Linux中匿名页的反向映射
文章目录
vma, anon_vma和anon_vma_chain的联系
本文主要参考了vma, anon_vma和anon_vma_chain的联系这篇文章,结合相关资料,对该文进行了一些改进。
Linux提供了内存映射这一特性,它实现了把物理内存页映射(map)到进程的地址空间中, 以实现高效的数据操作或传输。内核在处理这一特性时, 使用了struct vm_area_struct, struct anon_vma和struct anon_vma_chain这三个重要数据结构, 所以理解这三个数据结构是重中之重, 本文试图厘清这三者的来历与联系。
vma
struct vm_area_struct在内核代码中常被简称为vma, 所以下文以vma指称这一结构。
vma是内存映射的单位, 它表示进程地址空间中的一个连续的区间, 其中字段vm_start和vm_end标明这块连续区间的起始虚拟地址。在使用mmap系统调用创建映射时, 用户指定起始地址(可选)和长度, 内核将据此寻找进程地址空间中符合条件的合法vma以供映射。cat /proc/<pid>/maps可以查看某一进程的所有映射区间。
anon_vma
anon_vma的引入需要一番解释。
反向映射的引入
当Linux系统内存不足时, swap子系统会释放一些页面, 交换到交换设备中, 以空出多余的内存页。虚拟内存的理念就是通过页表来维护虚拟地址到物理地址的映射。但是, 页表是种单向映射, 即通过虚拟地址查找物理地址很容易, 但反之通过物理地址查找虚拟地址则很麻烦。这种问题在共享内存的情况下更加严重。而swap子系统在释放页面时就遇到这个问题, 对于特定页面(物理地址), 要找到映射到它的页表项(PTE), 并修改PTE, 以使其指向交换设备中的该页的位置。在2.4之前的内核中, 这是件费时的工作, 因为内核需要遍历每一个进程的所有页表, 以找出所有映射该页的页表项。
解决这一问题的做法是引入**反向映射(reverse mapping)**这一概念。该做法就是为每一个内存页(struct page)维护一个数据结构, 其中包含所有映射到该页的PTE, 这样在寻找一个内存页的反向映射时只要扫描这个结构即可, 大大提高了效率。这正是Rik van Riel的做法, 他在struct page中增加了一个pte_chain的字段, 它是一个指向所有映射到该页的PTE的链表指针。
当然, 它是有代价的。
每个
struct page都增加了一个字段, 而系统中每个内存页都对应一个struct page结构, 这意味着相当数量的内存被用来维护这个字段。而struct page是重要的内核数据结构, 存放在有限的低端内存中, 增加一个字段浪费了大量的保贵低端内存, 而且, 当物理内存很大时, 这种情况更突出, 这引起了**伸缩性(scalability)**问题。其它一些需要操作大量页面的函数慢下来了。
fork()系统调用就是一个。由于Linux采取**写时复制(COW, Copy On Write)**的语义, 意味着新进程共享父进程的页表, 这样, 进程地址空间内的所有页都新增了一个PTE指向它, 因此, 需要为每个页新增一个反向映射, 这显著地拖慢了速度。
基于对象的反向映射
这种代价显然是不能容忍的, 于是, Dave McCracken提出了一个叫做**基于对象的反向映射(object-based reverse mapping)**的解决方案。他的观察是, 前面所述的代价来源于反向映射字段的引入, 而如果存在可以从struct page中获取映射到该页面的所有页表项, 这个字段就不需要了, 自然不需要付出这些代价。他确实找到了一种方法。
Linux的用户态内存页大致分两种使用情况:
其中一大部分叫做文件后备页(file-backed page), 顾名思义, 这种内存页的内容关联着后备存储系统中的文件, 比如程序的代码, 比如普通的文本文件, 这种内存页使用时一般通过上述的
mmap系统调用映射到地址空间中, 并且, 在内存紧张时, 可以简单地丢弃, 因为可以从后备文件中轻易的恢复。一种叫匿名页(anonymous page), 这是一种普通的内存页, 比如栈或堆内存就属于这种, 这种内存页没有后备文件, 这也是其称为匿名的缘故。
Dave的方案中的对象指的就是第一种内存页的后备文件。他通过后备文件对象, 以迂回的方式算出PTE,在本文中就不做过多的介绍。
匿名页的反向映射
Dave的方案只解决了第一种内存页的反向映射, 于是, Andrea Arcangeli顺着Dave的思路, 给出了匿名页的反向映射解决方案。
如前所述, 匿名页没有所谓的后备文件, 但是, 匿名页有个特点, 就是它们都是私有的, 而非共享的(比如栈, 椎内存都是独立每个进程的, 非共享的)。这意味着, 每一个匿名内存页, 只有一个PTE关联着它, 也就是只有一个vma关联着它。Andrea的方案是复用struct page的mapping字段, 因为对于匿名页, mapping为null, 不指向后备空间。复用方法是利用C语言的union, 在匿名页的情况下, mapping字段不是指向struct address_space的指针, 而是指向关联该内存页的唯一的vma。由此, 也可以方便地计算出PTE来。
但是, 事情并不是如此简单。当进程被fork复制时, 前面已经说过, 由于COW的语义, 新进程只是复制父进程的页表, 这意味着现在一个匿名页有两个页表指向它了, 这样, 上面的简单复用mapping字段的做法不适用了, 因为一个指针, 如何表示两个vma呢。
Andrea的做法就是多加一层。新创建一个struct anon_vma结构, 现在mapping字段是指向它了, 而anon_vma中, 不出意料的, 包含一个链表, 链接起所有的vma。每当进程fork一个子进程, 子进程由于COW机制会复制父进程的vma, 这个新vma就链接到父进程中的anon_vma中。这样, 每次unmap一个内存页时, 通过mapping字段指向的anon_vma, 就可以找到可能关联该页的vma链表, 遍历该链表, 就可以找到所有映射到该匿名页的PTE。
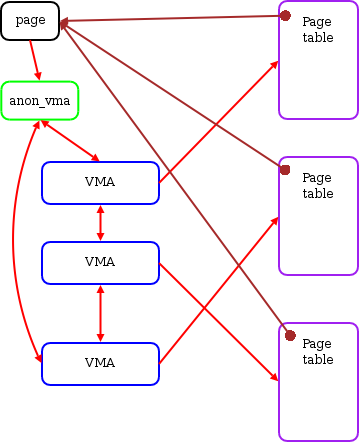
这也有代价, 那就是
- 每个
struct vm_area_struct结构多了一个list_head结构字段用以串起所有的vma。 - 需要额外为
anon_vma结构分配内存。
但是, 这种方案所需要的内存远小于前面所提的在每个struct page中增加一个反向映射字段来得少, 因此是可以接受的。
以上, 便介绍完了anon_vma结构的来由和作用。
anon_vma_chain
anon_vma结构的提出, 完善了反向映射机制, 一路看来, 无论是效率还是内存使用, 都有了提升, 应该说是很完美的一套解决方案。但现实不断提出难题。一开始提到的Rik van Riel就举了一种工作负载(workload)的例子来反驳说该方案有缺陷。
前面的匿名页反向映射机制在解除一页映射时, 通过访问anon_vma访问vma链表, 遍历整个vma链表, 以查找可能映射到该页的PTE。但是, 这种方法忽略了一点: 当进程fork而复制产生的子进程中的vma如果发生了写访问, 将会分配新的匿名页, 把该vma指向这个新的匿名页, 这个vma就跟原来的那个匿名页没有关系了, 但原来的vma链表却没反映出这种变化, 从而导致了对该vma不必要的检查。 Rik举的例子正是对这种极端情况的描述。
Rik采取的方案是又增加一层, 新增了一个结构叫anon_vma_chain:
1 | /* |
每个anon_vma_chain(AVC)维护两个链表
- same_vma:与给定
vma相关联的所有anon_vma - same_anon_vma:与给定
anon_vma相关联的所有vma
最初,我们有一个进程与一个匿名vma:
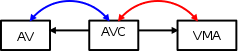
这里,“AV”是anon_vma,“AVC”是上面看到的anon_vma_chain。 AVC直接通过指针链接到anon_vma和vma。 (蓝色)链表是same_anon_vma链表,而(红色)链表是same_vma链表。
想象一下,这个进程进行了fork操作,导致子进程复制了vma; 现在有了一个孤立的新vma:
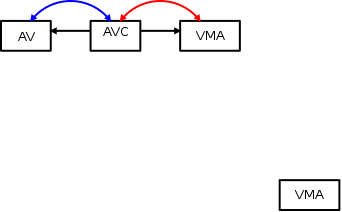
内核需要将此vma链接到父进程的anon_vma中; 这需要添加一个新的anon_vma_chain:
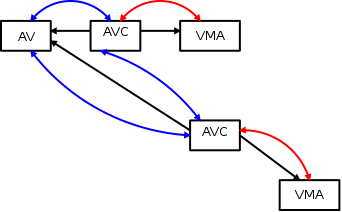
请注意,新的AVC已被添加到same_anon_vma链表中。 新的vma也需要自己的anon_vma:
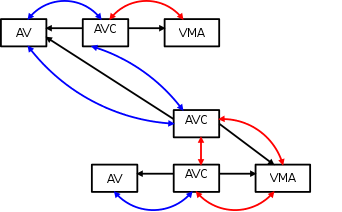
现在还有另一个anon_vma_chain链接在新的anon_vma中。 新的AVC已被添加到same_vma链表中。
此刻,根据上图,可以验证anon_vma_chain(AVC)中两个链表的作用。
The “same_vma” list contains the anon_vma_chains linking all the anon_vmas associated with this VMA.
The “same_anon_vma” list contains the anon_vma_chains which link all the VMAs associated with this anon_vma.
当子进程写内存页时,发生COW, 子进程的vma将指向自己匿名页, 同时, 这个新的匿名页指向子进程的anon_vma(此时same_anon_vma链与same_vma链解除)。
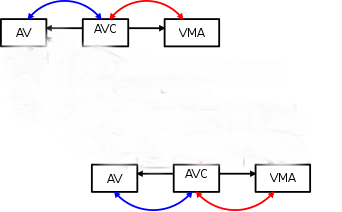
这样, 在解除一页映射时, 对于子进程自己的匿名页, 只要遍历子进程自己的anon_vma下的vma链表即可; 拥有大量子进程的父进程对于共享的页(未发生COW), 则按原来的方法遍历, 对于子进程自己的匿名页,父进程则不需要访问对应的vma,这样大大减少了父进程需要遍历的vma。
再看anon_vma_chain这个名字, 它就像个粘合剂, 也像个链条, 把初始时父,子进程关联的vma和anon_vma链接起来, 当子进程通过COW拥有自己的匿名页后, 会发生解链, 以分冶策略各自管理, 从而使得在解除一页映射时, 减少了父进程遍历的vma数目, 也减少了相应的锁冲突, 因而提高了效率。
参考资料: