C程序员该知道的内存知识
文章目录
本文翻译至What a C programmer should know about memory
C程序员该知道的内存知识
2007年,Ulrich Drepper写了What every programmer should know about memory这篇大作,本文是在这篇文章的基础上提炼而成的。
虚拟内存
除非你处理某些嵌入式系统或内核空间代码,否则你将在保护模式下工作。在保护模式下,进程拥有自己的虚拟地址空间。为了使用这个空间,你必须要求操作系统用真实的介质来支持虚拟地址空间,这就是映射(mapping)。 支持的介质可以是物理内存(不一定是RAM)或持久化存储介质(如磁盘)。
虚拟内存分配器(virtual memory allocator VMA)可能并没有给你分配真实的物理内存,VMA徒劳地希望你不会使用这些内存,这就叫做overcommiting。
1 | char *block = malloc(1024 * sizeof(char)); |
检查NULL返回值是一个很好的做法,但并不像以前一样强大。 由于overcommit,操作系统可能会给你的内存分配器一个有效的内存指针,但如果你要访问它,就会发生异常。 在这种情况下,通常是一个OOM killer 杀死你的进程。
进程地址空间布局
Anatomy of a Program in Memory这篇文章很好地说明了进程地址空间的布局。这里有些瑕疵,其中一个是它只涵盖x86-32架构的地址空间布局,但幸运的是x86-64架构的地址空间布局没有发生大的变化。与 x86-32架构相比,x86-64架构的进程可以使用更大的地址空间 (在Linux上最高达48位)。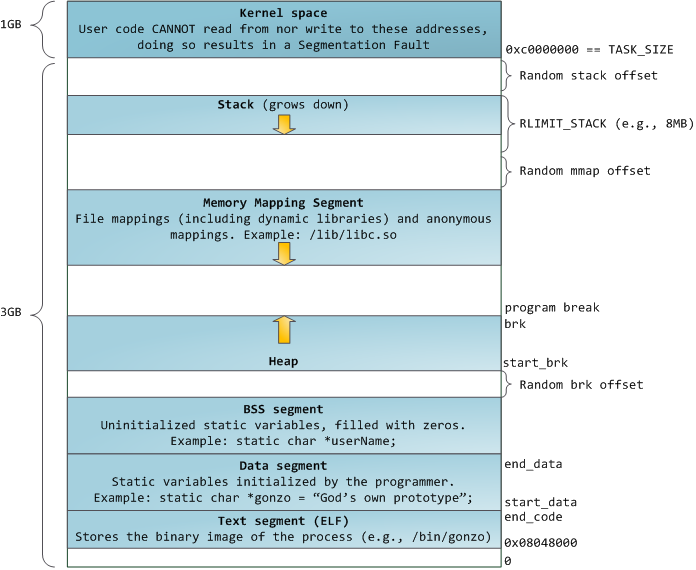
stack allocation
实用程序:
alloca()- allocate memory in the stack frame of the callergetrlimit()- get/set resource limitssigaltstack()- set and/or get signal stack context
栈很容易理解,每个人都知道如何在栈上创建变量。
1 | int stairway = 2; |
变量的有效性受范围限制,在C语言中,这意味着:{}。 所以每当一个}来了,一个变量就失效了。alloca()在当前stack frame中动态分配内存,stack frame和物理页面不是一样的,它只是一组被压到栈上的数据(函数,参数,变量…)。
variable-length arrays (VLA)与alloca()有一个不同点:VLA的有效性受范围限制;在当前函数返回之前,alloca分配的内存将保持有效。
1 | void laugh(void) { |
无论是VLA还是alloca,在分配大量内存时,都有些问题,因为你几乎无法控制可用的栈内存,而如果待分配的内存超过了栈的空间限制,这就会导致stack overflow 问题。针对stack overflow问题,有两个解决方法,但是这两者都不实用。
第一个方法是使用sigaltstack()来捕获和处理SIGSEGV。 但这只是捕获stack overflow这个异常。
另一个方法是使用split-stacks进行编译, 它被称为这样,因为它真正地将完整的栈分解成一个称为stacklets的小栈链表。 据我所知,GCC和clang使用-fsplit-stack选项支持它。 在理论上,这也可以改善内存消耗,并降低创建线程的成本 -因为栈开始可以很小,并且随着需求而增加。
heap allocation
实用程序:
brk(),sbrk()- manipulate the data segment sizemalloc()family - portable libc memory allocator
堆分配可以简单地移动program break ,并且在旧位置和新位置之间分配内存。 到目前为止,堆分配与栈分配一样快。但是如果使用这个方法的话有些问题需要注意:
1 | char *block = sbrk(1024 * sizeof(char)); |
- 我们无法回收未使用的内存块
- 不是线程安全的,因为堆在线程之间是共享的
- 接口几乎不可移植,libraries不得触及break
man 3 sbrk — Various systems use various types for the argument of sbrk(). Common are int, ssizet, ptrdifft, intptr_t.
由于这些原因,libc实现了用于内存分配的统一接口。 实现方式各不相同,但它为你提供了任何大小、线程安全的堆内存分配方式。 这样的成本是延迟,因为现在涉及到了锁机制,有关使用/空闲块信息的数据结构和额外的内存开销。
堆从start_brk到brk是连续的,考虑下面的情况:
1 | char *truck = malloc(1024 * 1024 * sizeof(char)); |
堆分配器移动brk为truck分配空间。 bike同样如此。 但是在truck被free之后,brk不能向下移动,因为brk指向bike,而bike此刻占据着最高地址。 这样的结果是进程可以重新使用前一个truck的内存,但在bike被free之前,这部分地址空间不能返回给系统。
请注意,free()并不总是尝试缩小数据段,因为这是一个潜在的昂贵的操作。对于长时间运行的程序(如守护程序)来说,这是一个问题。 存在一个名为malloc_trim()的GNU扩展,它用于从堆顶部释放内存,但可能会使进程运行的很慢。 在很多应用场景中,这个问题很严重,所以应该谨慎使用malloc_trim()。
何时使用自定义分配器
这里将上文提到的分配器称为GP分配器,有一些GP分配器不足的实际用例。例如分配大量固定大小的小块, 这可能看起来不像一个典型的模式,但它是非常频繁发生的。 例如,查找数据结构(如树和tries)通常需要节点来构建层次结构, 在这种情况下,不仅碎片是问题,还有数据的局部性。 缓存高效的数据结构将keys放在一起(最好在同一页面上),而不是将其与数据混合。 默认分配器不保证局部性。更糟糕的是,小块的分配将导致空间开销。 针对上述问题,这里有解决方案!
Slab allocator
实用程序:
posix_memalign()- allocate aligned memory
Bonwick为内核对象缓存描述了slab allocator的原理,但slab allocator也适用于用户空间。allocator分配slab内存,即一个整页,并将其切成许多固定大小的块。 假设每个块至少可以保存一个指针或整数,你可以将它们链接到list中,其中list head指向第一个空闲元素。
1 | /* Super-simple slab. */ |
allocation相当于pop list head,Freeing相当于push新的list head。 如果slab与page_size边界对齐,则可以使用rounding down技巧。
1 | /* Free an element */ |
要想利用层级结构及缓存局部性的相关特性,我们可以使用现成的库,例如,gasp ,glib实现有一个整洁的文档,并称之为“memory slices”。
Memory pools
实用程序:
obstack_alloc()- allocate memory from object stack
Slab allocator一旦分配就分配一个slab,当free的时候,slab中的内存块会被全部释放掉;obstack_alloc() 则提供了一个内存块的栈,你可以pop与push内存块,这样在free的时候就不需要释放全部的内存块,而且内存块还可以添加到栈中。
1 | /* Define block allocator. */ |
1 | /* This is wrong, I better cancel it. */ |
Demand paging
实用程序:
mlock()- lock/unlock memorymadvise()- give advice about use of memory
GP内存分配器不会立即将内存返回给系统的原因之一是成本高昂。如果要将内存立刻返回给系统, 系统必须做两件事情:(1)建立虚拟页面到真实页面的映射;(2)给你一个空白的真实页面。而overcommit的做法是: 虚拟内存分配器仅完成第一件事情,虚拟地址指向的页面不是指向一个真实的页面,而是指向一个特殊的页面0。
每次尝试访问特殊页面时,都会发生page fault,这意味着:内核会暂停进程的执行并获取一个真实的页面,然后更新页面表,之后进程恢复执行。 demand paging也被称为lazy loading,这里有更详细的解释。
内存管理器对你如何访问内存做出非常保守的预测。你可以lock物理内存中的连续内存块以避免页面被swap出去而发生page fault:
1 | char *block = malloc(1024 * sizeof(char)); |
你还可以提供内存使用模式的advise:
1 | char *block = malloc(1024 * sizeof(block)); |
实际建议的解释是平台特定的,系统甚至可以选择忽略它。 并不是所有的建议都得到很好的支持,有些甚至会改变语义,但MADV_SEQUENTIAL,MADV_WILLNEED和MADV_DONTNEED这三个是最常用的。
memory mapping
实用程序:
sysconf()- get configuration information at run timemmap()- map virtual memorymincore()- determine whether pages are resident in memoryshmat()- shared memory operations
一个页面通常是一个4KB的块,但你不应该依赖它,应该使用sysconf()来获取页面大小。
1 | long page_size = sysconf(_SC_PAGESIZE); /* Slice and dice. */ |
即使平台统一页面大小,系统中所有页面的大小也未必相同。 例如,Linux有一个透明大页面(THP)机制,THP对你是透明的,但是Linux的mmap选项MAP_HUGETLB允许你明确地使用它。
Fixed memory mappings
在 x86-64架构下,大约2/3TASK_SIZE(用户进程的最高可用地址)的地址是一个安全的选择。
1 |
|
这不是一个可移植的例子,但点明了要点。 映射固定地址范围通常被认为是不安全的,因为它不会检查这段地址空间是否已经被映射过。 mincore()函数可以告诉你页面是否被映射到物理内存中,但是在多线程环境下这个方法是行不通的。
然而,固定地址映射不仅对未使用的地址范围有用,对于使用过的地址范围也是有用的。 内存分配器使用mmap()来获取更大的内存块,由于on-demand paging,这使得有效的稀疏阵列成为可能。 假设你创建了一个稀疏阵列,现在你要释放一些数据,那么该如何做呢? 你不能完全free它,因此不能使用munmap()。 你可以使用madvise() MADV_FREE / MADV_DONTNEED来标记待free的页面,这是最佳的解决方案。
下面是一个可移植的例子:
1 | void *array = mmap(NULL, length, PROT_READ|PROT_WRITE, |
这相当于unmap旧页面并再次map特殊页面,这样该进程仍然使用相同数量的虚拟内存,但驻留在物理内存中的数据量会降低。
File-backed memory maps
实用程序:
msync()- synchronize a file with memory mapftruncate()- truncate a file to a specified lengthvmsplice()- splice user pages into a pipe
到目前为止,我们介绍的一直都是匿名内存,接下来将介绍 File-backed的内存映射,它提供了缓存,同步和 copy-on-write机制。
File-backed的共享内存映射添加了新的模式MAP_SHARED,这意味着你对页面所做的更改将被写回文件,因此这个文件在进程间是共享的。 内存管理器决定什么时候同步,但幸运的是有msync()函数强制页面与backing store进行同步。msync()对数据库是非常好的,因为它保证了写数据的持久性。
1 | /* Map the contents of a file into memory (shared). */ |
请注意,你不能映射比实文件size更多的数据,因此你无法增长或缩小。 然而,你可以使用ftruncate()提前创建(或增长)稀疏文件。 缺点是,它使内存压缩(compaction)更加困难。
1 | /* Resize the file. */ |
Copy-on-write
到目前为止,这是关于共享内存映射。 但是你可以使用另一种方式的内存映射- 映射文件的共享副本,并且在修改后无需修改backing store。 请注意,页面不会被立即copy,这是没有意义的,但在你修改页面的那一刻,立刻发生copy操作。
1 | int fd = open(...); |
Zero-copy streaming
由于文件本质上是内存,你可以将其流式传输到管道(包括套接字)中,这样就无需发生copy操作。
1 | int sock = get_client(); |
mmap()的问题
在有些情下况,与通常的read()/write()文件相比,mmap文件会大大降低系统性能。 处理 page fault会比简单地读取文件慢,因为mmap必须读取文件并做更多的事情。 实际上,mmapped I/ O可能会更快,因为它避免了数据的多重缓存,并且在后台可以预读。 但有时候这种做法将会损害系统的性能, 一个这样的例子是:当文件的大小超过可用内存空间,而我们只随机读取文件中的一小部分。 在这种情况下,系统会读取可能不被使用的块,并且每次内存访问都会发生page fault,从而导致TLB thrashing问题。 你可以用madvise()来减少系统损失。
memory consumption
实用程序:
vmtouch- portable virtual memory toucher
Terms
- VSS- Virtual Set Size 进程虚拟使用内存(包含共享库占用的内存)
- RSS- Resident Set Size 进程实际使用物理内存(包含共享库占用的内存)
- PSS- Proportional Set Size 进程实际使用的物理内存(比例分配共享库占用的内存)
- USS- Unique Set Size 进程独自占用的物理内存(不包含共享库占用的内存)
一般来说内存占用大小有如下规律:VSS >= RSS >= PSS >= USS
资料整理: