Designing Data-Intensive Applications 读书笔记 -Replication
文章目录
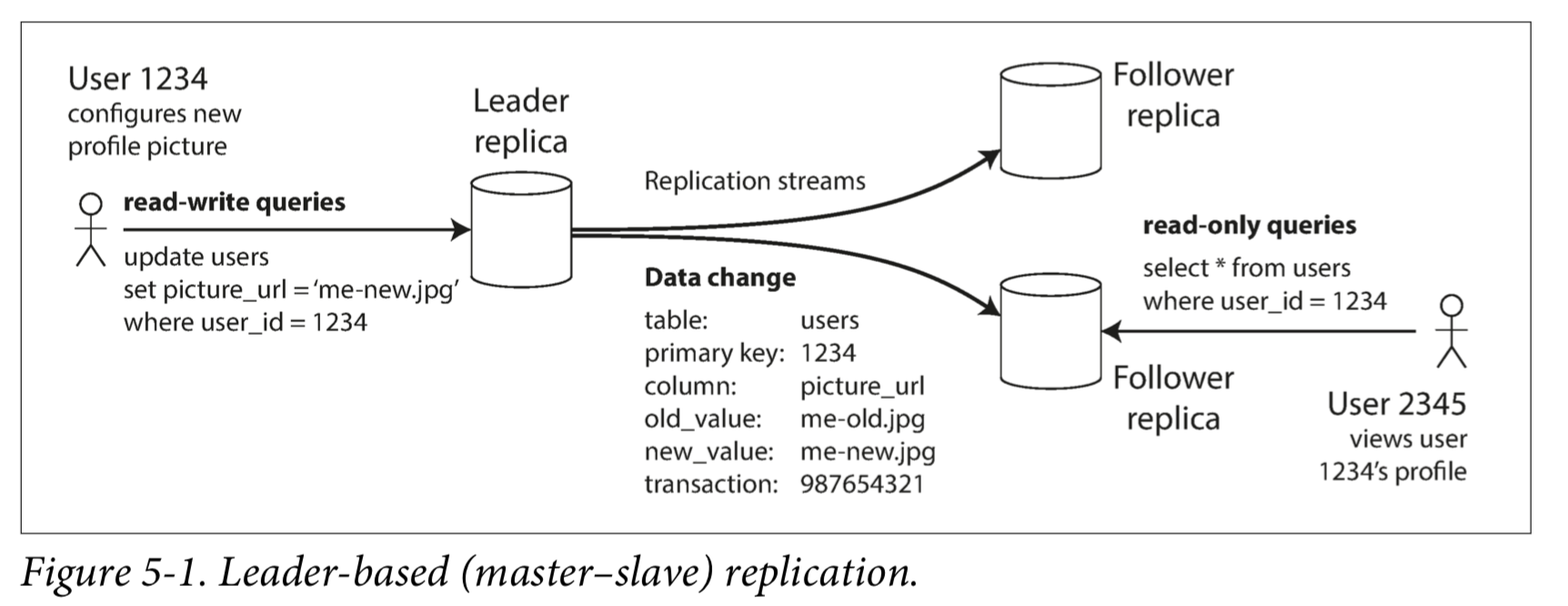
Leader 和 Follower
- 用户端写入的时候,必须先经过Leader处理
- 其它节点是Follower,Leader写入完毕后会通知他们复制数据,保证一致性
- 客户端读的时候,可以随便读,但写的时候只能向Leader写
同步复制与异步复制
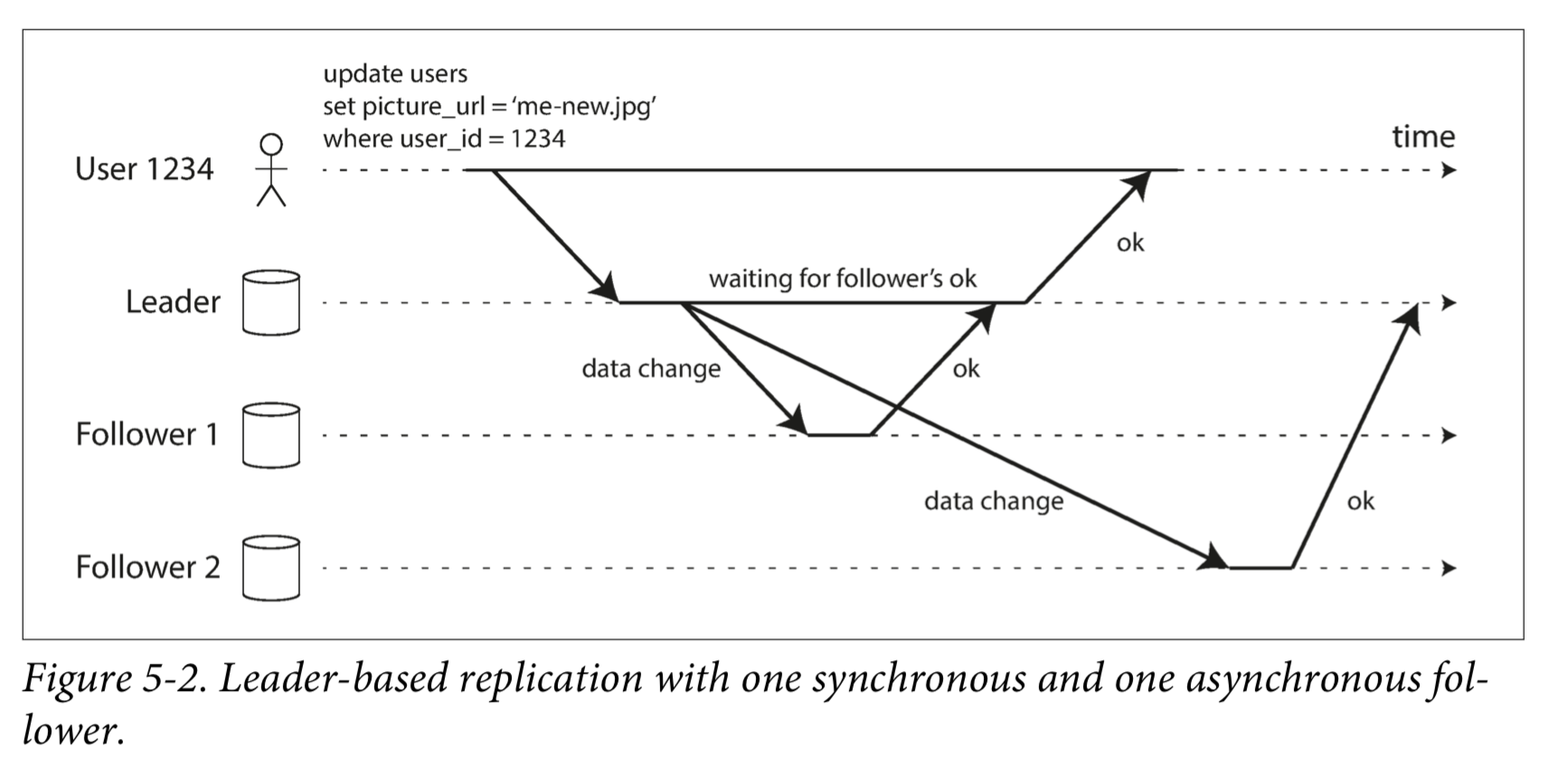
上图中Follower1是同步复制,Follower2是异步复制
同步复制:
写入请求时,Leader 会一直等到所有 Follower 都确认已经写入后(期间不处理任何写请求),才向客户端返回成功
优点:保证强一致性
缺点:如果任何 Follower 挂掉,都会写失败,这在大型系统中是不现实的
所以在实际的数据库中,使用的都是半同步(semi-synchronous),即一个 Follower 是同步的,其它都是异步;如果同步的那个 Follower 挂了,那么设置一个新的 Follower 为同步模式
异步复制:
写入请求时,Leader 自己写入成功后就返回,不等待 Follower
优点:可以立刻响应写入请求,即使所有 Follower 都挂掉了
缺点:可能会导致不一致(Leader和Follower中的状态不一样)
增加新的 Follower
即如何在集群不断写入数据的同时,加入新的 Follower,让它的数据跟上大部队
- 给 Leader 某个时刻的数据做一个快照
- 把快照复制到新的 Follower 上
- 新的 Follower 连接上 Leader,告诉它从哪个时刻开始同步数据
- 直到新 Follower 的数据跟上了 Leader 的步伐(caught up),开始进入工作
处理节点宕机
Follower 宕机
从宕机前的日志开始和 Leader 同步即可,直到Follower 的数据跟上了 Leader 的步伐,开始进入工作
Leader 宕机
one of the followers needs to be promoted to be the new leader, clients need to be reconfigured to send their writes to the new leader, and the other followers need to start consuming data changes from the new leader. This process is called failover.
failover的步骤如下:
- 检测 Leader 宕机
- 选出新的 Leader
- 把系统配置改为新的 Leader
Implementation of Replication Logs
Statement-based replication
基于语句的复制,比如在 SQL 中复制 INSERT、UPDATE、DELETE 语句到 Follower。
存在一些问题:
- NOW()、RANDOM()这样的函数,没法基于语句复制,因为每次运行的结果都不一样
- 如果语句依赖自增数,或者跟数据库中现有的数据强相关,那么必须保证语句执行顺序跟 Leader 完全一致,在并发处理多个事务时这一点很难保证
- 语句有副作用时,可能会导致不一致的出现
Write-ahead log (WAL) shipping
本书的第三章讨论了日志结构的储存引擎的实现(SSTable、LSM-Tree 和 B-Tree),如果是这种储存引擎,我们可以把它的每一次写日志都复制到 Follower 上,这样可以保证一致性。
PostgreSQL 和 Oracle 就是这样实现的,缺陷在于,这种复制方式非常底层,每一条 WAL 包含的信息实际上是“向哪一个硬盘 block 写哪些 bytes”,这就导致 WAL 和储存引擎强相关,也就是必须保证 Leader 和 Follower 的储存引擎底层完全一致,导致集群很难进行版本升级。
Logical (row-based) log replication
把日志抽象为与底层引擎无关,采用 change data capture,每次有数据更改的时候都记下改了什么,例如记录每次写入的值和行号,MySQL 的 binlog 就是这样实现的。
复制滞后产生的问题
对于单 Leader,多 Follower的架构来说,一般是只能向 Leader 写,但可以向任何 Follower 读,这样可以大大增加读的性能。
但由于写操作需要向 Follower 复制,这里就会产生滞后问题,写完后立刻读,有可能会从 Follower 中读到旧的值(因为此时 Leader 可能还没有同步变化到 Follower 上)。
当然这种不一致的状态是转临时逝的(如果停止向数据库中写入数据并等待一段时间,从库最终会赶上并与主库保持一致),不会永久存在,也就是所谓的 “最终一致性”。
因为滞后时间太长引入的不一致性,可不仅是一个理论问题,更是应用设计中会遇到的真实问题。本节将重点介绍三个由复制滞后所带来的问题,并简述解决这些问题的一些方法。
Reading Your Own Writes
许多应用让用户提交一些数据,然后查看他们提交的内容。但对于异步复制,问题就来了。如下图所示:如果用户在写入后马上就查看数据,则新数据可能尚未到达副本。对用户而言,看起来好像是刚提交的数据丢失了。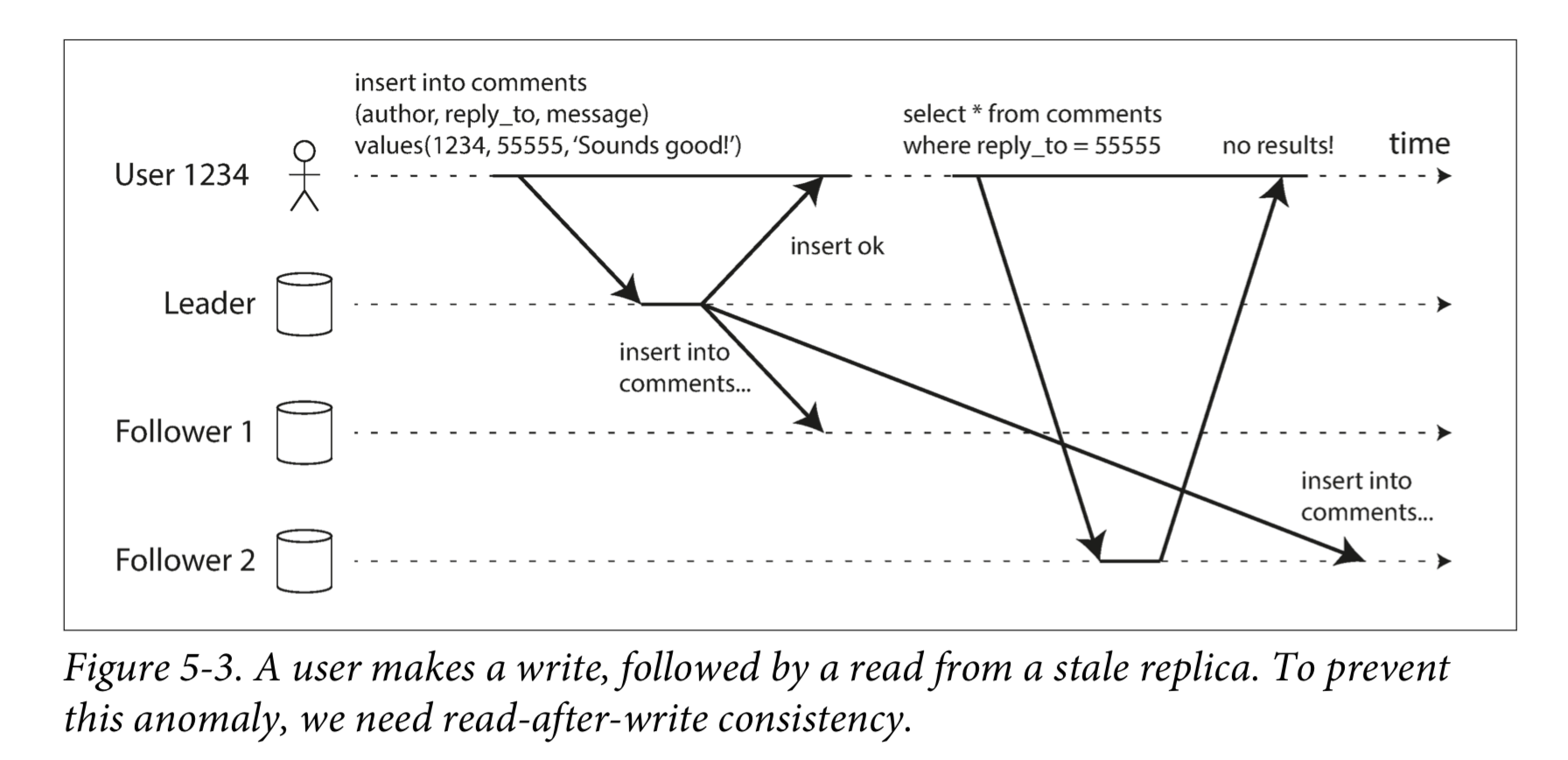
在这种情况下,我们需要读写一致性(read-after-write consistency)。这是一个保证,如果用户重新加载页面,他们总会看到他们自己提交的任何更新。它不会对其他用户的写入做出承诺:其他用户的更新可能稍等才会看到。它保证用户自己的输入已被正确保存。
具体可以有以下策略:
- 如果读的字段可能已经发生了变化,那么向 Leader 读取(因为 Leader 的数据一定是最新的);
- 如果读的字段距离上一次变更时间很短,那么向 Leader 读;
- 客户端在读请求的时候带上自己最近一次写操作的时间戳,处理这个读请求的服务器看到这个时间戳,就可以知道自己本地的数据是否过时了
单调读(Monotonic Reads)
客户端进行多次读操作时,这些读操作可能会分配到不同的 Follower 上,所以可能会发生第一次读到了数据,然后第二次读的时候数据又消失了的问题,如下图 User 2345,第一次在 Follower1 上读到了评论,第二次在 Follower2 上没有读到评论:
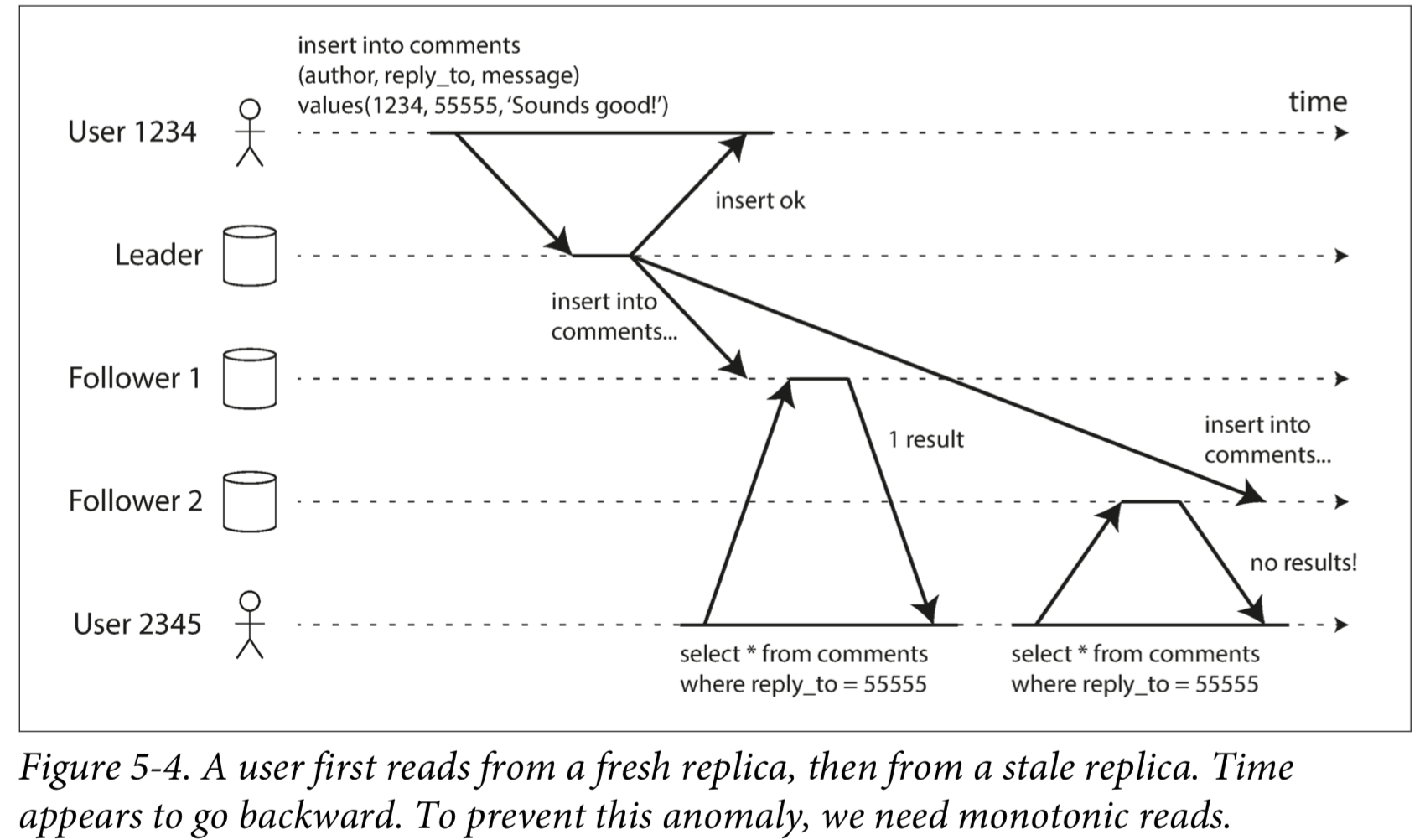
所以,客户端读到了新的数据,那么就不能让它读到旧数据。最简单的解决方法就是,把每个客户端的读请求都分配到固定的 Follower 上。
Consistent Prefix Reads
由于服务器之间复制数据可能产生的滞后,数据的时序可能会产生问题。
比如下图,Mr. Poons 先说了一句话,然后 Mrs. Cake 回复了他,然而对于第三方观察者而言,他们的对话时序可能是混乱的:
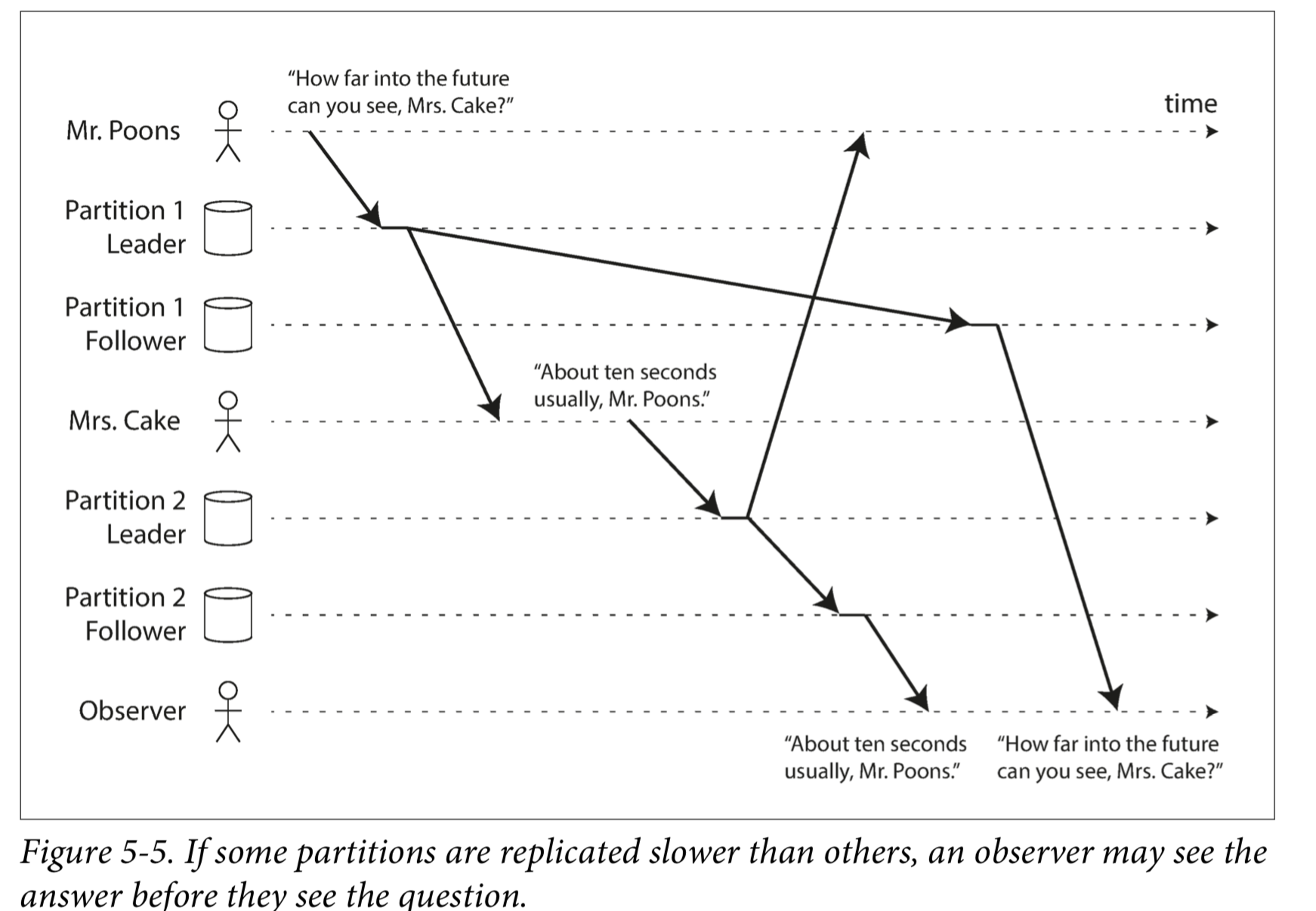
防止这种异常,需要另一种类型的保证:一致前缀读(consistent prefix reads)。 这个保证了:如果一系列写入按某个顺序发生,那么任何人读取这些写入时,也会看见它们以同样的顺序出现。
这是分区(partitioned)数据库中的一个特殊问题。如果数据库总是以相同的顺序应用写入,则读取总是会看到一致的前缀,所以这种异常不会发生。但是在许多分布式数据库中,不同的分区独立运行,因此不存在全局写入顺序:当用户从数据库中读取数据时,可能会看到数据库的某些部分处于较旧的状态,而某些处于较新的状态。
一种解决方案是,确保任何因果相关的写入都写入相同的分区。对于某些无法高效完成这种操作的应用,还有一些显式跟踪因果依赖关系的算法。
Multi-Leader Replication
单个 Leader 的缺点在于,如果任何因素导致无法连接 Leader,那么你就无法向数据库写入任何数据了,这会让整个系统非常脆弱,所以我们在一些情境下需要多 Leader 的架构。
Use Cases for Multi-Leader Replication
下面是一些多 Leader 架构的示例
多个数据中心
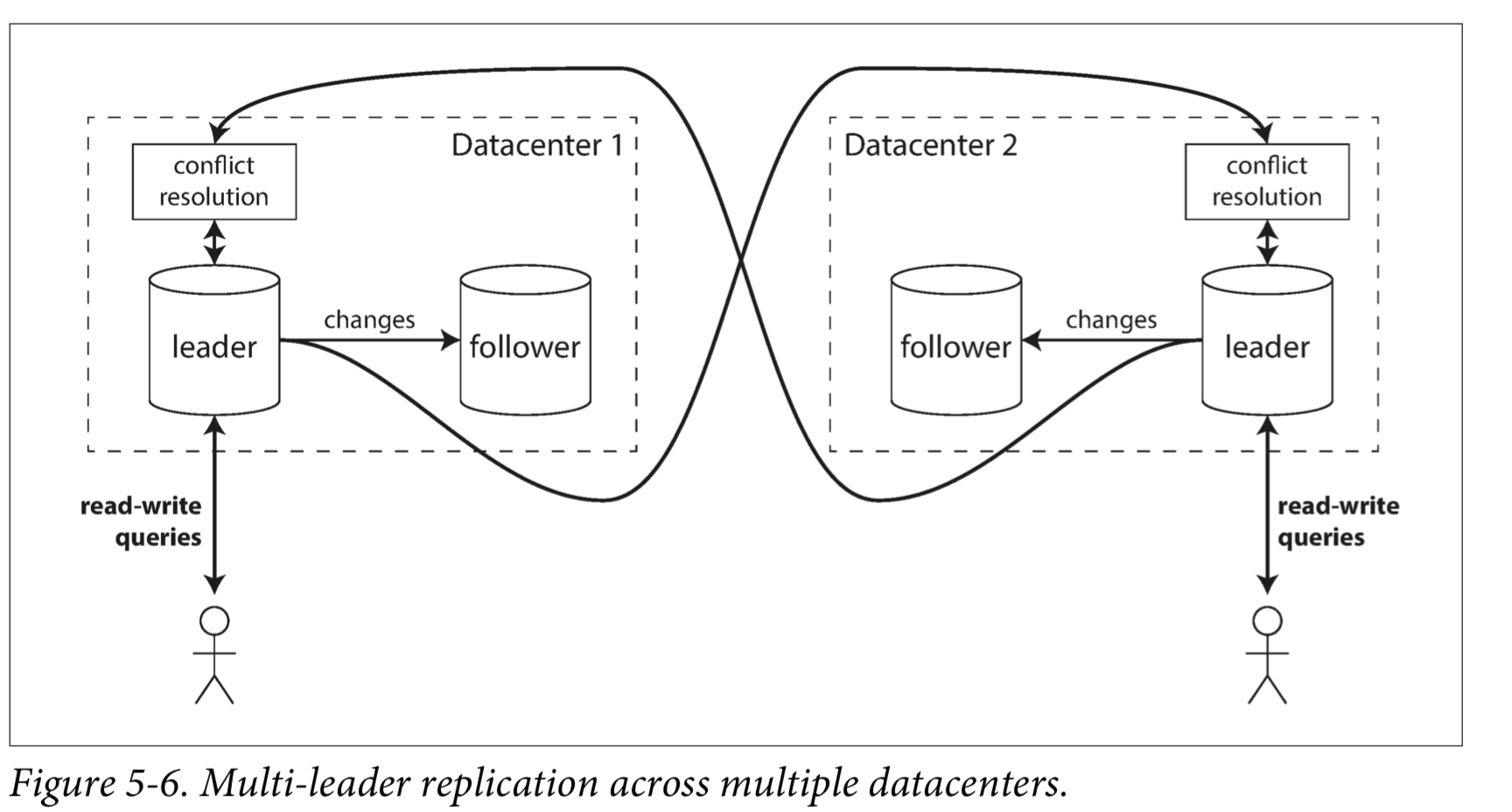
像上图这种情况,你可以有多个 Leader 分布在不同地方的数据中心,每个数据中心都是一个独立的集群,它们的 Leader 之间会相互同步数据。
可以离线的客户端
我们可以把一个支持离线运行的客户端,和服务器端,视为两个“数据中心”,比如一些日历应用,会在本地维护一份数据,直到有网络时,才会和服务器进行数据同步,这就是一个异步的多 Leader 架构。
CouchDB 就是为此设计的。
多人协作编辑
像 Etherpad、Google Docs 这样的应用,允许多人同时编辑同一份文档,每个人都是一个 “Leader”,相互之间同步数据,但这显然会遇到冲突的问题。
解决写冲突
多 Leader 之间同步数据,最大的问题就是如何解决写冲突。比如下图中,两个用户都修改了文档的标题,发请求给服务器,都返回了成功,但直到 Leader 之间进行同步时才发现之前的数据有冲突。

同步冲突检测
单 Leader 不会发生冲突,因为每次写入都是一个原子化的事务。
多 Leader 如果采用同步的方式检测冲突,也不会发生冲突。即每次写入时,都向其它的 Leader 检查有没有冲突,如果都没有冲突,那么写入成功。但这样性能极差,也丢掉了多 Leader 架构的好处,还不如用单个 Leader。
避免冲突
多 Leader 架构避免冲突最简单的方式就是,让可能产生冲突的请求,都走向同一个 Leader。比如对于同一项资料的修改,都路由到固定的某个 Leader 上。
这样做的缺陷在于,集群是不断变化的,很难做到长期固定,Leader 的变化就会让这个策略失效。
收敛至一致的状态
实现冲突合并解决有多种途径:
- 给每个写入一个唯一的ID(例如,一个时间戳,一个长的随机数,一个UUID或者一个键和值的哈希),挑选最高ID的写入作为胜利者,并丢弃其他写入。如果使用时间戳,这种技术被称为最后写入胜利(LWW, last write wins)。虽然这种方法很流行,但是很容易造成数据丢失。
- 为每个副本分配一个唯一的ID,ID编号更高的写入具有更高的优先级。这种方法也意味着数据丢失。
- 以某种方式将这些值合并在一起 - 例如,按字母顺序排序,然后连接它们(在图5-7中,合并的标题可能类似于“B/C”)。
- 在保留所有信息的显式数据结构中记录冲突,并编写解决冲突的应用程序代码(也许通过提示用户的方式)。
自定义冲突解决逻辑
作为解决冲突最合适的方法可能取决于应用程序,大多数多主复制工具允许使用应用程序代码编写冲突解决逻辑。该代码可以在写入或读取时执行。
自动冲突解决
冲突解决规则可能很快变得复杂,并且自定义代码可能容易出错。
已经有一些有趣的研究来自动解决由于数据修改引起的冲突。有几个研究值得一提:
- 无冲突复制数据类型(Conflict-free replicated datatypes)(CRDT)是可以由多个用户同时编辑的集合,映射,有序列表,计数器等的一系列数据结构,它们以合理的方式自动解决冲突。
- 可合并的持久数据结构(Mergeable persistent data structures)显式跟踪历史记录,类似于Git版本控制系统。
- 可执行的转换(operational transformation)是Etherpad和Google Docs等合作编辑应用背后的冲突解决算法。
这些算法在数据库中的实现还很年轻,但很可能将来它们将被集成到更多的复制数据系统中。自动冲突解决方案可以使应用程序处理多领导者数据同步更为简单。
多 Leader 的拓扑结构
多 Leader 可以有很多种拓扑结构,环形、星形、全连接形。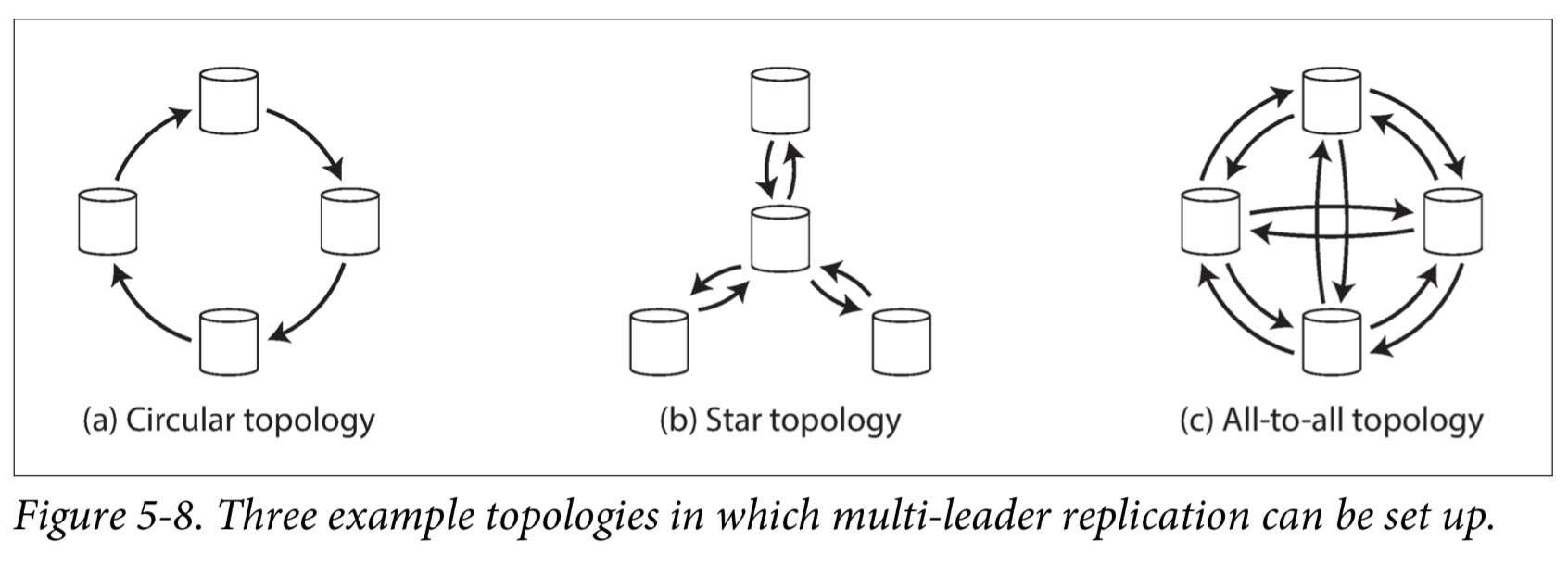
MySQL 使用的是环形连接。全连接形是最符合直觉的,每个 Leader 都和其它所有 Leader 相互交换数据。
另一方面,全连接形拓扑也可能有问题。特别是,一些网络链接可能比其他网络链接更快(例如,由于网络拥塞),结果是一些复制消息可能“超过”其他复制消息,如下图示。
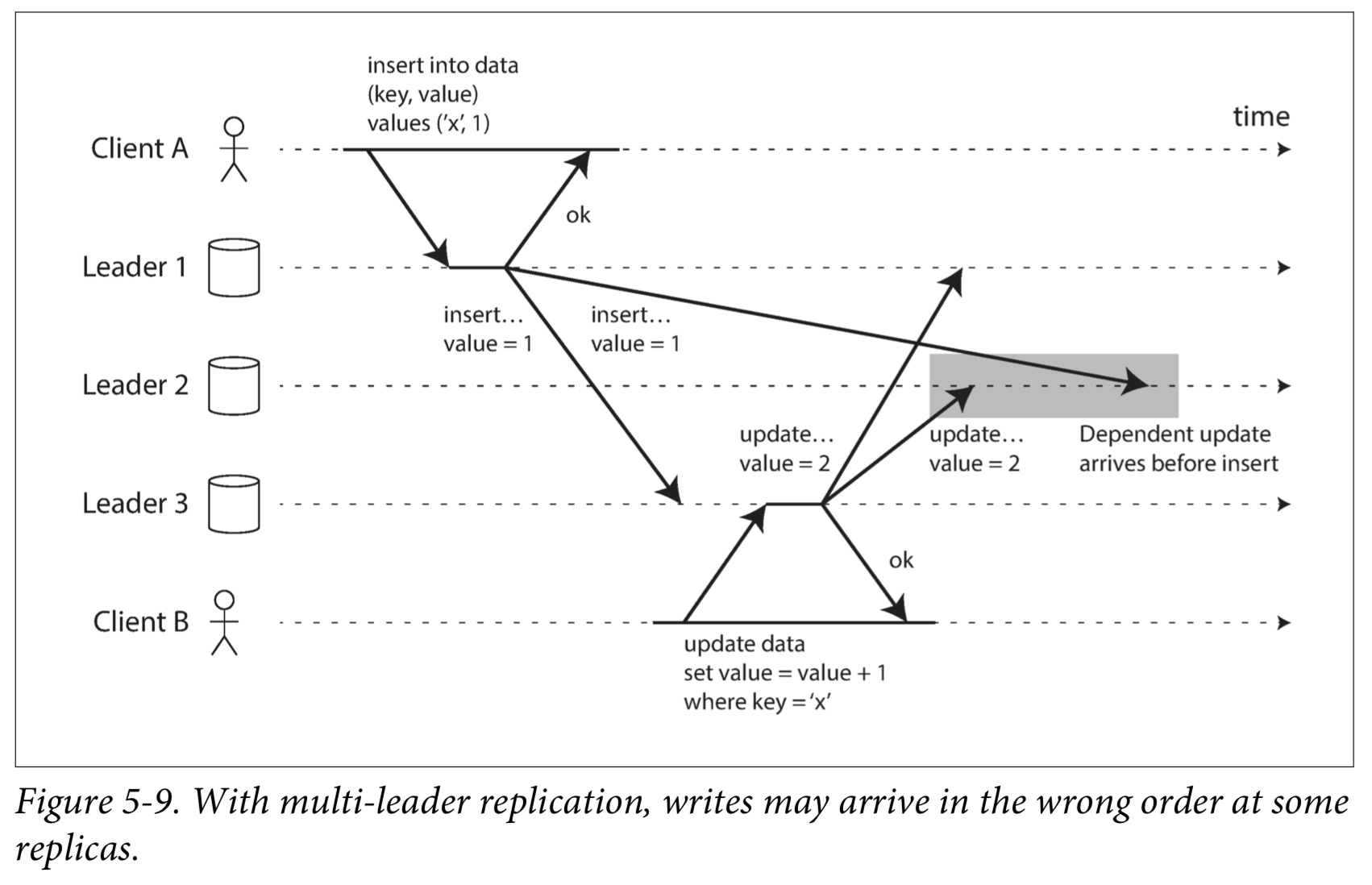
这是一个因果关系的问题:更新取决于先前的插入,所以我们需要确保所有节点先处理插入,然后再处理更新。
要正确排序这些事件,可以使用一种称为version vectors的技术。
无 Leader 复制
无 Leader 复制完全不需要 Leader 的存在,这种架构中,客户端可以向多个节点发起读写请求。
当有节点挂掉时,如何写入数据库
只要保证多个节点写入成功,那么客户端就可以认为写入成功。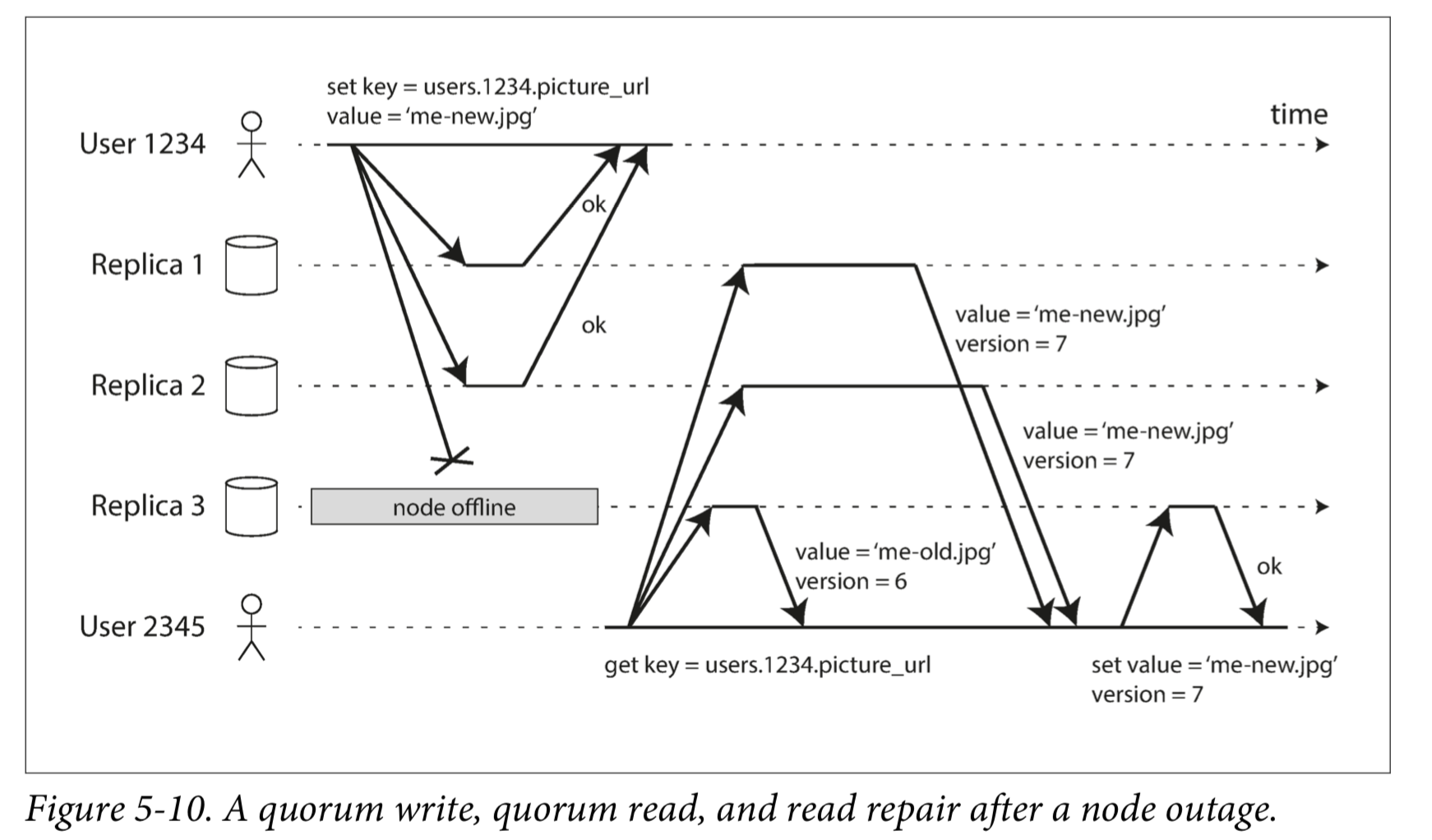
Read repair and anti-entropy
在读取的时候,可能会存在不一致(因为有部分节点写入失败),这时可以发现不一致并且修复它。或者所有节点都定期检查是否自己的数据跟别人有不一致的地方。
Quorums for reading and writing
如果有n个副本,每个写入必须由w节点确认才能被认为是成功的,并且我们必须至少为每个读查询r个节点。 只要w + r> n,我们期望在读取时获得最新的值,因为r个读取中至少有一个节点是最新的。
Quorums 机制的局限性
Sloppy Quorums and Hinted Handoff
sloppy quorum:写和读仍然需要w和r成功的响应,但是那些可能包括不在指定的n个“主”节点中的值。比方说,如果你把自己锁在房子外面,你可能会敲开邻居的门,问你是否可以暂时停留在沙发上。
一旦网络中断得到解决,代表另一个节点临时接受的一个节点的任何写入都被发送到适当的“本地”节点,这就是hinted handoff。 (一旦你再次找到你的房子的钥匙,你的邻居礼貌地要求你离开沙发回家。)
Detecting Concurrent Writes
Last write wins (discarding concurrent writes)
The “happens-before” relationship and concurrency
Capturing the happens-before relationship
Merging concurrently written values
Version vectors
参考资料: