CMD: Classification-based Memory Deduplication through Page Access Characteristics
CMD
此论文是VEE’14上的一篇文章,今天特意总结一下,希望对读者会有所帮助。
相关资料
问题
KSM需要对每个候选页在两个全局树中进行扫描,由于绝大多数页面都具有不同的内容,因此会导致大量无效的页面比较,从而导致沉重的开销。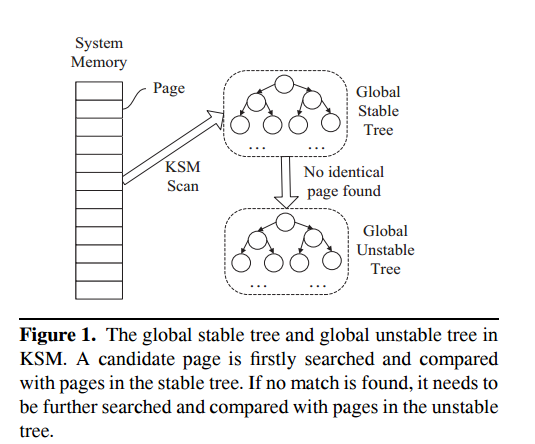
介绍
Futile Comparison指候选页在稳定树和不稳定树中未找到内容相同的页面。
本文的贡献点:
- 我们详细分析了KSM,发现页面内容的比较贡献了整个KSM运行时间的一部分(约44%),其中Futile Comparison贡献了大部分页面比较开销(约83%)。
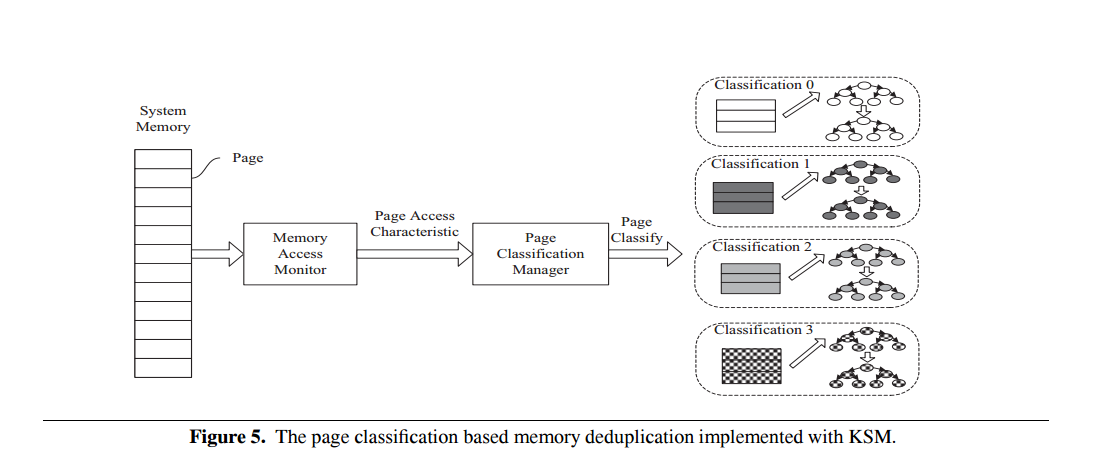
- 为了减少Futile Comparison的开销,同时有效地检测页面共享机会,我们提出了基于分类的轻量级内存重删方法CMD(Classification-based Memory Deduplication)。 在CMD中,根据页面访问特征将页面分组到不同的分类中,大型全局比较树分为多个小树,每个页分类中都有专门的本地比较树。页面比较只是在相同的分类中执行,不同分类的页面从不被比较(因为它们可能导致Futile Comparison)。
- 我们在真实系统中实现了CMD。 实验结果表明:与KSM相比,CMD可有效检测页面共享机会(超过98%),同时减少页面比较(约68.5%),Futile Comparison的比率也平均降低 了约12.15%。
设计
概要
页面分类需要满足以下两个条件:
- 相同内容概率较高的页面应分为相同的分类
- 页面分类方法需要平衡,这意味着每个页面分类中的页面节点数量应该几乎相同
page access 监视器
利用HMTT来更细粒度地检测页面的访问特征。
页分类
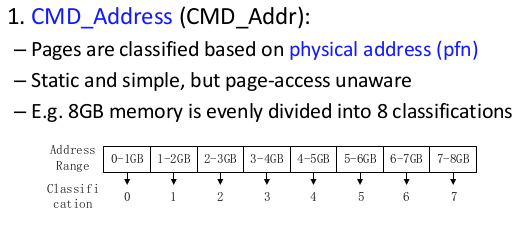
- CMD Address:页面按其物理地址进行静态分类
- CMD PageCount:内存访问监视器在每个扫描周期期间捕获每个页面的写入次数,并且页面按照其写入次数简单地分区。

- CMD Subpage Distribution:每个页面被分成多个子页面(例如4个1KB子页面),并且内存访问监视器维护所有子页面的写访问特性。 具有相同子页面访问分布的页面被分组到相同的分类中。

结论
根据页面的访问特征,CMD将原先KSM的全局树分为几个独立的子树,这样节省了页面内容比较开销与Futile Comparison比率,同时保证了与KSM相近的重删效果。