CPU Cache
文章目录
本文主要转载自卢钧轶(cenalulu)
原文地址:http://cenalulu.github.io/linux/all-about-cpu-cache/
为什么要有CPU Cache
随着工艺的提升最近几十年CPU的频率不断提升,而受制于制造工艺和成本限制,目前计算机的内存主要是DRAM并且在访问速度上没有质的突破。因此,CPU的处理速度和内存的访问速度差距越来越大,甚至可以达到上万倍。同时又由于内存数据访问的热点集中性,在CPU和内存之间用较为快速而成本较高的SDRAM做一层缓存,就显得性价比极高了。
为什么要有多级CPU Cache
随着科技发展,热点数据的体积越来越大,单纯的增加一级缓存大小的性价比已经很低了。因此,就慢慢出现了在一级缓存(L1 Cache)和内存之间又增加一层访问速度和成本都介于两者之间的二级缓存(L2 Cache)。下面是一段从What Every Programmer Should Know About Memory中摘录的解释:
Soon after the introduction of the cache the system got more complicated. The speed difference between the cache and the main memory increased again, to a point that another level of cache was added, bigger and slower than the first-level cache. Only increasing the size of the first-level cache was not an option for economical reasons.
此外,又由于程序指令和程序数据的行为和热点分布差异很大,因此L1 Cache也被划分成L1i (i for instruction)和L1d (d for data)两种专门用途的缓存。 下面一张图可以看出各级缓存之间的响应时间差距,以及内存到底有多慢!

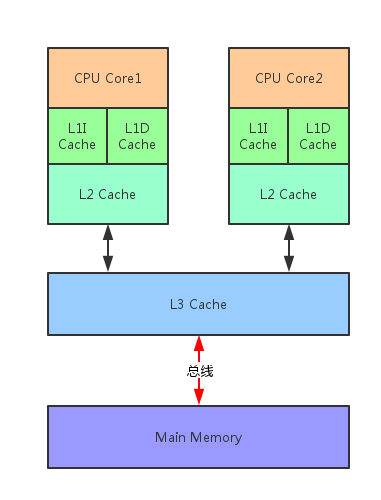
CPU包含多个核,每个核又有独自的一级缓存和二级缓存,各个核心之间共享三级缓存,并统一通过总线与内存进行交互。
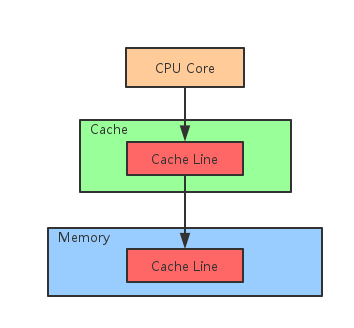
Cache Line
整个Cache被分成多个Line,每个Line通常是32byte或64byte。
Cache Line是Cache和内存交换数据的最小单位。
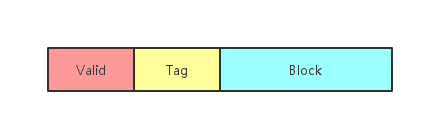
每个Cache Line包含三个部分:
- Valid:当前缓存是否有效
- Tag:对应的内存地址
- Block:缓存数据
了解Cache Line的概念对我们程序猿有什么帮助? 我们来看下面这个C语言中常用的循环优化例子 下面两段代码中,第一段代码在C语言中总是比第二段代码的执行速度要快。具体的原因相信你仔细阅读了Cache Line的介绍后就很容易理解了。
1 | for(int i = 0; i < n; i++) { |
1 | for(int i = 0; i < n; i++) { |
CPU Cache 是如何存放数据的
假设我们有一块4MB的区域用于缓存,每个缓存对象的唯一标识是它所在的物理内存地址。每个缓存对象大小是64Bytes,所有可以被缓存对象的大小总和(即物理内存总大小)为4GB。那么我们该如何设计这个缓存?
Fully Associative(全关联映射)
Fully Associative 字面意思是全关联。在CPU Cache中的含义是:如果在一个Cache集内,任何一个内存地址的数据可以被缓存在任何一个Cache Line里,那么我们成这个cache是Fully Associative。从定义中我们可以得出这样的结论:给到一个内存地址,要知道他是否存在于Cache中,需要遍历所有Cache Line并比较缓存内容的内存地址。而Cache的本意就是为了在尽可能少得CPU Cycle内取到数据。那么想要设计一个快速的Fully Associative的Cache几乎是不可能的。
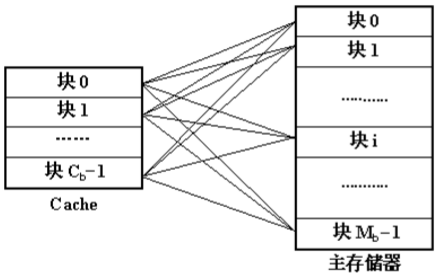
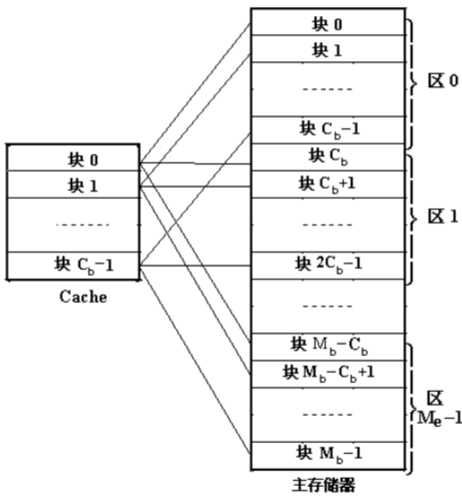
直接映射
和Fully Associative完全相反,使用Direct Mapped模式的Cache给定一个内存地址,就唯一确定了一条Cache Line。设计复杂度低且速度快。那么为什么Cache不使用这种模式呢?直接映射方式的缺点是不够灵活,因每个主存只能固定地对应某个缓存快,即使缓存内还空着许多位置也不能占用,使缓存的存储空间得不到充分的利用。此外,如果程序恰好重复要访问对应同一缓存位置的不同主存块,就要不停地进行替换,从而降低命中率。
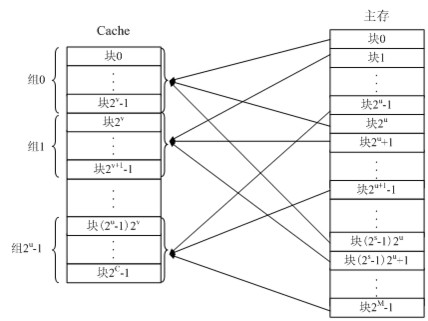
组相连映射
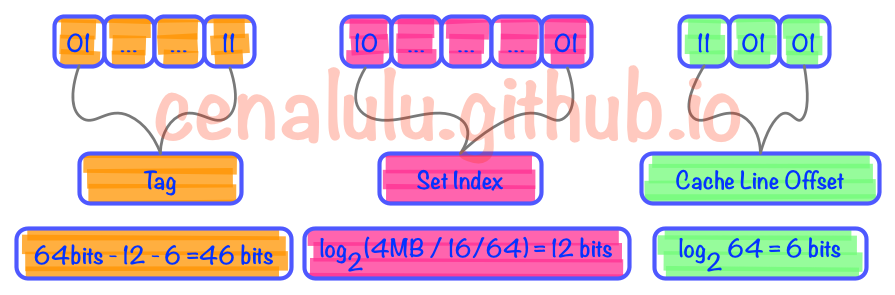
为了避免以上两种设计模式的缺陷,N-Way Set Associative缓存就出现了。他的原理是把一个缓存按照N个Cache Line作为一组(set),缓存按组划为等分。这样一个64位系统的内存地址在4MB二级缓存中就划成了三个部分(见下图),低位6个bit表示在Cache Line中的偏移量,中间12bit表示Cache组号(set index),剩余的高位46bit就是内存地址的唯一id。这样的设计相较前两种设计有以下两点好处:(16路组相连)
- 给定一个内存地址可以唯一对应一个set,对于set中只需遍历16个元素就可以确定对象是否在缓存中(Full Associative中比较次数随内存大小线性增加)
- 每2^18(512K)*64=32M的连续热点数据才会导致一个set内的conflict(Direct Mapped中512K的连续热点数据就会出现conflict)
替换策略
随机
随机确定要替换的块
先进先出
选择最先调入的块进行替换
LRU(最近最少使用)
根据块的使用情况,选择最近最少使用的块进行替换,反映了程序的局部性规律
写模式
Write-through(直写模式)
在数据更新时,同时写入缓存Cache和后端存储(如下一级cache或者内存)。此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢。
Write-back(回写模式)
在数据更新时只写入缓存Cache。只在数据被替换出缓存时,被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回。
参考资料:
- 关于CPU Cache – 程序猿需要知道的那些事
- CPU Cache结构
- 《计算机组成原理》(第2版) 唐朔飞 编著
- Cache写机制:Write-through与Write-back
- 7个示例科普CPU CACHE