Notes about PIM and PNM
本文将mark下PIM(Processing-In-Memory)和PNM(Processing-Near-Memory)的相关notes。
Overview
PIM和PNM是两种用于突破“存储墙”瓶颈的计算架构,旨在通过将计算能力与内存紧密结合来提高计算效率,减少数据在处理器和内存之间的传输延迟和带宽瓶颈。
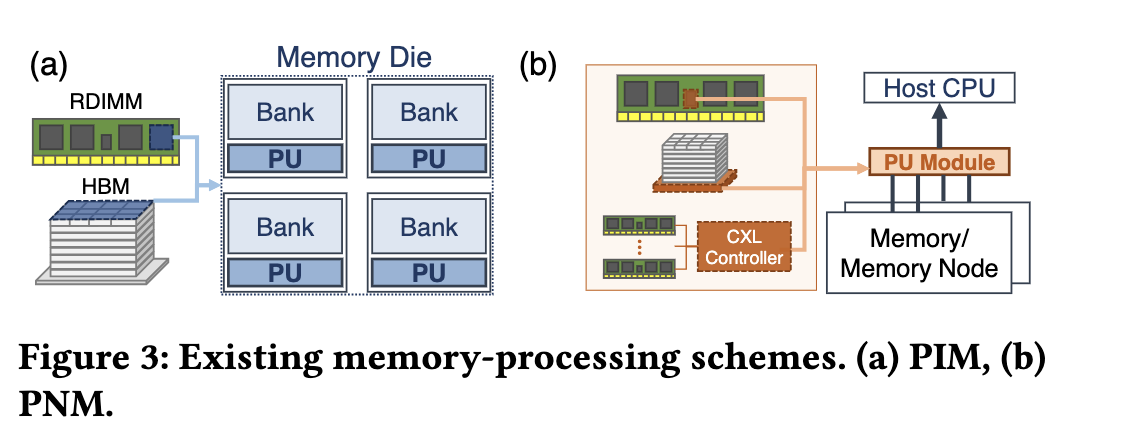
As shown in Figure 3 (a), PIM places a processing unit (PU) alongside each memory bank so that parallel computations can be implemented across all memory banks, exploiting the high internal memory bandwidth. A PU can be a MAC (Multiply and Accumulate) unit, a compute core, or a database query processor, specialized in workloads with low arithmetic intensity. However, due to the constraints stemming from the memory process technology applied for the memory core die, PIM logic faces inherent limitations in supporting more complex computations, thereby restricting it to wimpy processing units. On the other hand, as depicted in Figure 3 (b), PNM places processing modules not in the memory core but rather on the data read path between the host processor and the memory node or local main memory. Similar to PIM, PNM is also suitable for workloads with low arithmetic intensity. However, since PNM logic is fabricated using standard logic process nodes, it allows for a broader range of supported operations. Thus, one can fuse multiple kernels into a single module,and exploit high aggregate bandwidth for task-specific computations.
PIM(存内处理)
PIM是指将计算单元直接集成到内存芯片内部,使得数据可以在存储位置直接进行处理。通过这种方式,PIM减少了数据在处理器(如CPU、GPU)和内存之间的传输,降低了延迟和能耗。
优势:
- 高带宽利用:内存内的计算能够充分利用内存的高带宽优势,因为计算和数据都在内存内部完成。
- 低延迟:减少数据在内存和处理器之间的往返传输,降低整体延迟。
- 节能:通过减少数据移动,PIM能够显著降低系统能耗。
PNM(近存计算)
PNM是将计算单元放置在内存附近的芯片上,而不是直接集成在内存内部。虽然不如PIM直接在内存中处理数据,但PNM仍然通过将处理器靠近内存来减少数据传输的延迟。
相比于PIM,PNM可以在更广泛的硬件配置中实现,因为计算单元和内存是物理分开的,易于升级和扩展。
PIM vs PNM
- PIM (Processing-in-Memory, 存内计算): 计算逻辑和存储单元在同一个die上.
- PNM (Processing-Near-Memory, 近存计算): 计算逻辑和存储单元在不同但邻近的die上.
下表总结了PIM和PNM在数据中心LLM推理场景的对比:
| PIM | PNM | 胜出者 | |
|---|---|---|---|
| 数据移动功耗 | 非常低 (片上) | 低 (片外但邻近) | PIM |
| 带宽(每瓦) | 非常高 (标准的5-10倍) | 高 (标准的2-5倍) | PIM |
| 内存-逻辑耦合 | 内存和逻辑在同一个die上 | 内存和逻辑在分离的die上 | PNM |
| 逻辑PPA | 在DRAM工艺下逻辑更慢, 功耗更高 | 逻辑工艺有助于性能, 功耗和面积 | PNM |
| 内存密度 | 更差, 因为与逻辑共享面积 | 不受影响 | PNM |
| 商品化内存定价 | 否. 量小, 供应商少, 密度低 | 是. 不受影响 | PNM |
| 功耗/散热预算 | 逻辑在内存die上预算紧张 | 逻辑受限较小 | PNM |
| 软件分片 | 需要为内存bank (如32–64 MB) 分片 | 分片限制较小 (如16–32 GB) | PNM |
结论
针对数据中心LLM PNM优于PIM: 尽管PIM在理论带宽和功耗上更有优势, 但PNM在实际应用中更胜一筹.
- 软件分片(Sharding): PIM要求将数据切分到极小的内存bank(如32-64MB), 这对于LLM复杂的内存结构来说非常困难. PNM的分片粒度可以大得多(如16-32GB), 易于实现.
- 逻辑PPA (性能, 功耗, 面积): PNM的计算逻辑可以使用先进的逻辑工艺制造, PPA更优. 而PIM的计算逻辑受限于DRAM工艺, 性能较差, 功耗较高.
- 内存密度与成本: PNM不影响标准内存的密度和商品化定价.
- 功耗/散热预算: PIM中计算逻辑的功耗和散热受到DRAM die的严格限制.
参考资料:
- 大语言模型推理硬件的挑战与研究方向
- 科普专栏|PIM PNM对OpenAI O1有多么重要?
- Accelerating Retrieval Augmented Language Model via PIM and PNM Integration(MICRO’25)
- PIM Is All You Need: A CXL-Enabled GPU-Free System for Large Language Model Inference
- Processing-Near-Memory Systems: Developments fro Academia & Industry
- deepseek对话