Notes about GPUDirect Async family
文章目录
本文将mark下GPUDirect Async family技术的相关notes。
Prerequisite
GPUDirect Async Kernel-Initiated Network
Motivation
为了让GPU和网卡并行起来,CPU仍然扮演了厚重的调度角色,而且GPU空转时间比较长。
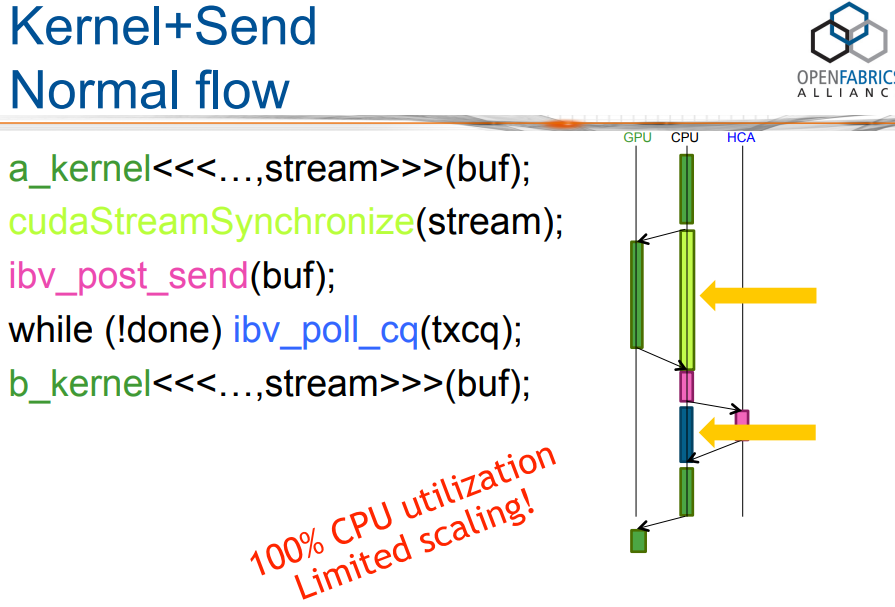
能否把控制面也offload一部分?于是乎GPUDirect Async Kernel-Initiated Network概念被提了出来。
GPUDirect Async Kernel-Initiated Network整体的逻辑如下:
GPUDirect Async Kernel-Initiated Network消除了CPU在通信控制路径中的作用。
Overview
The following is an example diagram of a CPU-centric approach: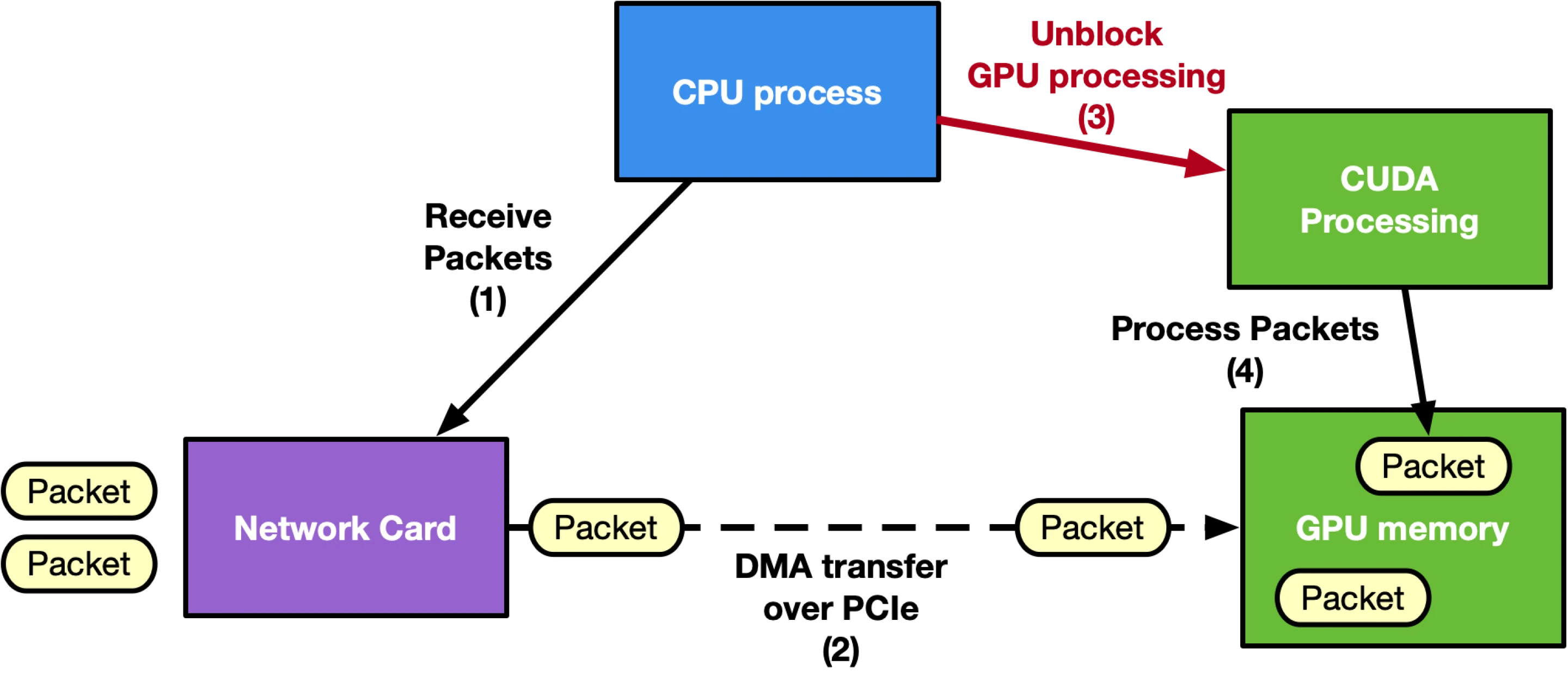
The following is an example diagram of a GPU-centric approach: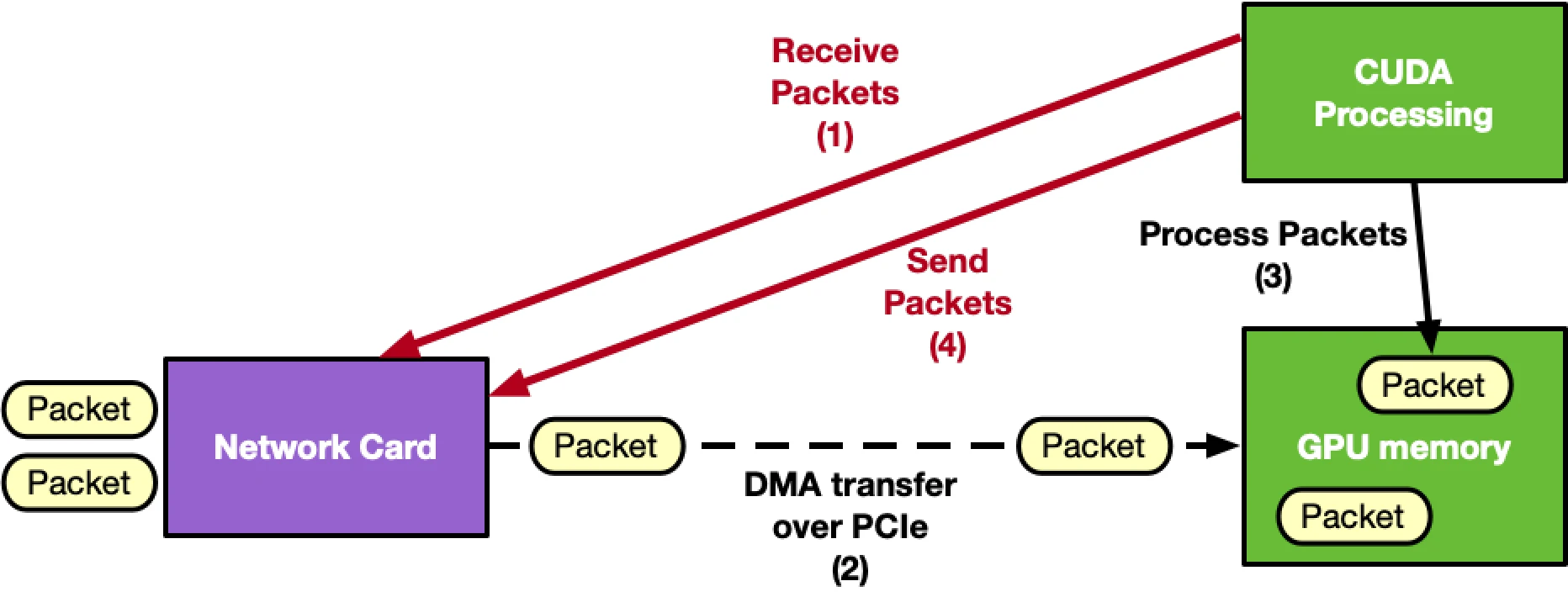
在此处,网卡既可以是RDMA网卡,也可以是Ethernet网卡。
总结

- 对于GDR,GPUDirect Async Kernel-Initiated Network可以offload critical控制路径到GPU中(也就是IBGDA)
- 对于GPU与Ethernet网卡的p2p,GPUDirect Async Kernel-Initiated Network可以offload critical控制路径到GPU中
GPUDirect Async Kernel Initiated Storage
BaM是首个以加速器为中心的方法,使GPU能够按需访问存储在内存或存储设备中的数据,而无需依赖CPU来发起或触发这些访问。
BaM架构
BaM的设计目标是为GPU线程提供高效的存储访问抽象,以便其能够按需、细粒度且高吞吐量地访问存储设备,同时提升存储访问性能。为此,如下图所示,BaM在GPU内存中配置了专门的存储I/O队列和缓冲区,并借助GPU的内存映射功能,将存储DB reg映射到GPU地址空间。
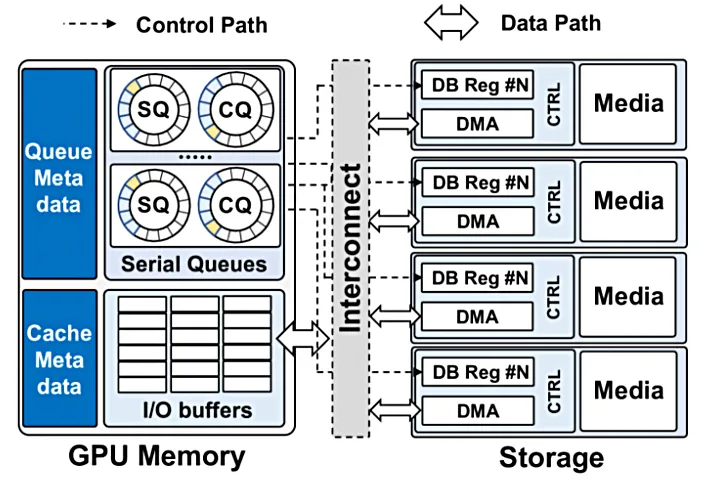
与传统GDS对比
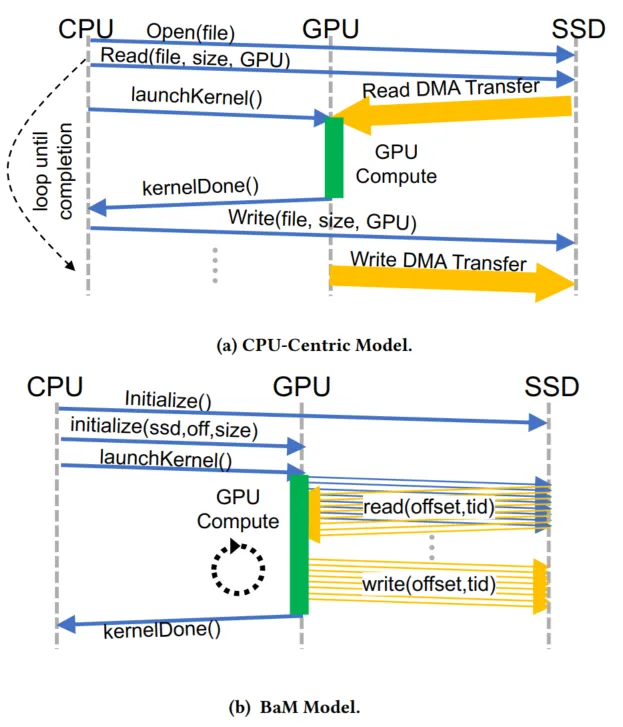
与传统的存储数据访问模式(GDS)相比,BaM带来了显著的变革,使GPU线程能够直接访问存储,从而实现了细粒度的计算与I/O重叠。这一设计理念带来了多方面的优势。
- 首先,减少CPU-GPU同步开销,以及GPU内核的启动频率,从而消除了每次数据访问时CPU的启动和调度需求。
- 其次,降低I/O放大开销,由于CPU调度通常以大块数据任务为单位,而非GPU实际所需的随机数据,BaM中GPU线程仅在需要时才获取,因此有效避免了IO放大问题。
- 最后,简化编程并隐藏延迟,过去,为了处理不同规模的数据,开发人员可能需要计算应用层面的复杂数据分块和分割策略;而Bam允许程序员通过数组抽象自然地访问数据,并利用GPU线程在大规模数据集上的并行性来隐藏存储访问延迟,从而简化了编程逻辑。
BaM与NVIDIA GDS的性能对比
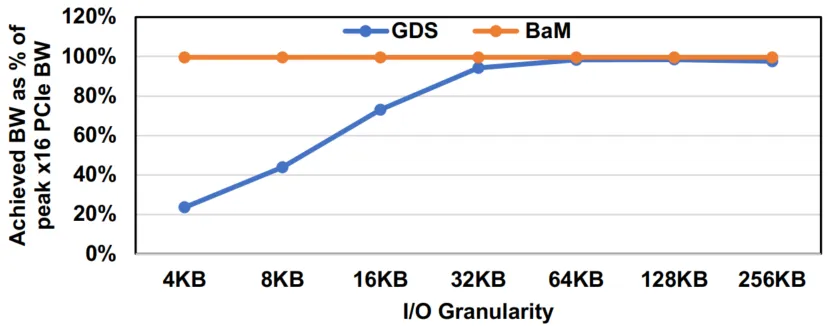
BaM与NVIDIA GDS的性能对比显示:当访问粒度小于32KB时,受传统 CPU 软件栈开销限制,GDS无法使PCIe接口饱和。相比之下,BaM 即使在4KB的I/O粒度下也能使接口饱和(约25GBps)。
总结
对于GDS,GPUDirect Async Kernel-Initiated Storage可以offload critical控制路径到GPU中
总结
GPU正朝着更高自主性和异步性的趋势发展。GPUDirect Async技术族在将数据从内存或存储直接移动到GPU内存时,可加速控制路径。
参考资料:
- OFVWG:GPUDirect and PeerDirect
- DOCA GPUNetIO
- gpu-direct
- GPU Direct相关技术和原理
- GPU-Initiated On-Demand High-Throughput Storage Access in the BaM System Architecture(ASPLOS’23)
- 使用 NVIDIA DOCA GPUNetIO 实现实时网络处理功能
- Does NCCL support DOCA GPUNetIO?
- GPUDirect Async: Exploring GPU synchronous communication techniques for InfiniBand clusters
- 【研究综述】浅谈GPU通信和PCIe P2P DMA