To implement the kind of storage which stores strings as the search keys , there is a need to have special data structures which can store the strings efficiently and the searching of data based on the string keys is easier, efficient and faster. One such data structure is a tree based implementation called Trie.
Trie is a data structure which can be used to implement a dictionary kind of application. It provides all the functionality to insert a string, search a string and delete a string from the dictionary. The insertion and deletion operation takes O(n) time where n is the length of the string to be deleted or inserted. Some of the application of tries involve web based search engines, URL completion in autocomplete feature, Spell checker etc.
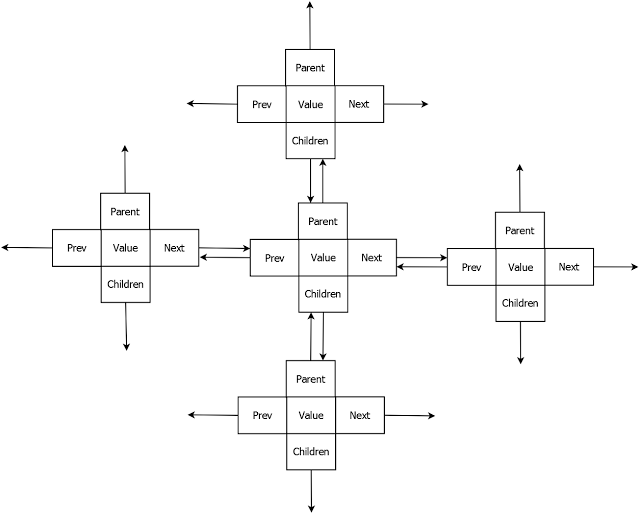
Structure of Trie(Specific to this implementation):
The trie implemented here consists of nodes. Each node has these fields:
Key - Part of the string to be serached,inserted or deleted.
Value - The value associated with a string (e.g In a dictionary it could be the meaning of the word which we are searching)
Neighbour node address - It consists of the address of the neighbouring node at the same level.
Previous neighbour address - It consists of the address of the previous node at the same level.
Children node address - It consists of the address of the child nodes of the current node.
Parent node address - It consists of the address of the parent node of the current node.
The additional nodes like Parent and Previous nodes are added to this implementation for making the search, and deletions easier.
Here is a diagrammatical view of a trie nodes I have used in this implementation. The field key is not represented in the diagram due to symmetry purposes.
Let us consider an example to understand tries in detail.
Suppose we have to implement a database for the HR department of an organisation in which we have to store an employee’s name and their ages. There is an assumption for this example that there each employee’s name is unique.So there is a strange policy in this organisation that any new employee which has a name that already exists in the organisation, it would not hire that new employee.
Let’s use this hypothetical example just to understand how tries work.
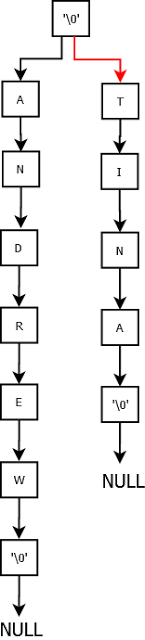
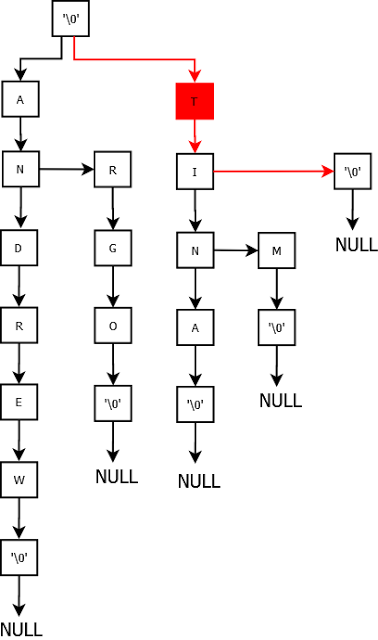
Consider we have a new employee named Andrew with age 36. Lets populate our trie for “andrew”.
Now add “tina”.
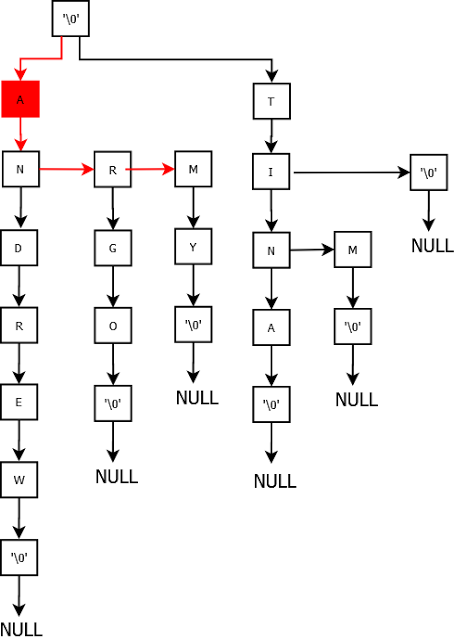
Add “argo”.
Add “tim”.
Add “t”.
Add “amy”.
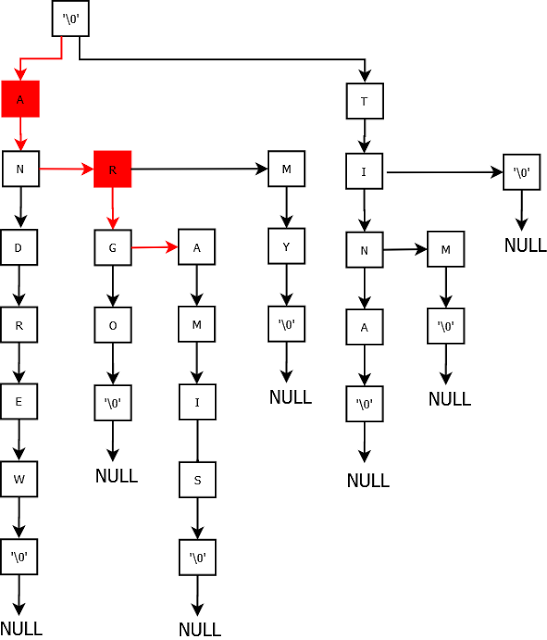
Add “aramis”.
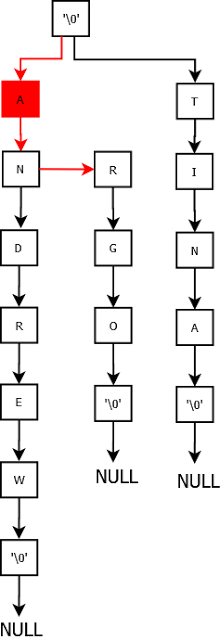
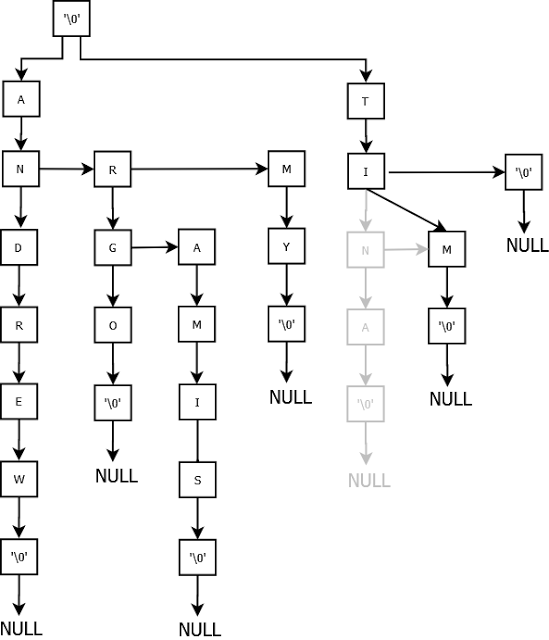
This is the complete Trie with all the entries. Now let us try deleting the names. I am not capturing the trivial cases.
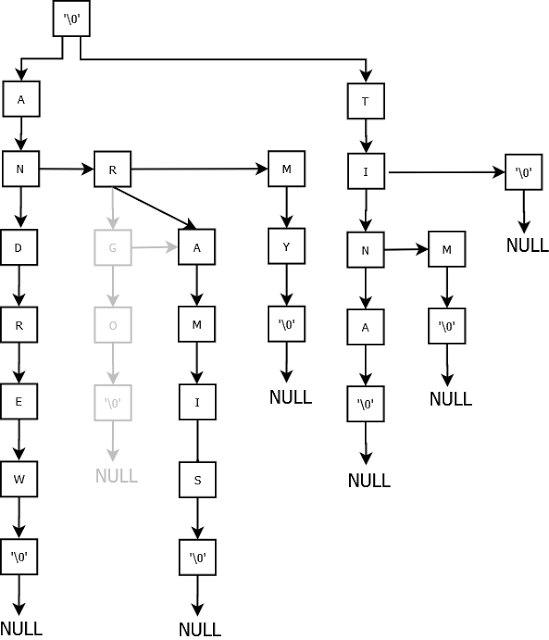
Lets try deleting Argo.
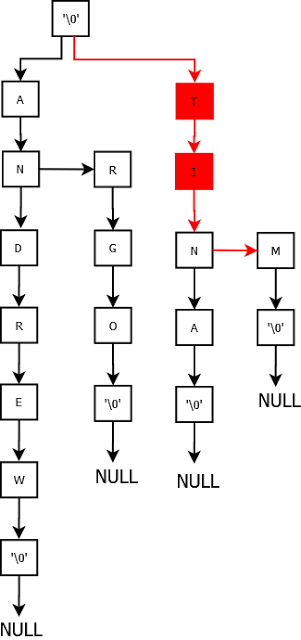
Delete Tina
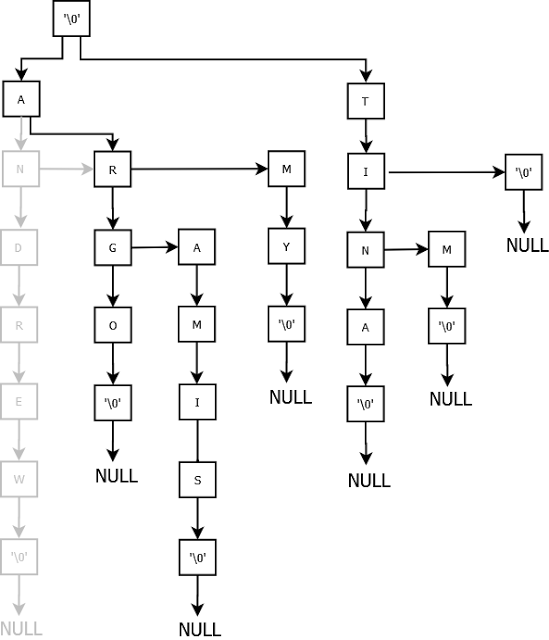
Delete Andrew
There is also a video from IIT Delhi which explains the tries. Tries Explained.
The implementation for this Trie is given below. Please provide your suggestions to further improve the implementation.