leveldb整体框架
文章目录
leveldb is an open source on-disk key-value store written by Google fellows Jeffrey Dean and Sanjay Ghemawat.
leveldb的特点和限制
特点
- key和value都是任意长度的字节数组
- Kev-value Pair默认是 按照key的字典顺序存储 ,当然开发者也可以重载这个排序函数
- 提供的基本操作接口:Put()、Delete()、Get()、Batch()
- 支持批量操作以原子操作进行(Batch操作)
- 可以创建数据全景的snapshot(快照),并允许在快照中查找数据
- 可以通过前向(或后向)迭代器遍历数据
- 自动使用Snappy(Snappyis a fast data compression and decompression library written in C++ by Google based on ideas from LZ77 and open-sourced in 2011)压缩数据
- 可移植性(使用的是c语言提供的库,而不是linux提供的库,如read,write等函数库)
限制
- 非关系型数据模型(NoSQL),不支持sql语句,也不支持索引
- 一次只允许一个进程(多线程)访问一个特定的数据库
- 没有内置的C/S架构,但开发者可以使用LevelDB库自己封装一个server
leveldb的框架
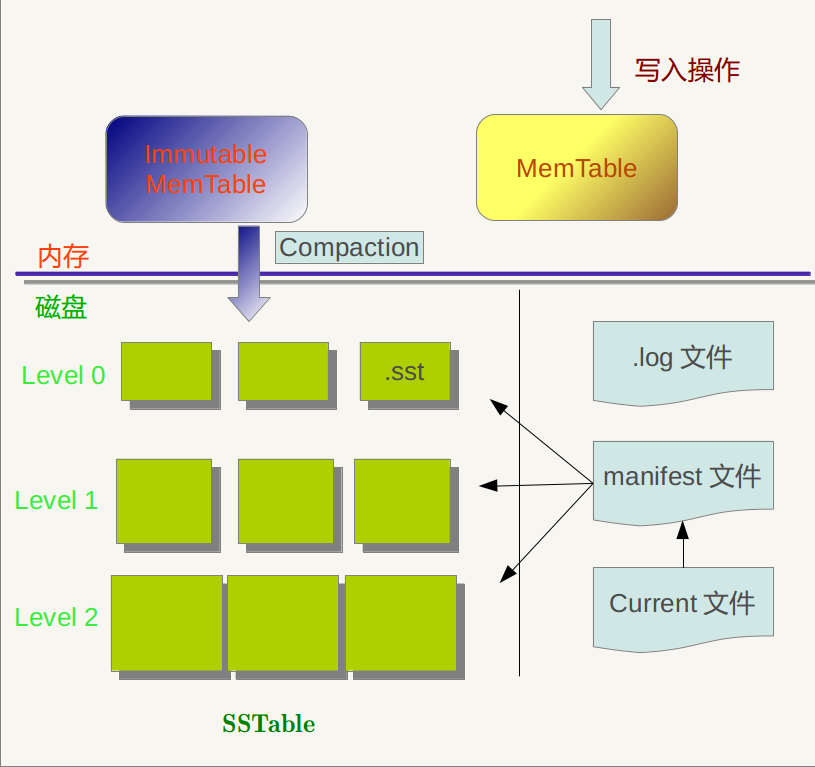
从图中可以看出,构成LevelDb静态结构的包括六个主要部分:内存中的MemTable和Immutable MemTable以及磁盘上的几种主要文件:Current文件,Manifest文件,log文件以及SSTable文件。当然,LevelDb除了这六个主要部分还有一些辅助的文件,但是以上六个文件和数据结构是LevelDb的主体构成元素。
从图中可以看出,构成LevelDb静态结构的包括六个主要部分:内存中的MemTable和Immutable MemTable以及磁盘上的几种主要文件:Current文件,Manifest文件,log文件以及SSTable文件。当然,LevelDb除了这六个主要部分还有一些辅助的文件,但是以上六个文件和数据结构是LevelDb的主体构成元素。
LevelDb的Log文件和Memtable与Bigtable论文中介绍的是一致的,当应用写入一条Key:Value记录的时候,LevelDb会先往log文件里写入,成功后将记录插进Memtable中,这样基本就算完成了写入操作,因为一次写入操作只涉及一次磁盘顺序写和一次内存写入,所以这是为何说LevelDb写入速度极快的主要原因。
Log文件在系统中的作用主要是用于系统崩溃恢复而不丢失数据,假如没有Log文件,因为写入的记录刚开始是保存在内存中的,此时如果系统崩溃,内存中的数据还没有来得及Dump到磁盘,所以会丢失数据(Redis就存在这个问题)。为了避免这种情况,LevelDb在写入内存前先将操作记录到Log文件中,然后再记入内存中,这样即使系统崩溃,也可以从Log文件中恢复内存中的Memtable,不会造成数据的丢失。
当Memtable插入的数据占用内存到了一个界限后,需要将内存的记录导出到外存文件中,LevleDb会生成新的Log文件和Memtable,原先的Memtable就成为Immutable Memtable,顾名思义,就是说这个Memtable的内容是不可更改的,只能读不能写入或者删除。新到来的数据被记入新的Log文件和Memtable,LevelDb后台调度会将Immutable Memtable的数据导出到磁盘,形成一个新的SSTable文件。SSTable就是由内存中的数据不断导出并进行Compaction操作后形成的,而且SSTable的所有文件是一种层级结构,第一层为Level 0,第二层为Level 1,依次类推,层级逐渐增高,这也是为何称之为LevelDb的原因。
SSTable中的文件是Key有序的,就是说在文件中小key记录排在大Key记录之前,各个Level的SSTable都是如此,但是这里需要注意的一点是:Level 0的SSTable文件(后缀为.sst)和其它Level的文件相比有特殊性:这个层级内的.sst文件,两个文件可能存在key重叠,比如有两个level 0的sst文件,文件A和文件B,文件A的key范围是:{bar, car},文件B的Key范围是{blue,samecity},那么很可能两个文件都存在key=”blood”的记录。对于其它Level的SSTable文件来说,则不会出现同一层级内.sst文件的key重叠现象,就是说Level L中任意两个.sst文件,那么可以保证它们的key值是不会重叠的。这点需要特别注意,后面您会看到很多操作的差异都是由于这个原因造成的。
SSTable中的某个文件属于特定层级,而且其存储的记录是key有序的,那么必然有文件中的最小key和最大key,这是非常重要的信息,LevelDb应该记下这些信息。Manifest就是干这个的,它记载了SSTable各个文件的管理信息,比如属于哪个Level,文件名称叫啥,最小key和最大key各自是多少。下图是Manifest所存储内容的示意:

图中只显示了两个文件(manifest会记载所有SSTable文件的这些信息),即Level 0的test.sst1和test.sst2文件,同时记载了这些文件各自对应的key范围,比如test.sstt1的key范围是“an”到 “banana”,而文件test.sst2的key范围是“baby”到“samecity”,可以看出两者的key范围是有重叠的。
Current文件是干什么的呢?这个文件的内容只有一个信息,就是记载当前的manifest文件名。因为在LevleDb的运行过程中,随着Compaction的进行,SSTable文件会发生变化,会有新的文件产生,老的文件被废弃,Manifest也会跟着反映这种变化,此时往往会新生成Manifest文件来记载这种变化,而Current则用来指出哪个Manifest文件才是我们关心的那个Manifest文件。
log文件
上节内容讲到log文件在LevelDb中的主要作用是系统故障恢复时,能够保证不会丢失数据。因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Memtable中的数据没有来得及Dump到磁盘的SSTable文件,LevelDB也可以根据log文件恢复内存的Memtable数据结构内容,不会造成系统丢失数据,在这点上LevelDb和Bigtable是一致的。
下面我们带大家看看log文件的具体物理和逻辑布局是怎样的,LevelDb对于一个log文件,会把它切割成以32K为单位的物理Block,每次读取的单位以一个Block作为基本读取单位,下图展示的log文件由3个Block构成,所以从物理布局来讲,一个log文件就是由连续的32K大小Block构成的。

在应用的视野里是看不到这些Block的,应用看到的是一系列的Key:Value对,在LevelDb内部,会将一个Key:Value对看做一条记录的数据,另外在这个数据前增加一个记录头,用来记载一些管理信息,以方便内部处理,下图显示了一个记录在LevelDb内部是如何表示的。

记录头包含三个字段,ChechSum是对“类型”和“数据”字段的校验码,为了避免处理不完整或者是被破坏的数据,当LevelDb读取记录数据时候会对数据进行校验,如果发现和存储的CheckSum相同,说明数据完整无破坏,可以继续后续流程。“记录长度”记载了数据的大小,“数据”则是上面讲的Key:Value数值对,“类型”字段则指出了每条记录的逻辑结构和log文件物理分块结构之间的关系,具体而言,主要有以下四种类型:FULL/FIRST/MIDDLE/LAST。
如果记录类型是FULL,代表了当前记录内容完整地存储在一个物理Block里,没有被不同的物理Block切割开;如果记录被相邻的物理Block切割开,则类型会是其他三种类型中的一种。我们以本节第一张图所示的例子来具体说明。
假设目前存在三条记录,Record A,Record B和Record C,其中Record A大小为10K,Record B 大小为80K,Record C大小为12K,那么其在log文件中的逻辑布局会如本节第一张图所示。Record A是图中蓝色区域所示,因为大小为10K<32K,能够放在一个物理Block中,所以其类型为FULL;Record B 大小为80K,而Block 1因为放入了Record A,所以还剩下22K,不足以放下Record B,所以在Block 1的剩余部分放入Record B的开头一部分,类型标识为FIRST,代表了是一个记录的起始部分;Record B还有58K没有存储,这些只能依次放在后续的物理Block里面,因为Block 2大小只有32K,仍然放不下Record B的剩余部分,所以Block 2全部用来放Record B,且标识类型为MIDDLE,意思是这是Record B中间一段数据;Record B剩下的部分可以完全放在Block 3中,类型标识为LAST,代表了这是Record B的末尾数据;图中黄色的Record C因为大小为12K,Block 3剩下的空间足以全部放下它,所以其类型标识为FULL。
从这个小例子可以看出逻辑记录和物理Block之间的关系,LevelDb一次物理读取为一个Block,然后根据类型情况拼接出逻辑记录,供后续流程处理。
SSTable文件
SSTable是Bigtable中至关重要的一块,对于LevelDb来说也是如此,对LevelDb的SSTable实现细节的了解也有助于了解Bigtable中一些实现细节。
本节内容主要讲述SSTable的静态布局结构,SSTable文件形成了不同Level的层级结构。本节主要介绍SSTable某个文件的物理布局和逻辑布局结构,这对了解LevelDb的运行过程很有帮助。
sst文件的分块结构
LevelDb不同层级有很多SSTable文件(以后缀.sst为特征),所有.sst文件内部布局都是一样的。上节介绍Log文件是物理分块的,SSTable也一样会将文件划分为固定大小的物理存储块,但是两者逻辑布局大不相同,根本原因是:Log文件中的记录是Key无序的,即先后记录的key大小没有明确大小关系,而.sst文件内部则是根据记录的Key由小到大排列的,从下面介绍的SSTable布局可以体会到Key有序是为何如此设计.sst文件结构的关键。
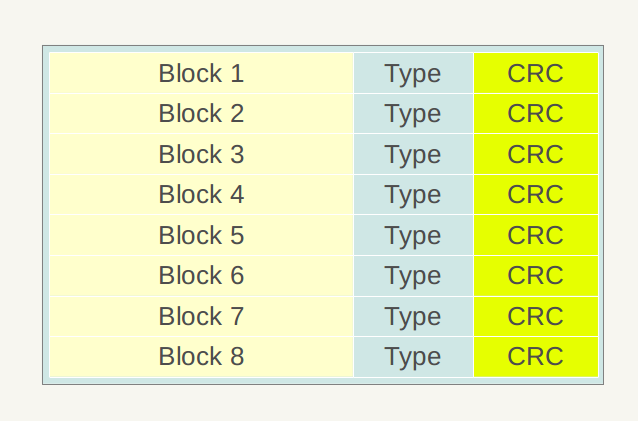
上图展示了一个.sst文件的物理划分结构,同Log文件一样,也是划分为固定大小的存储块,每个Block分为三个部分,红色部分是数据存储区, 蓝色的Type区用于标识数据存储区是否采用了数据压缩算法(Snappy压缩或者无压缩两种),CRC部分则是数据校验码,用于判别数据是否在生成和传输中出错。
sst文件的逻辑布局
以上是.sst的物理布局,下面介绍.sst文件的逻辑布局,所谓逻辑布局,就是说尽管大家都是物理块,但是每一块存储什么内容,内部又有什么结构等。下图展示了.sst文件的内部逻辑解释。
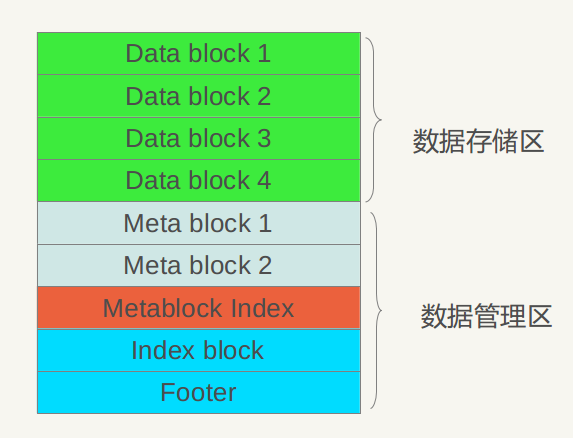
从上可以看出,从大的方面,可以将.sst文件划分为数据存储区和数据管理区,数据存储区存放实际的Key:Value数据,数据管理区则提供一些索引指针等管理数据,目的是更快速便捷的查找相应的记录。两个区域都是在上述的分块基础上的,就是说文件的前面若干块实际存储KV数据,后面数据管理区存储管理数据。管理数据又分为四种不同类型:紫色的Meta Block,红色的MetaBlock 索引和蓝色的数据索引块以及一个文件尾部块。
数据索引区
Meta Block涉及到bloomfilter,本节不做介绍,下面我们看看数据索引区和文件尾部Footer的内部结构。
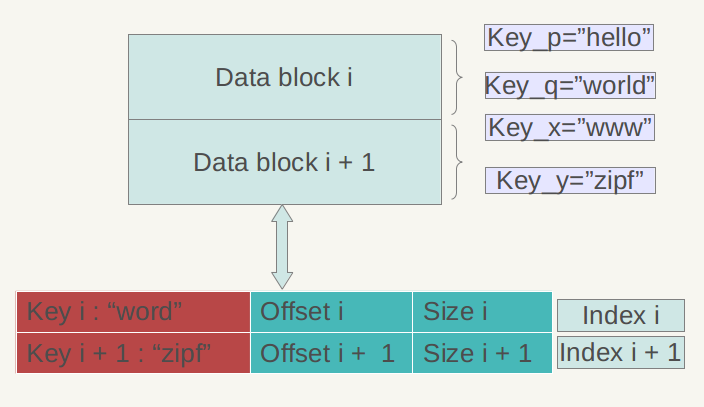
上图是数据索引的内部结构示意图。再次强调一下,Data Block内的KV记录是按照Key由小到大排列的,数据索引区的每条记录是对某个Data Block建立的索引信息,每条索引信息包含三个内容,以上图所示的数据块i的索引Index i来说:红色部分的第一个字段记载大于等于数据块i中最大的Key值的那个Key,第二个字段指出数据块i在.sst文件中的起始位置,第三个字段指出Data Block i的大小(有时候是有数据压缩的)。后面两个字段好理解,是用于定位数据块在文件中的位置的,第一个字段需要详细解释一下,在索引里保存的这个Key值未必一定是某条记录的Key,以上图的例子来说,假设数据块i 的最小Key=“samecity”,最大Key=“the best”;数据块i+1的最小Key=“the fox”,最大Key=“zoo”,那么对于数据块i的索引Index i来说,其第一个字段记载大于等于数据块i的最大Key(“the best”)同时要小于数据块i+1的最小Key(“the fox”),所以例子中Index i的第一个字段是:“the c”,这个是满足要求的;而Index i+1的第一个字段则是“zoo”,即数据块i+1的最大Key。
文件尾部Footer
文件末尾Footer块的内部结构见下图,metaindex_handle指出了metaindex block的起始位置和大小;inex_handle指出了index Block的起始地址和大小;这两个字段可以理解为索引的索引,是为了正确读出索引值而设立的,后面跟着一个填充区和魔数。

数据Block内部结构
上面主要介绍的是数据管理区的内部结构,下面我们看看数据区的一个Block的数据部分内部是如何布局的,下图是其内部布局示意图。
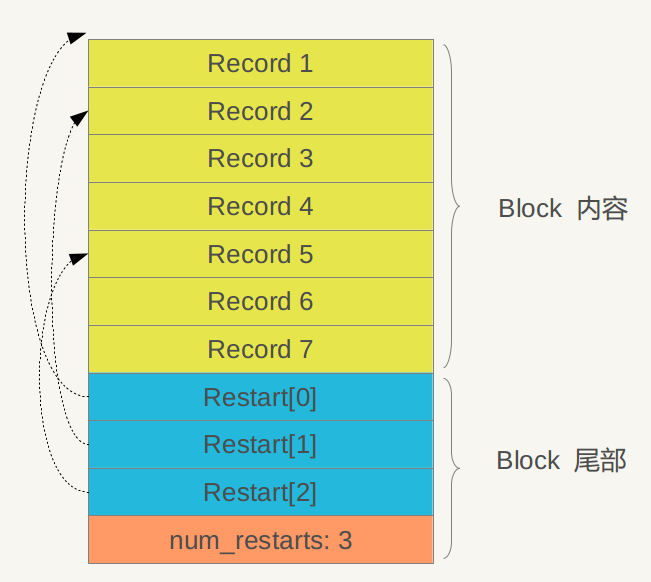
从图中可以看出,其内部也分为两个部分,前面是一个个KV记录,其顺序是根据Key值由小到大排列的,在Block尾部则是一些“重启点”(Restart Point),其实是一些指针,指出Block内容中的一些记录位置。
- 压缩规则
- 一个restart-point对应一个前缀压缩组
- 一个key和上一个key公共前缀长度>0,则key放入相同前缀压缩组
- 一个key和上一个key公共前缀长度=0,则新建一个前缀压缩组
- 查找规则
- 多个前缀压缩组之间二分查找
- 前缀压缩组内线性查找
“重启点”是干什么的呢?我们一再强调,Block内容里的KV记录是按照Key大小有序的,这样的话,相邻的两条记录很可能Key部分存在重叠,比如key i=“the Car”,Key i+1=“the color”,那么两者存在重叠部分“the c”,为了减少Key的存储量,Key i+1可以只存储和上一条Key不同的部分“olor”,两者的共同部分从Key i中可以获得。记录的Key在Block内容部分就是这么存储的,主要目的是减少存储开销。“重启点”的意思是:在这条记录开始,不再采取只记载不同的Key部分,而是重新点记录所有的Key值,假设Key i+1是一个重启点,那么Key里面会完整存储“the color”,而不是采用简略的“olor”方式。Block尾部就是指出哪些记录是这些重启点的。

在Block内容区,每个KV记录的内部结构是怎样的?上图给出了其详细结构,每个记录包含5个字段:key共享长度,比如上面的“olor”记录, 其key和上一条记录共享的Key部分长度是“the c”的长度,即5;key非共享长度,对于“olor”来说,是4;value长度指出Key:Value中Value的长度,在后面的Value内容字段中存储实际的Value值;而key非共享内容则实际存储“olor”这个Key字符串。
MemTable详解
本小节讲述内存中的数据结构Memtable,Memtable在整个体系中的重要地位也不言而喻。总体而言,所有KV数据都是存储在Memtable,Immutable Memtable和SSTable中的,Immutable Memtable从结构上讲和Memtable是完全一样的,区别仅仅在于其是只读的,不允许写入操作,而Memtable则是允许写入和读取的。当Memtable写入的数据占用内存到达指定数量,则自动转换为Immutable Memtable,等待Dump到磁盘中,系统会自动生成新的Memtable供写操作写入新数据,理解了Memtable,那么Immutable Memtable自然不在话下。
LevelDb的MemTable提供了将KV数据写入,删除以及读取KV记录的操作接口,但是事实上Memtable并不存在真正的删除操作,删除某个Key的Value在Memtable内是作为插入一条记录实施的,但是会打上一个Key的删除标记,真正的删除操作是Lazy的,会在以后的Compaction过程中去掉这个KV。
需要注意的是,LevelDb的Memtable中KV对是根据Key大小有序存储的,在系统插入新的KV时,LevelDb要把这个KV插到合适的位置上以保持这种Key有序性。其实,LevelDb的Memtable类只是一个接口类,真正的操作是通过背后的SkipList来做的,包括插入操作和读取操作等,所以Memtable的核心数据结构是一个SkipList。
SkipList不仅是维护有序数据的一个简单实现,而且相比较平衡树来说,在插入数据的时候可以避免频繁的树节点调整操作,所以写入效率是很高的,LevelDb整体而言是个高写入系统,SkipList在其中应该也起到了很重要的作用。Redis为了加快插入操作,也使用了SkipList来作为内部实现数据结构。
参考资料: