spark源码环境搭建
文章目录
预备条件
安装jdk,scala
IDEA搭建安装
如何在 Ubuntu Linux 上安装 IntelliJ IDEA
配置ssh localhost
安装hadoop
spark编译环境配置
使用Maven编译源码
unutu上安装maven:sudo apt-get install maven
1. 下载spark源码
访问spark下载页,选择下载Source Code,如下图所示。下载完成后解压缩下载好的资源包。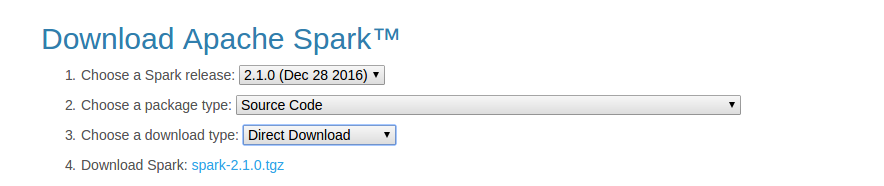
2. 设置maven内存限制
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
3. 编译源码
在spark源码目录下执行如下指令:./build/mvn -Pyarn -Phadoop-2.4 -Dhadoop.version=2.4.0 -DskipTests clean package
编译完成后的结果如下图所示: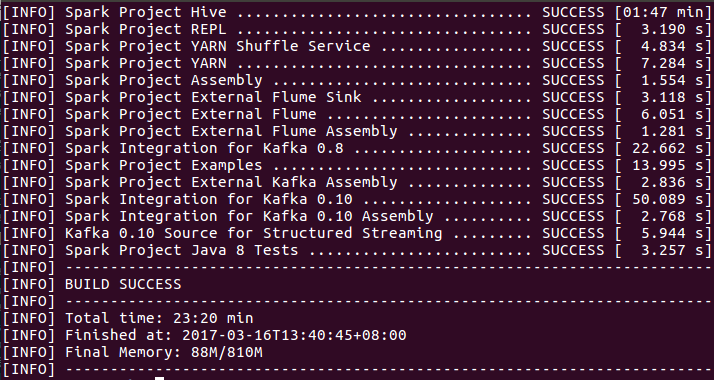
使用IDEA搭建源码编译与阅读环境
1. IntelliJ IDEA 安装 Scala 插件
依次选择 File -> Setting -> Plugins。搜索框输入 scala,右侧点击 Install Plugin,安装成功后重启 IntelliJ IDEA。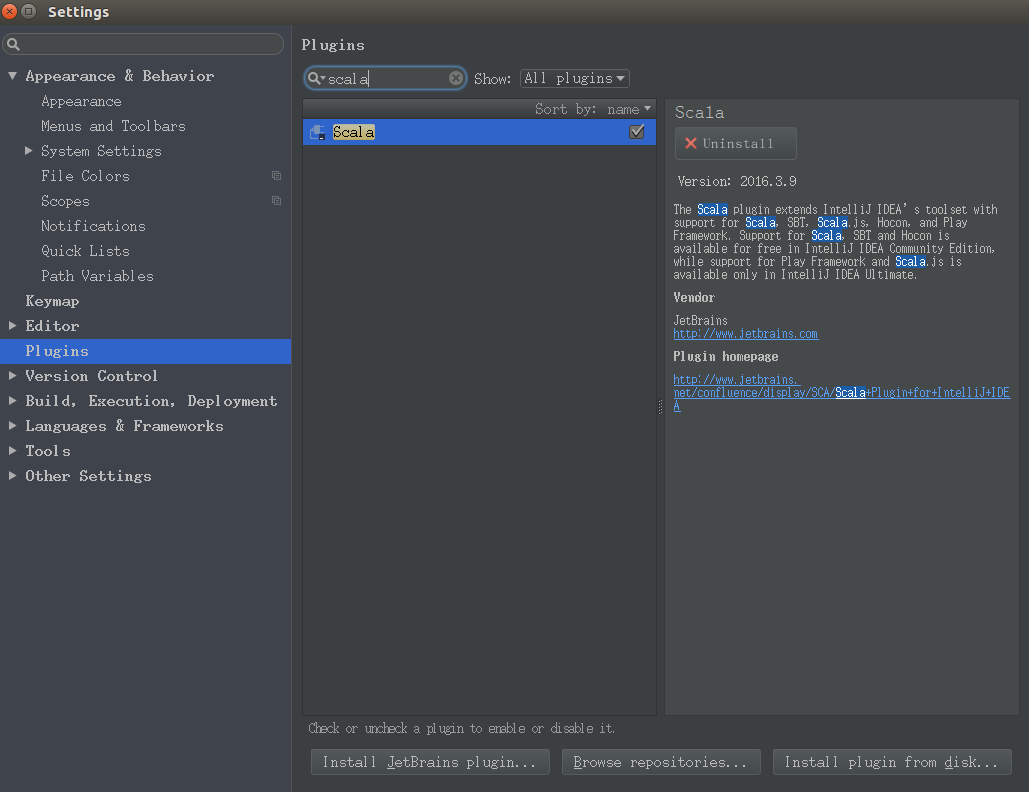
2. 导入spark项目
依次选择File -> open,在弹出的窗口中选择之前构建好的spark源码目录。
项目读取完毕之后,如果直接构建源码,IDEA会报出许多错误。
3. 构建spark项目
需要进行一些额外配置。
选择File -> Project Structure,依次打开Modules -> spark-streaming-flume-sink.2.11,右键 target 目录,取消 Excluded 标签。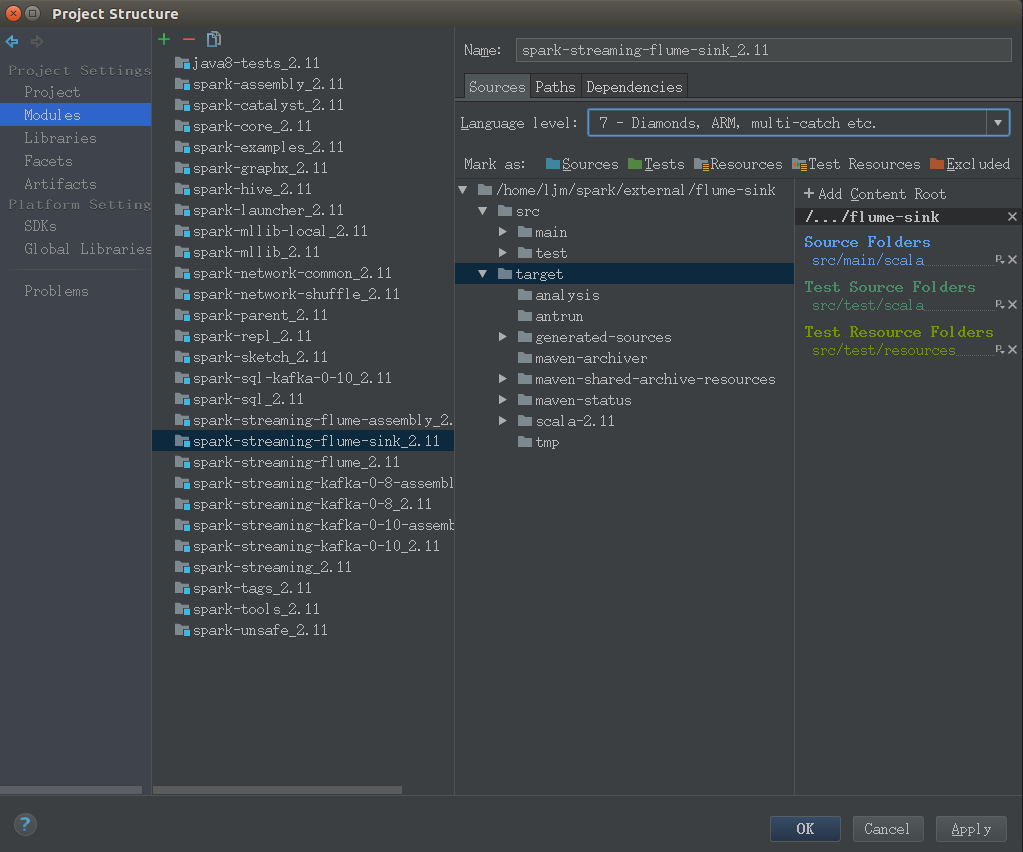
展开到 target -> scala-2.11 -> src_managed -> main -> compiled_avro 目录,右键,标记为 Source 目录。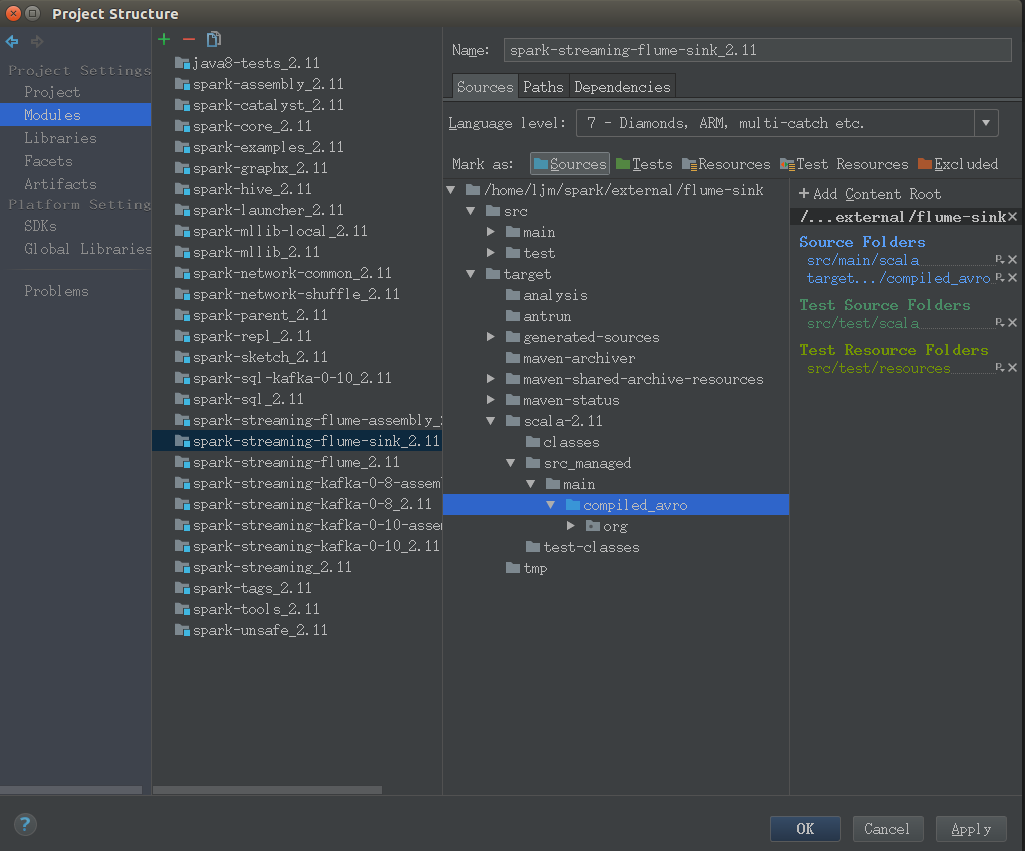
依次选择Build -> Rebuild Project,之后等待项目构建完毕即可,如下图: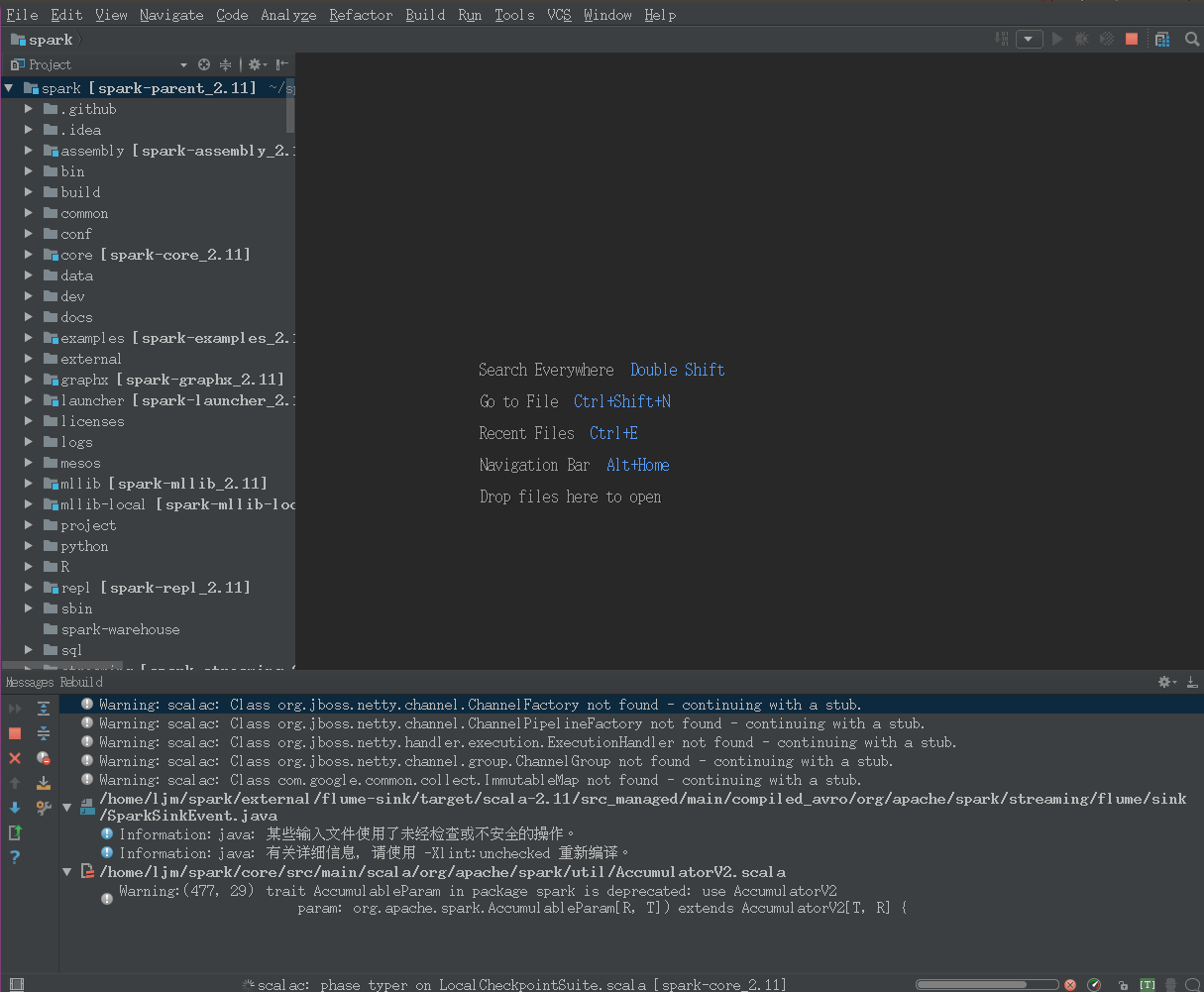
运行spark
设置环境变量
在/etc/profile文件的末尾添加环境变量:export SPARK_HOME=/home/ljm/sparkexport PATH=$SPARK_HOME/bin:$PATH
保存并更新/etc/profile:source /etc/profile
在conf目录下复制并重命名spark-env.sh.template为spark-env.sh:cp spark-env.sh.template spark-env.sh
在spark-env.sh中添加:export JAVA_HOME=/home/ljm/jdk/export SCALA_HOME=/home/ljm//scalaexport SPARK_MASTER_IP=localhostexport SPARK_WORKER_MEMORY=4G
在任意目录下执行指令spark-shell --help,若没有提示命令找不到,则说明设置成功。
运行测试应用
测试Spark是否安装成功:$SPARK_HOME/bin/run-example SparkPi

从途中可以观察到输出Pi is roughly 3.142355711778559,表明spark安装成功。
交互式scala shell
配置完环境变量之后输入:spark-shell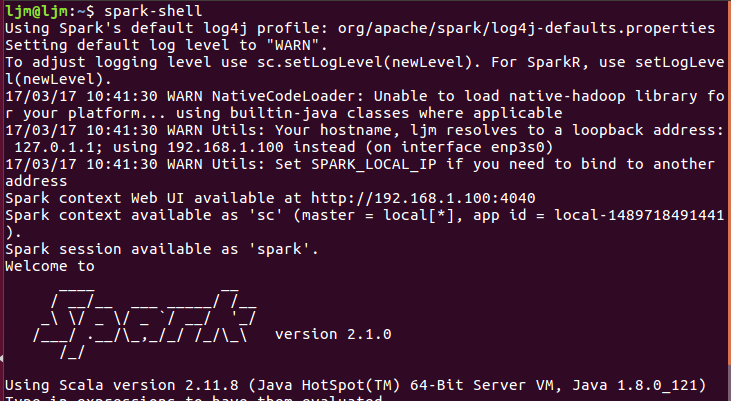
输入下面的指令,结果会返回1000sc.parallelize(1 to 1000).count()
运行与关闭集群
启动集群上的所有节点:$SPARK_HOME/sbin/start-all.sh
检查WebUI,浏览器打开端口:http://localhost:8080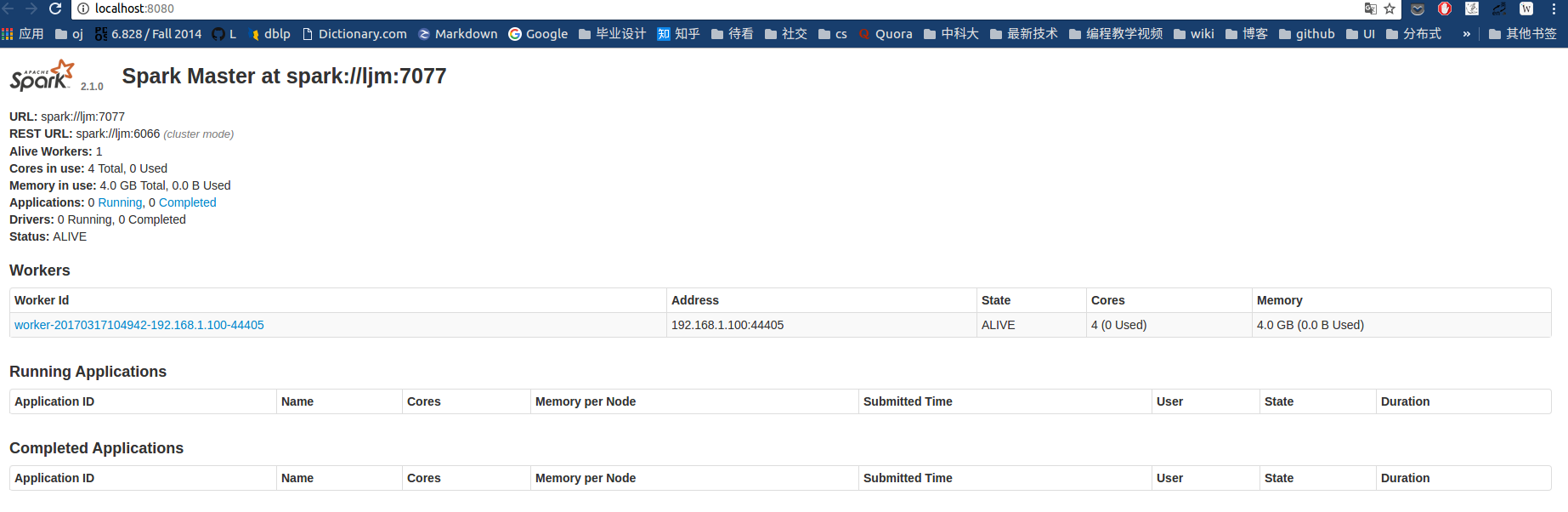
关闭正在运行的所有节点:$SPARK_HOME/sbin/stop-all.sh
修改源码后重新编译即可
./build/mvn -Pyarn -Phadoop-2.4 -Dhadoop.version=2.4.0 -DskipTests clean package
参考资料: