cuckoo hashing table may push an older key to a different location in the table.
3. How
In the basic variant of Cuckoo hashing we use two hash tables T1 and T2 of equal size, and we index them with the hash functions h1, respectively h2. Here are the main operations:
3.1 Search
Search couldn’t be easier: an element x can exist in one of two locations: in T1 at position h1(x) or in T2 at position h2(x). We can check both locations in constant time.
3.2 Delete
Delete is similarly easy: we look at the two possible locations, and if the element is there, we delete it.
3.3 Insert
Insert is a bit trickier: we put x in T1[h1(x)]. If there was some element y stored in that location, y must be evicted (thus the name “cuckoo” hashing). We put y in its other valid location T2[h2(y)]. If that location is occupied by some element z, we have to evict z and insert it in its other valid location T1[h1(z)]. We continue like this until we find an empty place and the process finishes, or until we give up because because we ran into a loop. If the latter happens, we conclude that insert failed, we stop and we rehash everything with new hash functions (increasing the table sizes if the tables are getting too full).
4. 算法细节
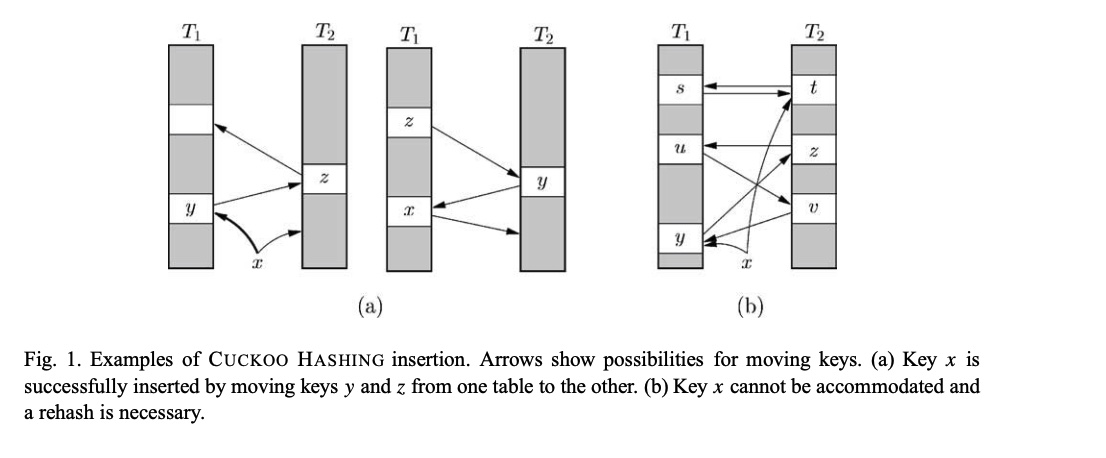
图(a)解析:想插入元素x,用哈希函数h1(x)计算出下标i1,发现巢穴中i1已经存在元素y,于是用x踢开y;y用哈希函数h2(x)计算出下一个下标,发现存在元素z,于是用y踢开z;z用哈希函数h1(x)计算出下一个下标,填充进去,算法结束。
注意:在T1的元素发生哈希冲突时,用h2(x)去计算下一个下标、在T2的元素发生哈希冲突时,用h1(x)去计算下一个下标。
图(b)解析:想插入元素x,x踢出y,y踢出z,z踢出u,u踢出v,v踢出x,形成死循环,在T1插入失败;转而在T2插入,x踢出t,t踢出s,s踢出x,形成死循环,在T2插入失败,需要rehash。

Insert算法与上面的图(b)相比,在T1插入失败就会rehash,不会继续尝试往T2中插入;这属于实现细节问题,无需纠结。

5. 布谷鸟哈希表 vs 桶链式哈希表

6. 总结
cuckoo hashing适合空间需求量大,对读性能要求高,对写性能相对低,操作比例读为主写为辅的场景。理由是基于Cuckoo hashing的优点和缺点。
6.1 优点
哈希表本身的空间利用率高:当表宽为1(也就是只使用1个hash表)时,最大load factor(多少空间被利用)大概率能到50%;实验显示表宽大于4以后,load factor大概率能到95%
查询可以使用两次读完成:表宽不大的情况下,两次(可并行)的cacheline read就能完成一个查询。相比之下查询链式哈希表可能有多次pointer dereference,查询时间方差会大过cuckoo hashing
6.2 缺点
插入操作的复杂度大:当表接近其最大load factor时,会有很多次kick out操作才能完成一次插入
读写的高并发算法复杂:不像链式哈希表,每个bucket放一把读写锁就可以实现细粒度的读写并发,cuckoo hashing的写会涉及到多个且事先不预知的bucket,抢锁会复杂
参考资料: