Notes about Fuse over io-uring
文章目录
本文将mark下Fuse over io-uring的相关notes。
Prerequisite
背景
fast’24 paper:RFUSE: Modernizing Userspace Filesystem Framework through Scalable Kernel-Userspace Communication
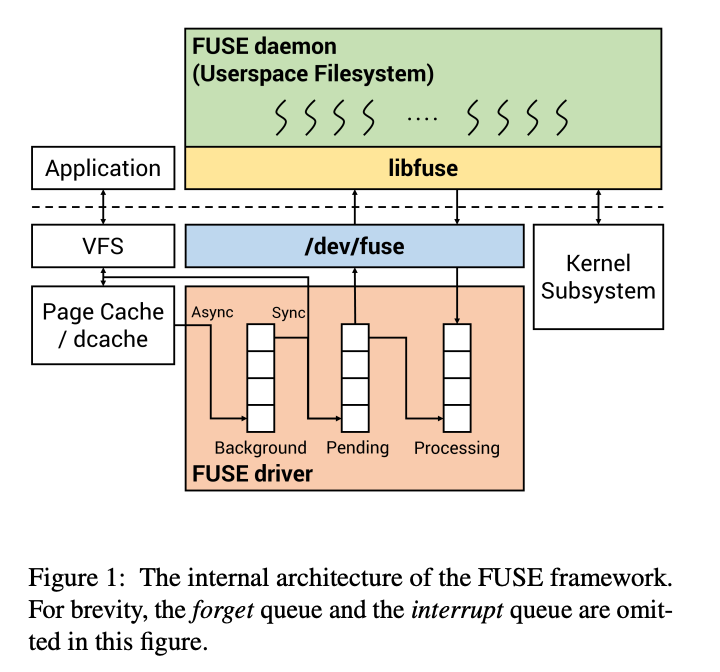
FUSE性能瓶颈:
- FUSE在内核和用户空间以及内存复制开销之间进行了多次上下文切换
- FUSE驱动程序在向用户空间FUSE守护进程调度文件系统请求时,使用单个队列阻碍了FUSE实现可伸缩性能
Motivation
Motivation for these patches is all to increase fuse performance. In fuse-over-io-uring requests avoid core switching (application on core X, processing of fuse server on random core Y) and use shared memory between kernel and userspace to transfer data.
Fuse over io-uring vs RFUSE
Fuse over io-uring与论文RFUSE的大方向高度一致,但实现路线不同、细节有差异;可以把 FUSE-over-io_uring 看作 RFUSE 思想在 Linux 内核里的工程化落地(io_uring 版)。
核心思想:高度一致
两者都针对传统 FUSE 的同一痛点:
- 单队列 + 锁竞争,多核下扩展性差
- 频繁上下文切换 + 内存拷贝,延迟高、CPU 开销大
共同核心思路:
- per-core 独立队列:每个核一个通道,无锁、并行处理
- 共享内存 / 环形缓冲区:内核↔用户态通过 ring 传递请求 / 响应,减少系统调用与拷贝
- 兼容现有 FUSE:用户态文件系统不用改代码即可提速
关键差异:实现方案不同
- RFUSE(FAST’24 论文)
- 自研 类 io_uring 的 ring,不依赖内核 io_uring 子系统
- hybrid polling:短时间忙轮询 + 休眠,平衡延迟与 CPU
- 原型,未并入主线内核
- FUSE-over-io_uring(Linux 6.14 主线)
- 直接复用内核 io_uring 子系统,通过 IORING_OP_URING_CMD 扩展 FUSE
- per-core io_uring 队列,亲和性调度,减少核间迁移
- 用 io_uring 原生机制处理提交 / 完成 / 内存管理,不做自研 ring
- 已合入主线,生产可用
总结
思想同源、实现分叉:
- RFUSE:学术验证,提出 “per-core ring + 共享内存 + 兼容 FUSE” 的高性能通信范式
- FUSE-over-io_uring:工程实现,用标准io_uring把同一范式落地到 Linux 内核
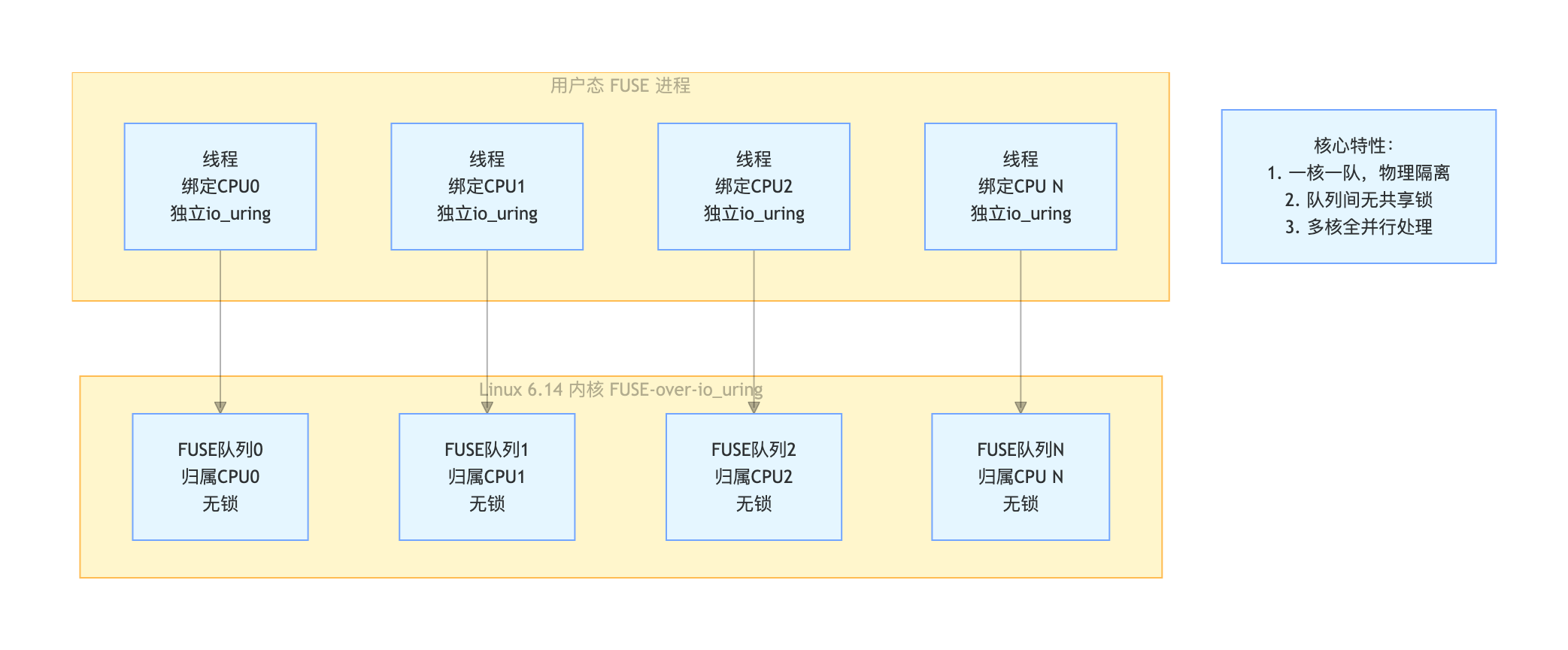
Fuse over io-uring per-core io_uring
内核文档:
在FUSE-over-io-uring design documentation可以看到:
Note, every CPU core has its own fuse-io-uring queue.
内核代码:
https://elixir.bootlin.com/linux/v6.14/source/fs/fuse/dev_uring.c#L182-L194
1 | static struct fuse_ring *fuse_uring_create(struct fuse_conn *fc) |
每个CPU对应一个独立的 struct fuse_ring_queue。
With fuse-over-io-uring requests are handled on the same core (sync requests)
同步请求始终在发起的同一个 CPU 上处理,cache 友好:数据留在本地 core,减少 bouncing。
参考资料: