系统性能分析工具
在系统运行过程中,我们往往会对某实验结果感到困惑,此刻,我们需要利用一些系统性能分析工具进行分析,查看问题的来源。下面,就介绍几种常用的工具:
top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况。top命令的详解请参考这篇文章。
perf
perf 是用来进行软件性能分析的工具,使用 perf,你可以分析程序运行期间发生的硬件事件,比如 instructions retired ,processor clock cycles 等;你也可以分析软件事件,比如 page fault 和进程切换。
这使得 perf 拥有了众多的性能分析能力,举例来说,使用 perf 可以计算每个时钟周期内的指令数,称为 IPC,IPC 偏低表明代码没有很好地利用 CPU。perf 还可以对程序进行函数级别的采样,从而了解程序的性能瓶颈究竟在哪里等等。
perf 的基本使用
perf的安装:
sudo apt-get install linux-tools-common linux-tools-generic linux-tools-`uname -r`
说明一个工具的最佳途径是列举一个例子。
考查下面这个例子程序。其中函数 longa() 是个很长的循环,比较浪费时间。函数 foo1 和 foo2 将分别调用该函数 10 次,以及 100 次。
清单 1. 测试程序 t11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28//test.c
void longa()
{
int i,j;
for(i = 0; i < 1000000; i++)
j=i; //am I silly or crazy? I feel boring and desperate.
}
void foo2()
{
int i;
for(i=0 ; i < 10; i++)
longa();
}
void foo1()
{
int i;
for(i = 0; i< 100; i++)
longa();
}
int main()
{
foo1();
foo2();
return 0;
}
找到这个程序的性能瓶颈无需任何工具,肉眼的阅读便可以完成。Longa() 是这个程序的关键,只要提高它的速度,就可以极大地提高整个程序的运行效率。
但因为其简单,却正好可以用来演示 perf 的基本使用。
perf stat
做任何事都最好有条有理。老手往往能够做到不慌不忙,循序渐进,而新手则往往东一下,西一下,不知所措。
面对一个问题程序,最好采用自顶向下的策略。先整体看看该程序运行时各种统计事件的大概,再针对某些方向深入细节。而不要一下子扎进琐碎细节,会一叶障目的。
有些程序慢是因为计算量太大,其多数时间都应该在使用 CPU 进行计算,这叫做 CPU bound 型;有些程序慢是因为过多的 IO,这种时候其 CPU 利用率应该不高,这叫做 IO bound 型;对于 CPU bound 程序的调优和 IO bound 的调优是不同的。
如果你认同这些说法的话,perf stat 应该是你最先使用的一个工具。它通过概括精简的方式提供被调试程序运行的整体情况和汇总数据。
还记得我们前面准备的那个例子程序么?现在将它编译为可执行文件 t1gcc -o t1 -g test.c
下面演示了 perf stat 针对程序 t1 的输出:perf stat ./t1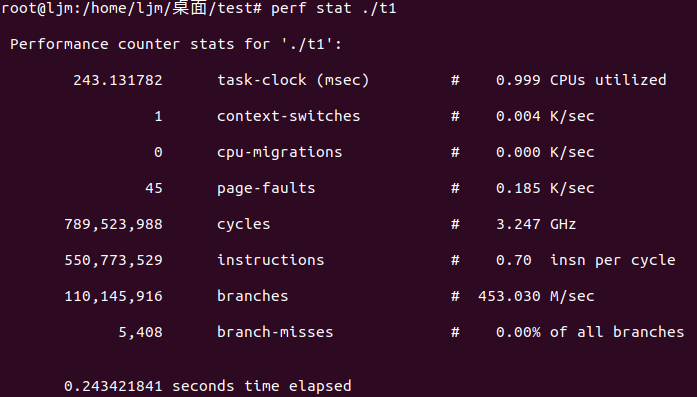
上面告诉我们,程序 t1 是一个 CPU bound 型,因为 task-clock-msecs 接近 1。
对 t1 进行调优应该要找到热点 ( 即最耗时的代码片段 ),再看看是否能够提高热点代码的效率。
缺省情况下,除了 task-clock-msecs 之外,perf stat 还给出了其他几个最常用的统计信息:
Task-clock-msecs:CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
Context-switches:进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。
Cache-references: cache 命中的次数
Cache-misses:cache 失效的次数,反应了程序运行过程中总体的 cache 利用情况,如果该值过高,说明程序的 cache 利用不好。
CPU-migrations:表示进程 t1 运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
Cycles:处理器时钟,一条机器指令可能需要多个 cycles。
Instructions: 机器指令数目。
IPC:是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性。
perf top
使用 perf stat 的时候,往往你已经有一个调优的目标。比如我刚才写的那个程序 t1。
也有些时候,你只是发现系统性能无端下降,并不清楚究竟哪个进程占据了系统大部分资源。
此时需要一个类似 top 的命令,列出所有值得怀疑的进程,从中找到需要进一步审查的家伙。类似法制节目中办案民警常常做的那样,通过查看监控录像从茫茫人海中找到行为古怪的那些人,而不是到大街上抓住每一个人来审问。
perf top 用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程。
让我们再设计一个例子来演示吧。
不知道你怎么想,反正我觉得做一件有益的事情很难,但做点儿坏事儿却非常容易。我很快就想到了如代码清单 2 所示的一个程序:
清单 2. 一个死循环while (1) i++;
我叫他 t2。启动 t2,然后用 perf top 来观察:
下面是 perf top 的输出: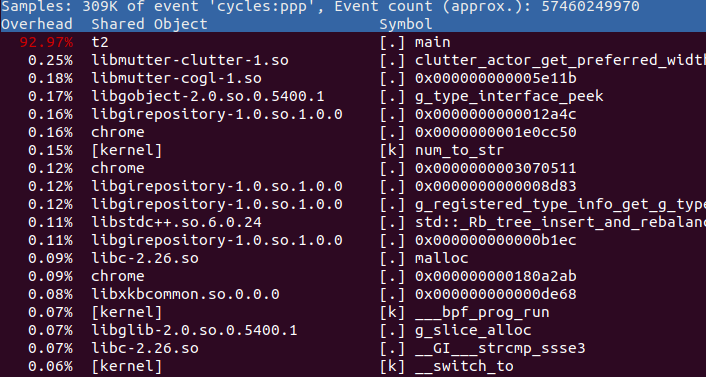
很容易便发现 t2 是需要关注的可疑程序。不过其作案手法太简单:肆无忌惮地浪费着 CPU。所以我们不用再做什么其他的事情便可以找到问题所在。但现实生活中,影响性能的程序一般都不会如此愚蠢,所以我们往往还需要使用其他的 perf 工具进一步分析。
使用 perf record 和perf report
使用 top 和 stat 之后,你可能已经大致有数了。要进一步分析,便需要一些粒度更细的信息。比如说你已经断定目标程序计算量较大,也许是因为有些代码写的不够精简。那么面对长长的代码文件,究竟哪几行代码需要进一步修改呢?这便需要使用 perf record 记录单个函数级别的统计信息,并使用 perf report 来显示统计结果。
你的调优应该将注意力集中到百分比高的热点代码片段上,假如一段代码只占用整个程序运行时间的 0.1%,即使你将其优化到仅剩一条机器指令,恐怕也只能将整体的程序性能提高 0.1%。俗话说,好钢用在刀刃上,不必我多说了。
仍以 t1 为例。perf record – e cpu-clock ./t1perf report
perf report 示例结果如下图所示:
不出所料,热点是 longa( ) 函数。
但代码是非常复杂的,t1 程序中的 foo1() 也是一个潜在的调优对象,为什么要调用 100 次那个无聊的 longa() 函数呢?但我们在上图中无法发现 foo1 和 foo2,更无法了解他们的区别了。
使用 perf 的 -g 选项便可以得到需要的信息:perf record – e cpu-clock – g ./t1perf report
perf – g report 示例结果如下图所示: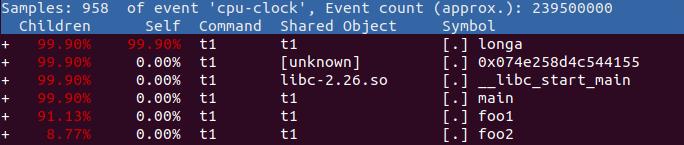
通过对调用图的分析,能很方便地看到 91% 的时间都花费在 foo1() 函数中,因为它调用了 100 次 longa() 函数,因此假如 longa() 是个无法优化的函数,那么程序员就应该考虑优化 foo1,减少对 longa() 的调用次数。
参考资料: