linux kernel中HList和Hashtable
文章目录
HList
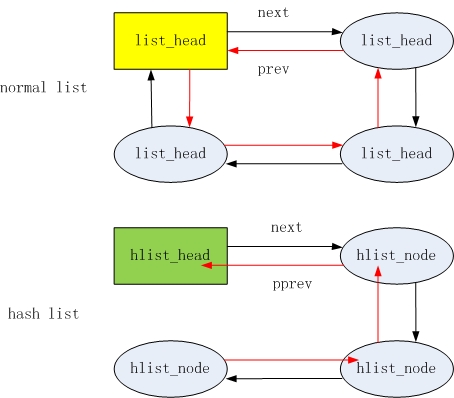
1.1 普通链表
普通链表的表头和节点相同1
2
3struct list_head {
struct list_head *next, *prev;
};
详情请参考内核数据结构之链表。
1.2 哈希链表
HList的资料结构定义在 include/linux/types.h 之中:
哈希链表头1
2
3struct hlist_head {
struct hlist_node *first;
};
哈希链表节点1
2
3struct hlist_node {
struct hlist_node *next, **pprev;
};
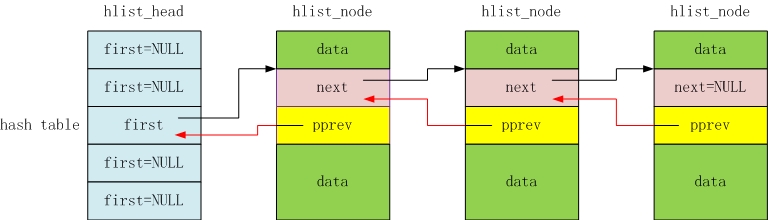
hlist_head 和 hlist_node 用于 hash table 中 bucket 的实际操作,具有相同 hash value 的节点会放在同一条 hlist 中。 为了节省空间,hlist_head 只使用一个 first 指针指向 hlist_node,没有指向尾节点的指针。
hlist_node 有两个指针,但是需要注意的是 pprev 是指向指针的指针,它指向的是前一个节点的 next指针。
因为这时候表头(hlist_head)和节点(hlist_node)的数据结构不同。如果使用struct hlist_node *prev,只适用于前一个为节点的情况,而不适用于前一个为表头的情况。如果每次操作都要考虑指针类型转换,会是一件麻烦的事情。所以,我们需要一种统一的操作,而不用考虑前一个元素是节点还是表头。pprev指向前一个元素的next指针,不用管前一个元素是节点还是表头。当我们需要操作前一个元素(节点或表头),可以统一使用*(node->pprev)来访问和修改前一元素的next(或first)指针。
原理图如下:
1.3 相关操作
HList 的操作与 List 一样定义在: include/linux/list.h ,以 hlist_ 开头
Hashtable
2.1 定义
在 Linux kernel 3.7 之后采用由Sasha Levin设计的通用型 hash table (LWN: A generic hash table),使用 DEFINE_HASHTABLE(name, bits)的macro来宣告 hash table:
- name: the name of the hash table
- bits: the number of bits of hash values
第二的参数 bits 比较特别,它代表的是 hash value 的有效位元数。若 bits = 3,hash value 的范围会是 0~7,若 bits = 10,hash value 的范围会是 0 ~ 1023。前者需要准备 8 个 buckets,后者则需要 1024 个 buckets,bits 参数会决定 hash table 的 buckets 的数量 (=2^bits)。hashtable实际上会以 hlist_head array 的方式来配置。
举例来说, DEFINE_HASHTABLE(htable, 3)会展开成:struct hlist_head htable[8] = { [0 ... 7] = HLIST_HEAD_INIT };
这是一个有 8 个 buckets 的 hash table。
经由 hash function 将值映射到这 8 个 buckets 中,当冲突发生时,直接加到 hlist_head 后的串列中。
2.2 相关操作
hash table 相关的操作定义在 include/linux/hashtable.h
hash_init- initialize a hash tablehash_empty- check whether a hashtable is emptyhash_add- add an object to a hashtablehash_del- remove an object from a hashtablehash_for_each- iterate over a hashtablehash_for_each_possible- iterate over all possible objects hashing to the same bucket
2.3 相关API
- HLIST_HEAD_INIT: 静态初始化hlist_head
- HLIST_HEAD: 静态初始化hlist_head
- INIT_HLIST_HEAD: 动态初始化hlist_head
- INIT_HLIST_NODE: 动态初始化hlist_node
- hlist_unhashed: 判断hlist_node是否添加到hash链表中
- hlist_empty: 判断hash链表是否为空
- hlist_del: 在hash链表中删除一个节点
- hlist_del_init: 在hash链表中删除一个节点
- hlist_add_head: 在hash链表头添加一个节点
- hlist_add_before: 在指定节点之前添加一个节点
- hlist_add_behind: 在指定节点之后添加一个节点
- hlist_add_fake
- hlist_fake
- hlist_is_singular_node: 判断hlist是否只有一个节点
- hlist_move_list: 将一个hash链表从一个hlist_head移动到另外一个hlist_head中
- hlist_entry: 根据hlist_node找到其外层结构体
- hlist_entry_safe: 同上
- hlist_for_each: 遍历hash链表
- hlist_for_each_safe: 同上
- hlist_for_each_entry: 遍历hash链表
- hlist_for_each_entry_safe: 同上
- hlist_for_each_entry_continue: 从当前节点之后遍历hash链表
- hlist_for_each_entry_from: 从当前节点开始遍历hash链表
2.4 hash function
hashtable 预设的 hash function 定义在 include/linux/hash.h ,有 32 和 64 两个版本,如下:1
2
3
4
5
6
7
8
9
10
11/* 2^31 + 2^29 - 2^25 + 2^22 - 2^19 - 2^16 + 1 */
static inline u32 hash_32(u32 val, unsigned int bits)
{
/* On some cpus multiply is faster, on others gcc will do shifts */
u32 hash = val * GOLDEN_RATIO_PRIME_32;
/* High bits are more random, so use them. */
return hash >> (32 - bits);
}
1 | /* 2^63 + 2^61 - 2^57 + 2^54 - 2^51 - 2^18 + 1 */ |
2.5 Hashtable example
下面用例子来说明 hashtable 的使用:1
2
3
4
5
6
7struct object
{
int id;
char name[16];
struct hlist_node node;
};
1 | void hashtable_example() |
经过上面的操作之后,hash table 呈现如下:
obj1 和 obj9 的 hash value 冲突,放入同一个 bucket 的串列中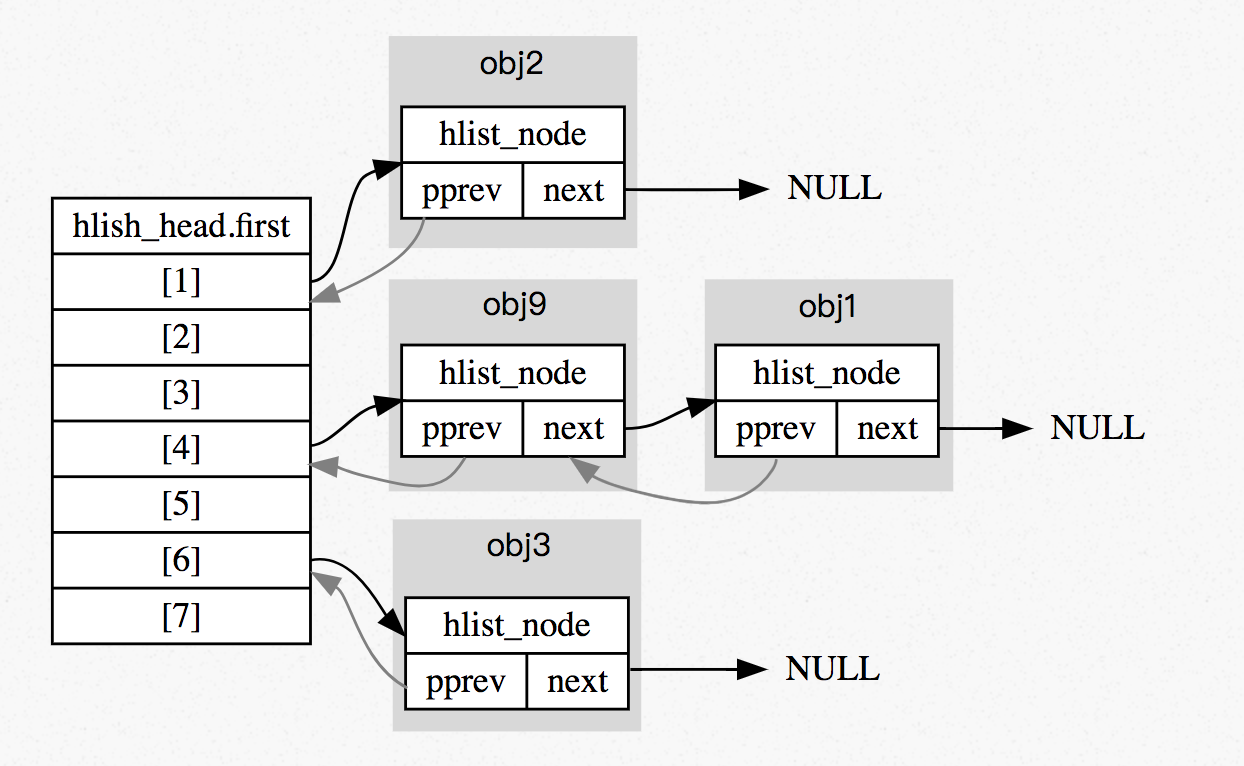
以 hash_for_each_possible()寻访 bucket 内所有的节点(hlist_node),因为 hash value 可能会有冲突的关系,同一个 bucket 内可能会有不同 key value 的节点,所以需要检查是不是要查找的 key value。1
2
3
4
5
6
7int key = 1;
struct object* obj;
hash_for_each_possible(htable, obj, node, key) {
if(obj->id == key) {
printf("key=%d => %s\n", key, obj->name);
}
}
函数的详细使用方法可以参考hashtable_example.c
1 |
|
参考资料: