Designing Data-Intensive Applications 读书笔记 -Partitioning
文章目录
partition在本文中的翻译为分区。
数据量非常大的时候,在单台机器上存储和处理不再可行,则分区十分必要。分区的目标是在多台机器上均匀分布数据和查询负载,避免出现热点(负载不成比例的节点)。这需要选择适合于您的数据的分区方案,并在将节点添加到集群或从集群删除时进行再分区。分区主要是为了可扩展性(scalability)。
Partitioning and Replication
分区通常与复制结合使用,使得每个分区的副本存储在多个节点上。 这意味着,即使每条记录属于一个分区,它仍然可以存储在多个不同的节点上以获得容错能力。
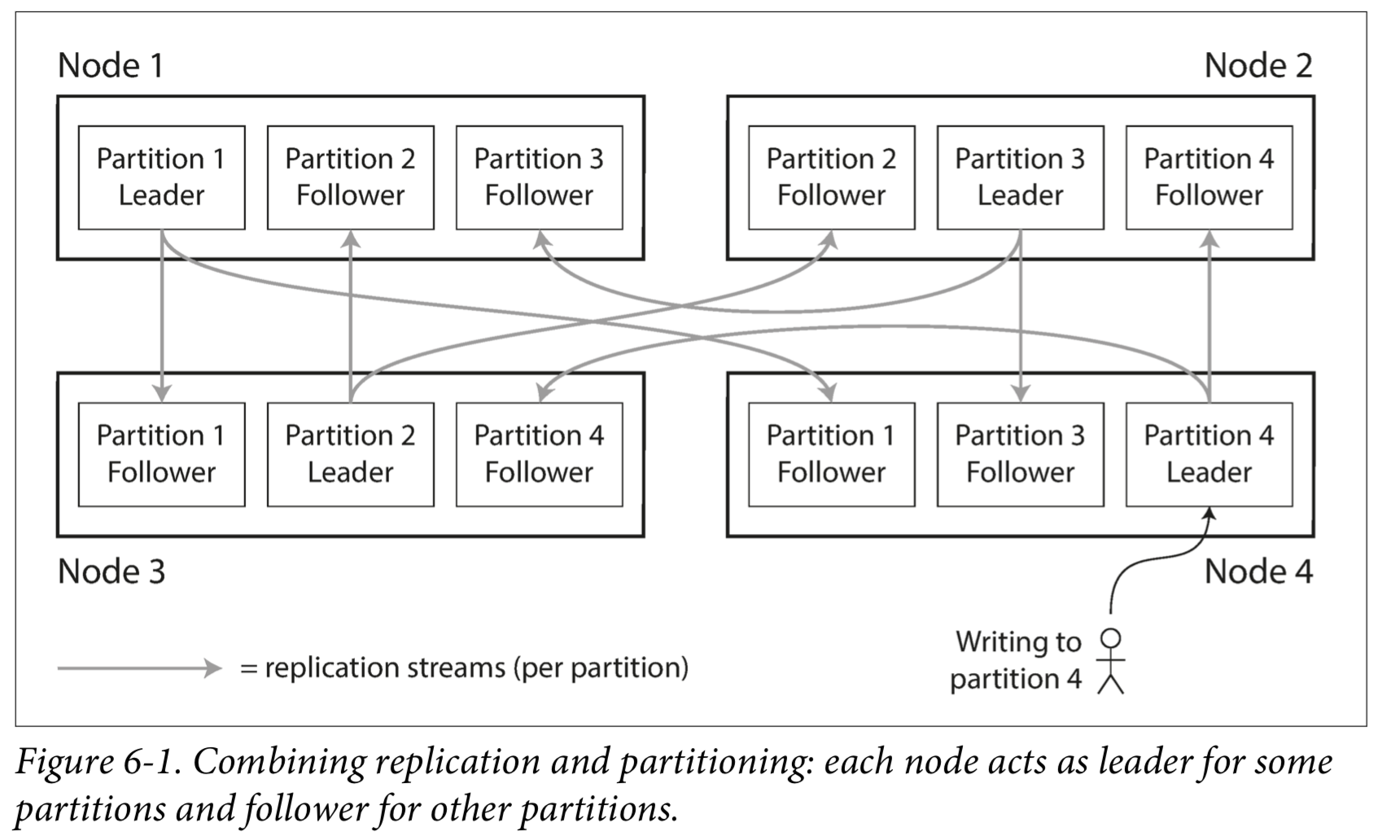
Partitioning of Key-Value Data
如果分区是不公平的,一些分区比其他分区有更多的数据或查询,我们称之为偏斜(skew)。数据偏斜的存在使分区效率下降很多。在极端的情况下,所有的负载可能压在一个分区上,其余节点空闲的,那么瓶颈落在这一个繁忙的节点上。不均衡导致的高负载的分区被称为热点(hot spot)。
避免热点最简单的方法是将记录随机分配给节点。这将在所有节点上平均分配数据,但是它有一个很大的缺点:当你试图读取一个特定的值时,你无法知道它在哪个节点上,所以你必须并行地查询所有的节点。
Partitioning by Key Range
一种分区的方法是为每个分区指定一块连续的键范围(从最小值到最大值),如果知道范围之间的边界,则可以轻松确定哪个分区包含某个值。

在每个分区中,我们可以按照一定的顺序保存键。优点是进行范围扫描非常简单,缺点是某些特定的访问模式会导致热点。
Partitioning by Hash of Key
一个好的散列函数可以将将偏斜的数据均匀分布。假设你有一个32位散列函数,无论何时给定一个新的字符串输入,它将返回一个0到2^{32}-1之间的”随机”数。即使输入的字符串非常相似,它们的散列也会均匀分布在这个数字范围内。
一旦你有一个合适的键散列函数,你可以为每个分区分配一个散列范围(而不是键的范围),每个通过哈希散列落在分区范围内的键将被存储在该分区中。如下图所示。

不幸的是,通过使用Key散列进行分区,我们失去了键范围分区的一个很好的属性:高效执行范围查询的能力。曾经相邻的Key现在分散在所有分区中,所以它们之间的顺序就丢失了。
Cassandra采取了折衷的策略。Cassandra中的表可以使用由多个列组成的复合主键来声明。键中只有第一列会作为散列的依据,而其他列则被用作Casssandra的SSTables中排序数据的连接索引。尽管查询无法在复合主键的第一列中按范围扫表,但如果第一列已经指定了固定值,则可以对该键的其他列执行有效的范围扫描。
Skewed Workloads and Relieving Hot Spots
在极端情况下,所有的读写操作都是针对同一个键的,所有的请求都会被路由到同一个分区。
如今,大多数数据系统无法自动补偿这种高度偏斜的负载,因此应用程序有责任减少偏斜。例如,如果一个主键被认为是非常火爆的,一个简单的方法是在主键的开始或结尾添加一个随机数。只要一个两位数的十进制随机数就可以将主键分散为100钟不同的主键,从而存储在不同的分区中。
Partitioning and Secondary Indexes
Partitioning Secondary Indexes by Document
按文档分区(本地索引),其中二级索引存储在与主键和值相同的分区中。这意味着只有一个分区需要在写入时更新,但是读取二级索引需要在所有分区之间进行scatter/gather。
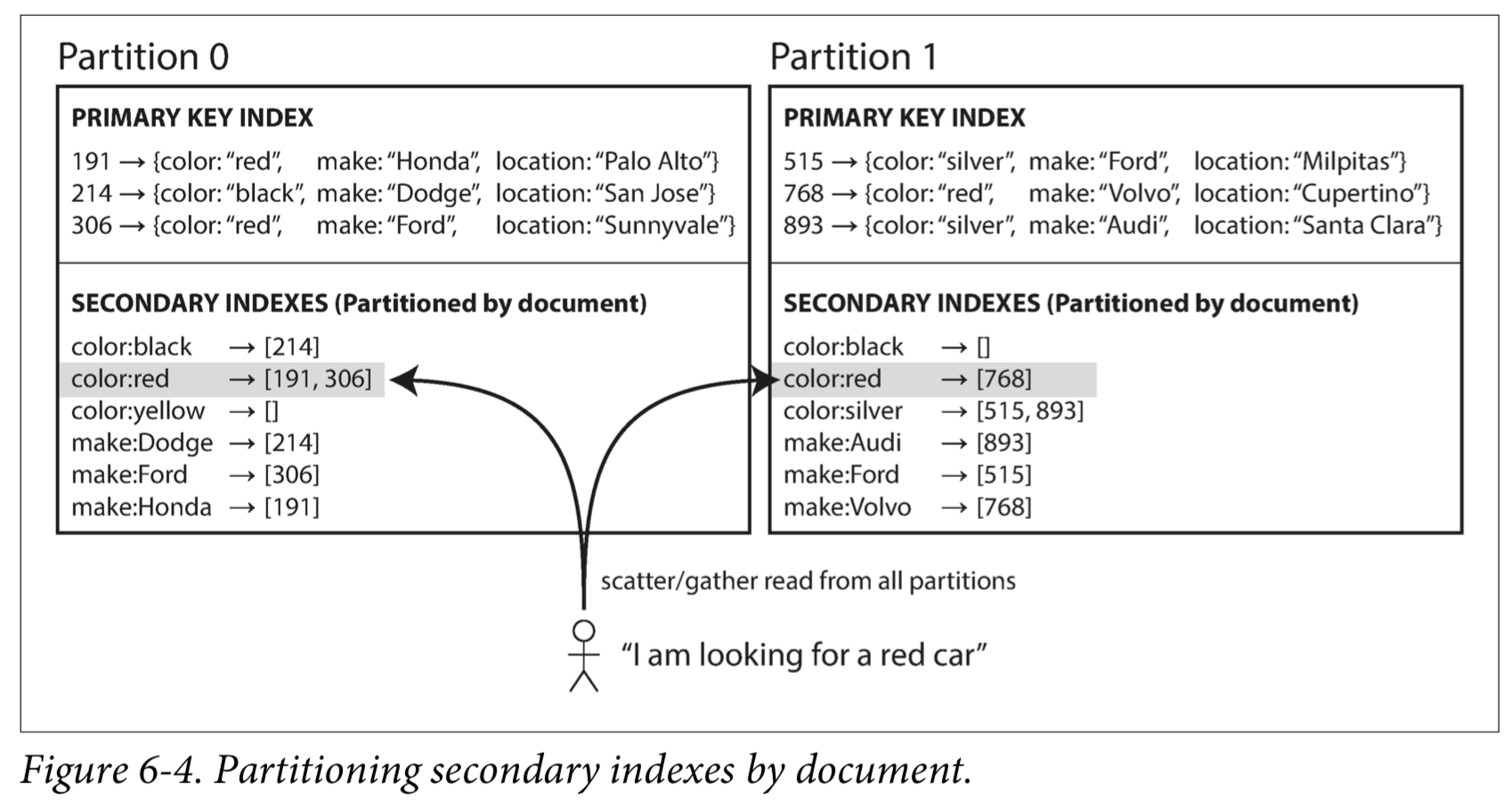
Partitioning Secondary Indexes by Term
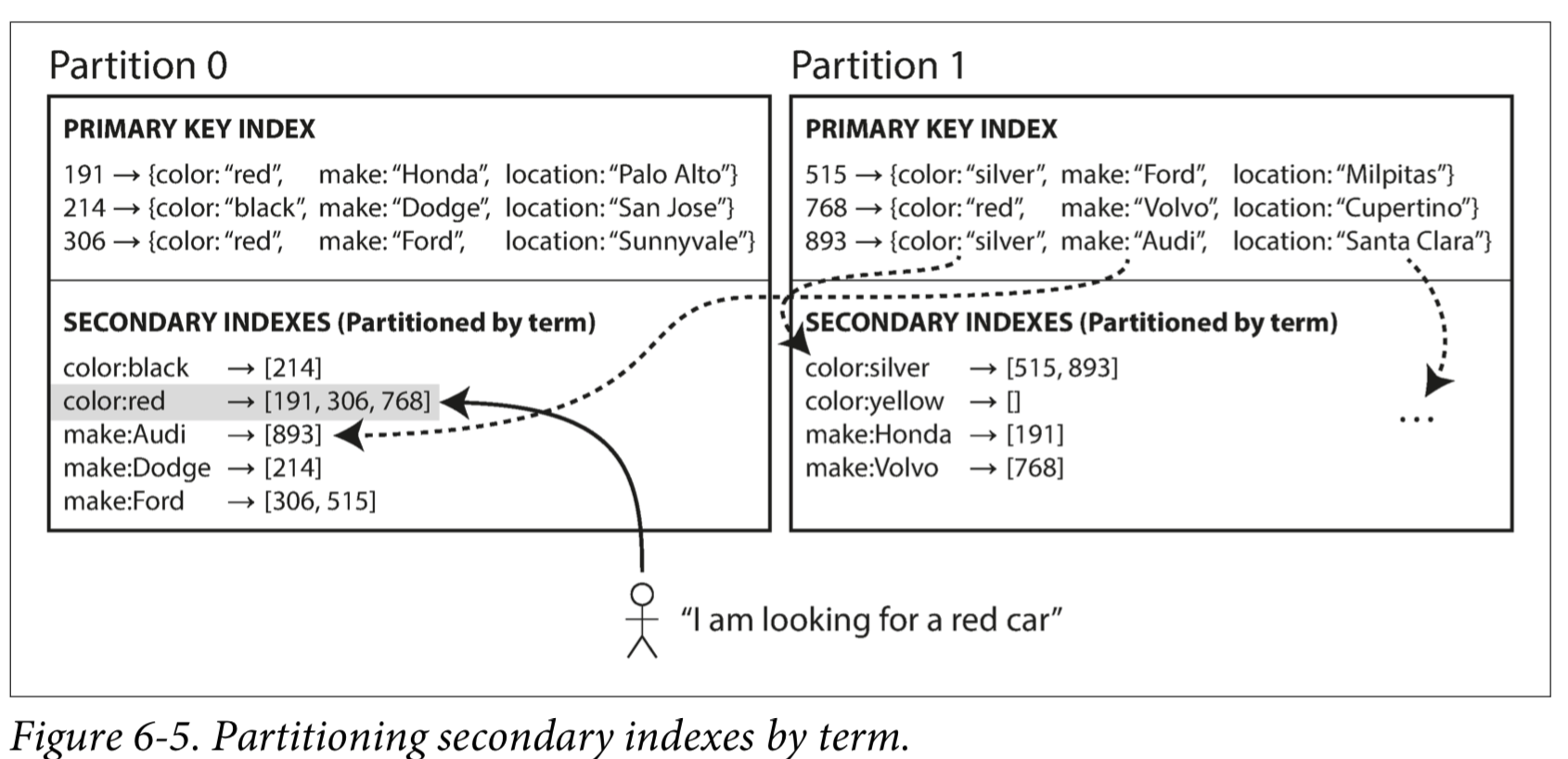
按关键词分区(全局索引),其中二级索引存在不同的分区的。当文档写入时,需要更新多个分区中的二级索引;但是可以从单个分区中进行读取
Rebalancing Partitions
随着时间的推移,数据库会有各种变化。如机器出现故障,其他机器需要接管故障机器。
这些更改需要将数据和请求从一个节点移动到另一个节点。 将load从集群中的一个节点向另一个节点移动的过程称为再平衡(reblancing)。
Strategies for Rebalancing
有几种不同的分区分配方法,让我们依次简要讨论一下。
反面教材:hash mod N
模N方法的问题是,如果节点数量N发生变化,大多数Key将需要从一个节点移动到另一个节点。如此频繁的移动使得重新平衡的代价过于昂贵。
我们需要一种只移动必需数据的方法。
固定数量的分区
创建比节点更多的分区,并为每个节点分配多个分区。例如,运行在10个节点的集群上的数据库可能会从一开始就被拆分为1,000个分区,因此大约有100个分区被分配给每个节点。
现在,如果一个节点被添加到集群中,新节点可以从当前每个节点中窃取一些分区,直到分区再次公平分配。这个过程下图所示。
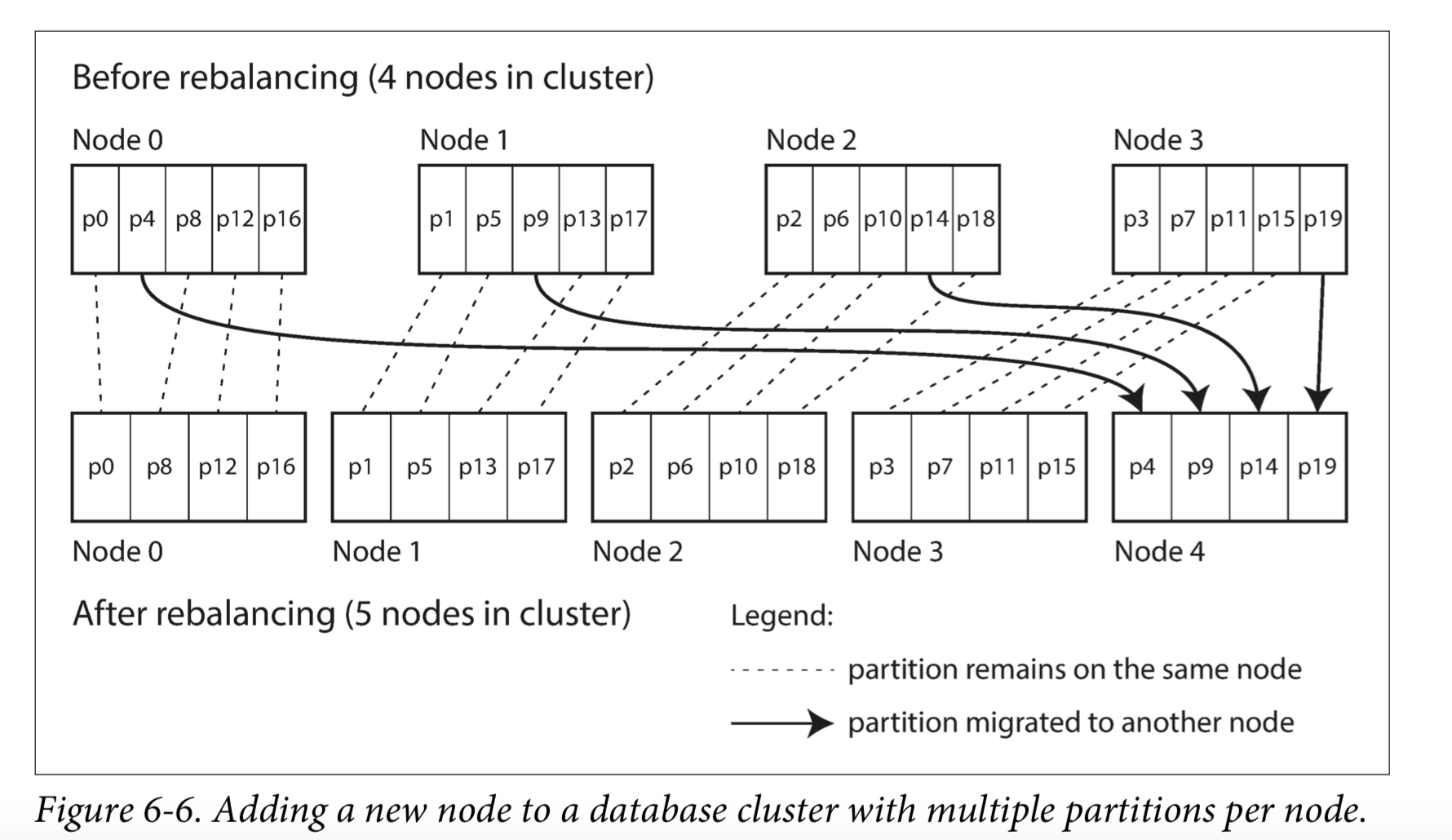
如果数据集的总大小难以预估(例如,如果它开始很小,但随着时间的推移可能会变得更大),选择正确的分区数是困难的。由于每个分区包含了总数据量固定比率的数据,因此每个分区的大小与集群中的数据总量成比例增长。如果分区非常大,再平衡和从节点故障恢复变得昂贵。但是,如果分区太小,则会产生太多的开销。当分区大小“恰到好处”的时候才能获得很好的性能,如果分区数量固定,但数据量变动很大,则难以达到最佳性能。
动态分区
对于使用键范围分区的数据库,具有固定边界的固定数量的分区将非常不便,手动重新配置分区边界将非常繁琐。
出于这个原因,按键的范围进行分区的数据库(如HBase)会动态创建分区。当分区增长到超过配置的大小时(在HBase上,默认值是10GB),会被分成两个分区,每个分区约占一半的数据。与之相反,如果大量数据被删除并且分区缩小到某个阈值以下,则可以将其与相邻分区合并。
动态分区的一个优点是分区数量适应总数据量。如果只有少量的数据,少量的分区就足够了,所以开销很小;如果有大量的数据,每个分区的大小被限制在一个可配置的最大值。
动态分区不仅适用于数据的范围分区,而且也适用于hash分区。
Partitioning proportionally to nodes
每个节点具有固定数量的分区,在这种情况下,每个分区的大小与数据集大小成比例地增长,而节点数量保持不变,但是当增加节点数时,分区将再次变小。由于较大的数据量通常需要较大数量的节点进行存储,因此这种方法也使每个分区的大小较为稳定。
Request Routing
现在我们已经将数据集分割到多个机器上运行的多个节点上。但是仍然存在一个悬而未决的问题:当客户想要发出请求时,如何知道要连接哪个节点?随着分区重新平衡,分区对节点的分配也发生变化。为了回答这个问题,需要有人知晓这些变化:如果我想读或写键“foo”,需要连接哪个IP地址和端口号?
这个问题可以概括为 服务发现(service discovery) 。
概括来说,这个问题有几种不同的方案(如下图所示):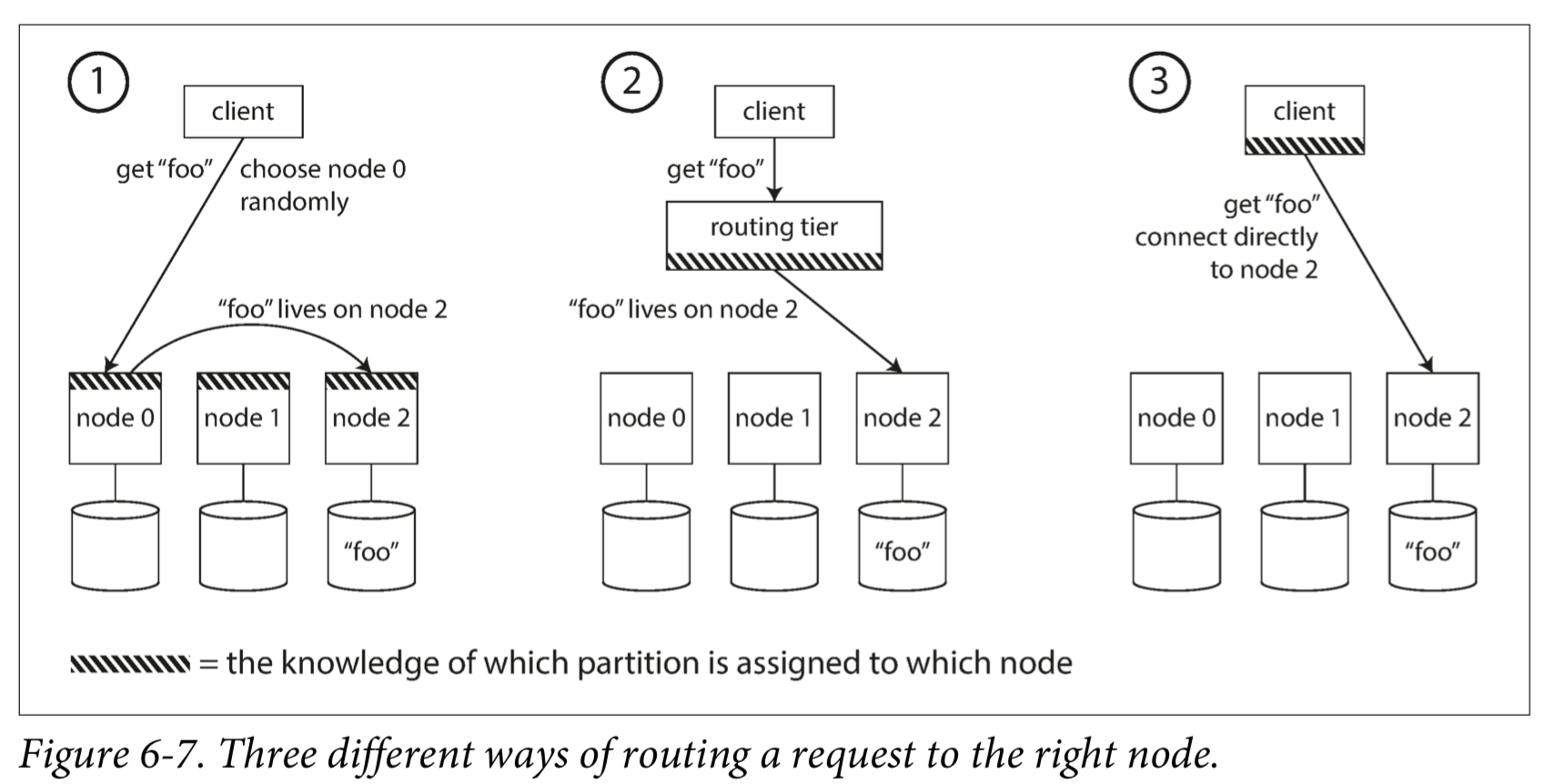
- 允许客户联系任何节点(例如,通过循环策略的负载均衡(Round-Robin Load Balancer))。如果该节点恰巧拥有请求的分区,则它可以直接处理该请求;否则,它将请求转发到适当的节点,接收回复并传递给客户端。
- 首先将所有来自客户端的请求发送到路由层,它决定了应该处理请求的节点,并相应地转发。此路由层本身不处理任何请求,它仅负责分区的负载均衡。
- 要求客户端知道分区和节点的分配。在这种情况下,客户端可以直接连接到适当的节点,而不需要任何中介。
以上所有情况中的关键问题是:作出路由决策的组件(可能是节点之一,还是路由层或客户端)如何了解分区-节点之间的分配关系变化?
许多分布式数据系统都依赖于一个独立的协调服务,比如用ZooKeeper来跟踪集群元数据,如下图所示。
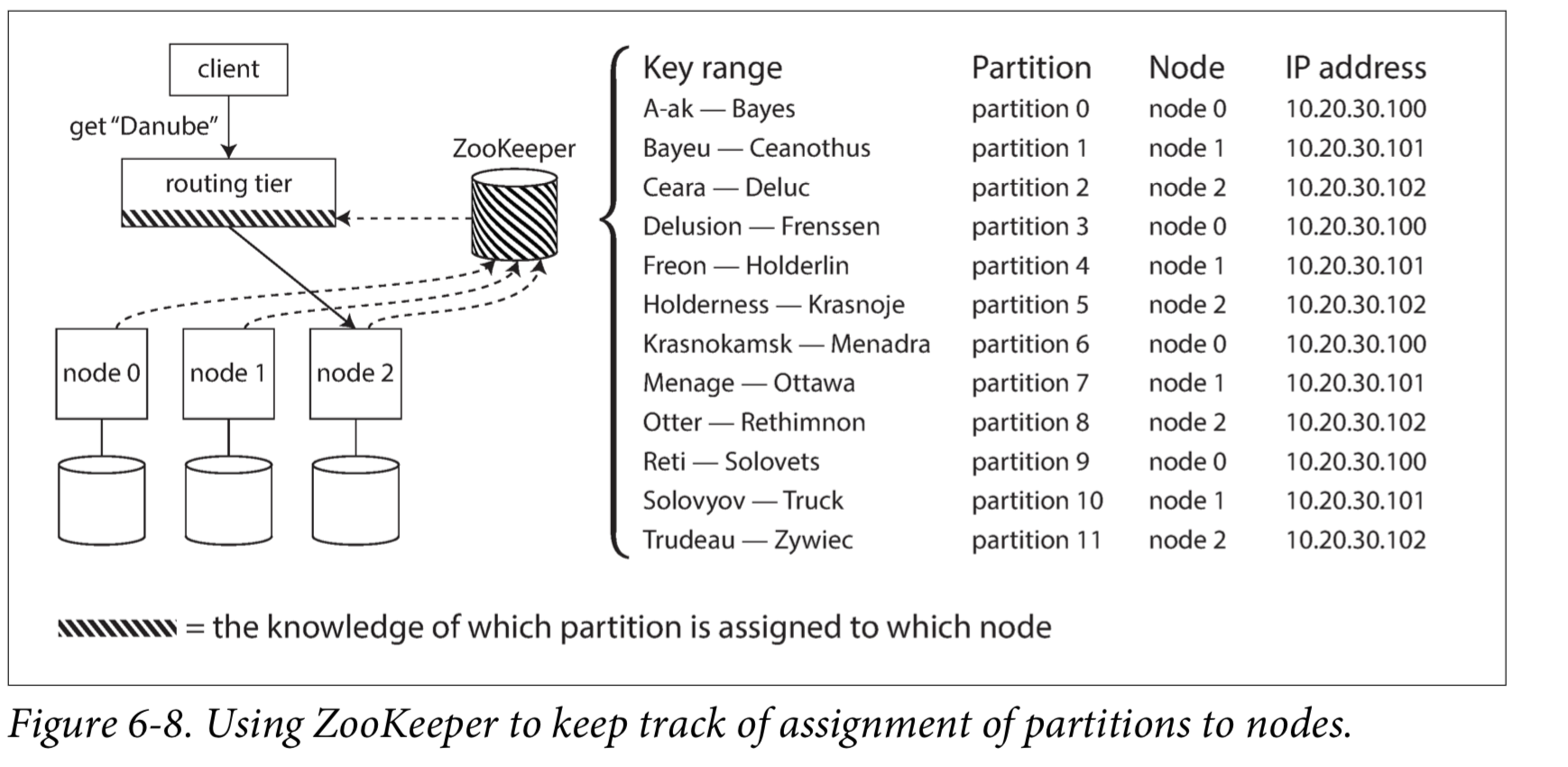
每个节点在ZooKeeper中注册自己,ZooKeeper维护分区到节点的可靠映射。 其他参与者(如路由层或分区感知客户端)可以在ZooKeeper中订阅此信息。 只要分区分配发生的改变,或者集群中添加或删除了一个节点,ZooKeeper就会通知路由层使路由信息保持最新状态。
Cassandra和Riak采取不同的方法:他们在节点之间使用流言协议(gossip protocol) 来传播群集状态的变化。请求可以发送到任意节点,该节点会转发到包含所请求的分区的适当节点(图Figure 6-7中的方法1)。这个模型在数据库节点中增加了更多的复杂性,但是避免了对像ZooKeeper这样的外部协调服务的依赖。
参考资料: