Linux内核读文件过程
文章目录
本篇博客使用的内核版本为linux 3.12.73。
Linux内核读文件过程
概述
用户程序想要访问IO设备需要调用操作系统提供的接口,即系统调用.当在用户程序中调用一个read操作时,系统先保存好read操作的参数,然后调用int 80命令(也可能是sysenter)进入内核空间,在内核空间中,读操作的逻辑由sys_read函数实现.
在讲sys_read的实现过程之前,我们先来看看read操作在内核空间需要经历的层次结构.从图中可以看出,read操作首先经过虚拟文件系统层(vfs), 接下来是具体的文件系统层,Page cache层,通用块层(generic block layer),I/O调度层(I/O scheduler layer),块设备驱动层(block device driver layer),最后是块物理设备层(block device layer).
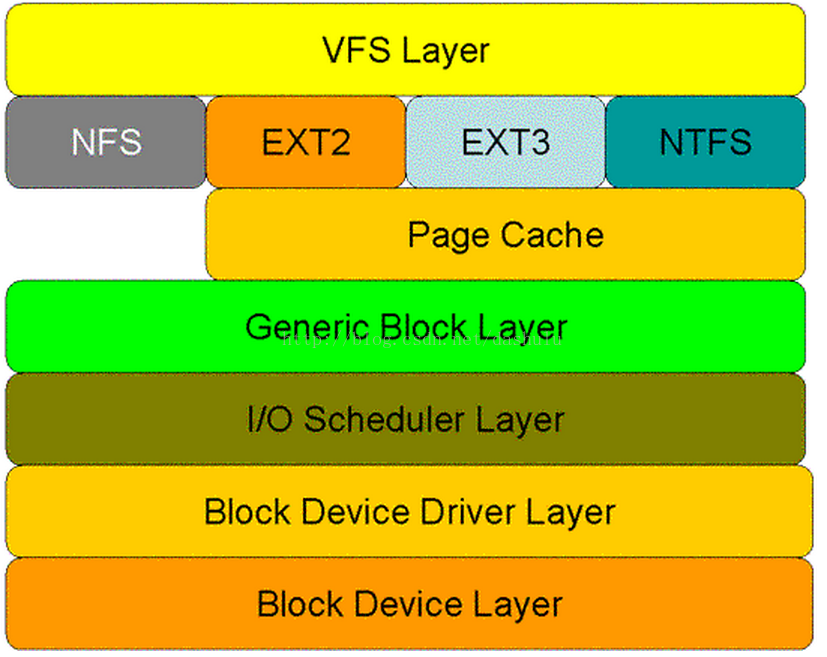
- 虚拟文件系统层:该层屏蔽了下层的具体操作,为上层提供统一的接口,如vfs_read,vfs_write等.vfs_read,vfs_write通过调用下层具体文件系统的接口来实现相应的功能.
- 具体文件系统层:该层针对每一类文件系统都有相应的操作和实现了,包含了具体文件系统的处理逻辑.
- page cache层:该层缓存了从块设备中获取的数据.引入该层的目的是避免频繁的块设备访问,如果在page cache中已经缓存了I/O请求的数据,则可以将数据直接返回,无需访问块设备.
- 通用块层:接收上层的I/O请求,并最终发出I/O请求.该层向上层屏蔽了下层设备的特性.
- I/O调度层: 接收通用块层发出的 IO 请求,缓存请求并试图合并相邻的请求(如果这两个请求的数据在磁盘上是相邻的)。并根据设置好的调度算法,回调驱动层提供的请求处理函数,以处理具体的 IO 请求
- 块设备驱动层:从上层取出请求,并根据参数,操作具体的设备.
- 块设备层:真正的物理设备.
了解了内核层次的结构,让我们来看一下read操作的代码实现.
先给出函数调用图: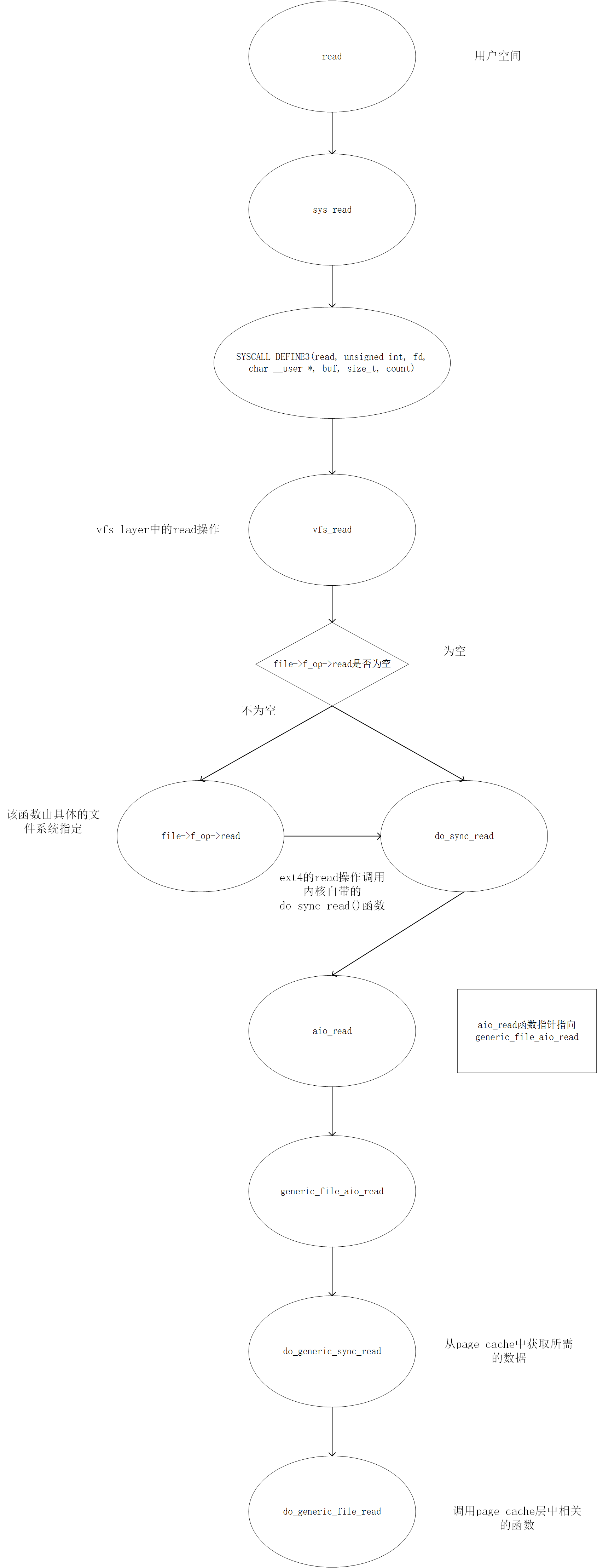
sys_read()
sys_read函数声明在include/linux/syscalls.h文件中,1
asmlinkage long sys_read(unsigned int fd, char __user *buf, size_t count);
其函数实现在fs/read write.c文件中:1
2
3
4
5
6
7
8
9
10
11
12
13
14SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file);
ret = vfs_read(f.file, buf, count, &pos);//调用vfs layer中的read操作
if (ret >= 0)
file_pos_write(f.file, pos);//设置当前文件的位置
fdput(f);
}
return ret;
}
vfs_read()
vfs_read函数属于vfs layer,定义在fs/read_write.c, 其主要功能是调用具体文件系统中对应的read操作,如果具体文件系统没有提供read操作,则使用默认的do_sync_read函数.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_READ))
return -EBADF;
if (!file->f_op || (!file->f_op->read && !file->f_op->aio_read))
return -EINVAL;
if (unlikely(!access_ok(VERIFY_WRITE, buf, count)))
return -EFAULT;
ret = rw_verify_area(READ, file, pos, count);
if (ret >= 0) {
count = ret;
if (file->f_op->read)
ret = file->f_op->read(file, buf, count, pos);//该函数由具体的文件系统指定
else
ret = do_sync_read(file, buf, count, pos);//内核默认的读文件操作
if (ret > 0) {
fsnotify_access(file);
add_rchar(current, ret);
}
inc_syscr(current);
}
return ret;
}
该函数的的4个参数;file是已打开文件的file结构,该结构是由fd而来;buf是用户空间的缓冲区,就是内核将读取到的数据拷贝到这里;count是将要读取的字节数;pos是文件当前读写位置。
do_sync_read()
file->f_op的类型为struct file_operations, 该类型定义了一系列涉及文件操作的函数指针,针对不同的文件系统,这些函数指针指向不同的实现.以ext4 文件系统为例子,该数据结构的初始化在fs/ext4/file.c,从该初始化可以知道,ext4的read操作调用了内核自带的do_sync_read()函数
1 | const struct file_operations ext4_file_operations = { |
do_sync_read()函数定义fs/read_write.c中,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23ssize_t do_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
struct iovec iov = { .iov_base = buf, .iov_len = len };
struct kiocb kiocb;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);//初始化kiocb,描述符kiocb是用来记录I/O操作的完成状态
kiocb.ki_pos = *ppos;
kiocb.ki_left = len;
kiocb.ki_nbytes = len;
for (;;) {
ret = filp->f_op->aio_read(&kiocb, &iov, 1, kiocb.ki_pos);//调用真正做读操作的函数,ext4文件系统在fs/ext4/file.c中配置
if (ret != -EIOCBRETRY)
break;
wait_on_retry_sync_kiocb(&kiocb);
}
if (-EIOCBQUEUED == ret)
ret = wait_on_sync_kiocb(&kiocb);
*ppos = kiocb.ki_pos;
return ret;
}
generic_file_aio_read()
在ext4文件系统中filp->f_op->aio_read函数指针指向generic_file_aio_read, 该函数定义于mm/filemap.c文件中,该函数有两个执行路径,如果是以O_DIRECT方式打开文件,则读操作跳过page cache直接去读取磁盘,否则调用do_generic_file_read函数尝试从page cache中获取所需的数据.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92ssize_t
generic_file_aio_read(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t pos)
{
struct file *filp = iocb->ki_filp;
ssize_t retval;
unsigned long seg = 0;
size_t count;
loff_t *ppos = &iocb->ki_pos;
count = 0;
retval = generic_segment_checks(iov, &nr_segs, &count, VERIFY_WRITE);
if (retval)
return retval;
/* coalesce the iovecs and go direct-to-BIO for O_DIRECT */
if (filp->f_flags & O_DIRECT) {
loff_t size;
struct address_space *mapping;
struct inode *inode;
struct timex txc;
do_gettimeofday(&(txc.time));
mapping = filp->f_mapping;
inode = mapping->host;
if (!count)
goto out; /* skip atime */
size = i_size_read(inode);
if (pos < size) {
retval = filemap_write_and_wait_range(mapping, pos,
pos + iov_length(iov, nr_segs) - 1);
if (!retval) {
retval = mapping->a_ops->direct_IO(READ, iocb,
iov, pos, nr_segs);
}
if (retval > 0) {
*ppos = pos + retval;
count -= retval;
}
/*
* Btrfs can have a short DIO read if we encounter
* compressed extents, so if there was an error, or if
* we've already read everything we wanted to, or if
* there was a short read because we hit EOF, go ahead
* and return. Otherwise fallthrough to buffered io for
* the rest of the read.
*/
if (retval < 0 || !count || *ppos >= size) {
file_accessed(filp);
goto out;
}
}
}
count = retval;
for (seg = 0; seg < nr_segs; seg++) {
read_descriptor_t desc;
loff_t offset = 0;
/*
* If we did a short DIO read we need to skip the section of the
* iov that we've already read data into.
*/
if (count) {
if (count > iov[seg].iov_len) {
count -= iov[seg].iov_len;
continue;
}
offset = count;
count = 0;
}
desc.written = 0;
desc.arg.buf = iov[seg].iov_base + offset;
desc.count = iov[seg].iov_len - offset;
if (desc.count == 0)
continue;
desc.error = 0;
do_generic_file_read(filp, ppos, &desc, file_read_actor);
retval += desc.written;
if (desc.error) {
retval = retval ?: desc.error;
break;
}
if (desc.count > 0)
break;
}
out:
return retval;
}
do_generic_file_read()
do_generic_file_read定义在mm/filemap.c文件中,该函数调用page cache层中相关的函数.如果所需数据存在与page cache中,并且数据不是dirty的,则从page cache中直接获取数据返回.如果数据在page cache中不存在,或者数据是dirty的,则page cache会引发读磁盘的操作.该函数的读磁盘并不是简单的只读取所需数据的所在的block,而是会有一定的预读机制来提高cache的命中率,减少磁盘访问的次数.
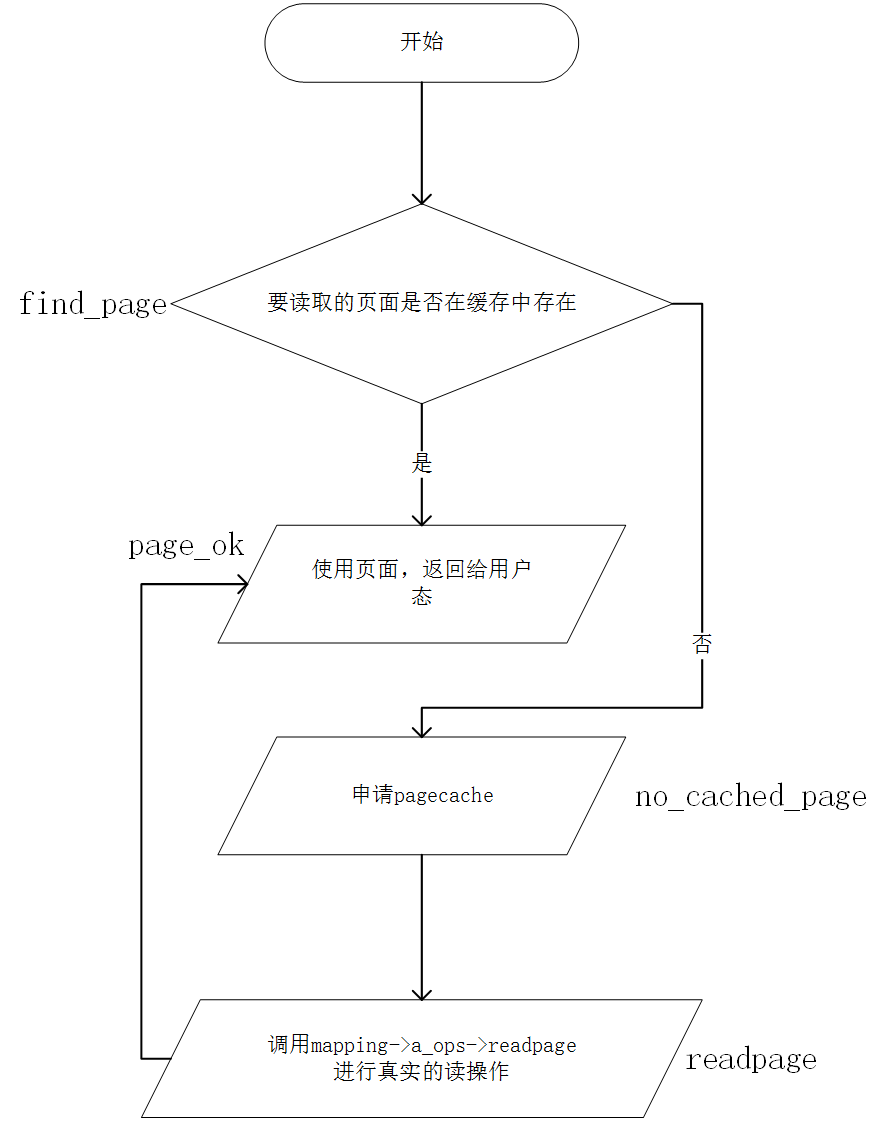
该函数是通用文件读例程,真正执行读操作,是通过mapping->a_ops->readpage()来完成。
do_mpage_readpage()
page cache层中真正读磁盘的操作为readpage系列,readpage系列函数具体指向的函数实现在fs/ext4/inode.c文件中定义,该文件中有很多个struct address_space_operation对象来对应于不同日志机制,我们选择linux默认的ordered模式的日志机制来描述I/O的整个流程, ordered模式对应的readpage系列函数如下所示.
1 | static const struct address_space_operations ext4_aops = { |
为简化流程,我们选取最简单的ext4_readpage函数来说明,该函数实现位于fs/ext4/inode.c中,函数很简单,只是调用了mpage_readpage函数.mpage_readpage位于fs/mpage.c文件中,该函数生成一个IO请求,并提交给Generic block layer.
1 | int mpage_readpage(struct page *page, get_block_t get_block) |
Generic block layer && I/O Scheduler
Generic block layer会将该请求分发到具体设备的IO队列中,由I/O Scheduler去调用具体的driver接口获取所需的数据.
参考资料: