Designing Data-Intensive Applications 读书笔记 -Transactions
文章目录
The Slippery Concept of a Transaction
The Meaning of ACID
Systems that do not meet the ACID criteria are sometimes called BASE, which stands for Basically Available, Soft state, and Eventual consistency.
Atomicity
ACID atomicity describes what happens if a client wants to make several writes, but a fault occurs after some of the writes have been processed.
Consistency
The word consistency is terribly overloaded:
- replica consistency and the issue of eventual consistency that arises in asynchronously replicated systems.
- Consistent hashing is an approach to partitioning that some systems use for rebalancing.
- In the CAP theorem , the word consistency is used to mean linearizability.
The idea of ACID consistency is that you have certain statements about your data (invariants) that must always be true.
Isolation
Most databases are accessed by several clients at the same time. That is no problem if they are reading and writing different parts of the database, but if they are accessing the same database records, you can run into concurrency problems (race conditions).
ACID意义上的隔离性意味着,同时执行的事务是相互隔离的:它们不能相互冒犯。
Durability
持久性 是一个承诺,即一旦事务成功完成,即使发生硬件故障或数据库崩溃,写入的任何数据也不会丢失。
Single-Object and Multi-Object Operations
图7-2展示了一个来自邮件应用的例子。执行以下查询来显示用户未读邮件数量:1
SELECT COUNT(*) FROM emails WHERE recipient_id = 2 AND unread_flag = true
但如果邮件太多,你可能会觉得这个查询太慢,并决定用单独的字段存储未读邮件的数量。现在每当一个新消息写入时,也必须增长未读计数器,每当一个消息被标记为已读时,也必须减少未读计数器。
在图7-2中,用户2 遇到异常情况:邮件列表里显示有未读消息,但计数器显示为零未读消息,因为计数器增长还没有发生。隔离性可以避免这个问题:通过确保用户2要么同时看到新邮件和增长后的计数器,要么都看不到,反正不会看到执行到一半的中间结果。
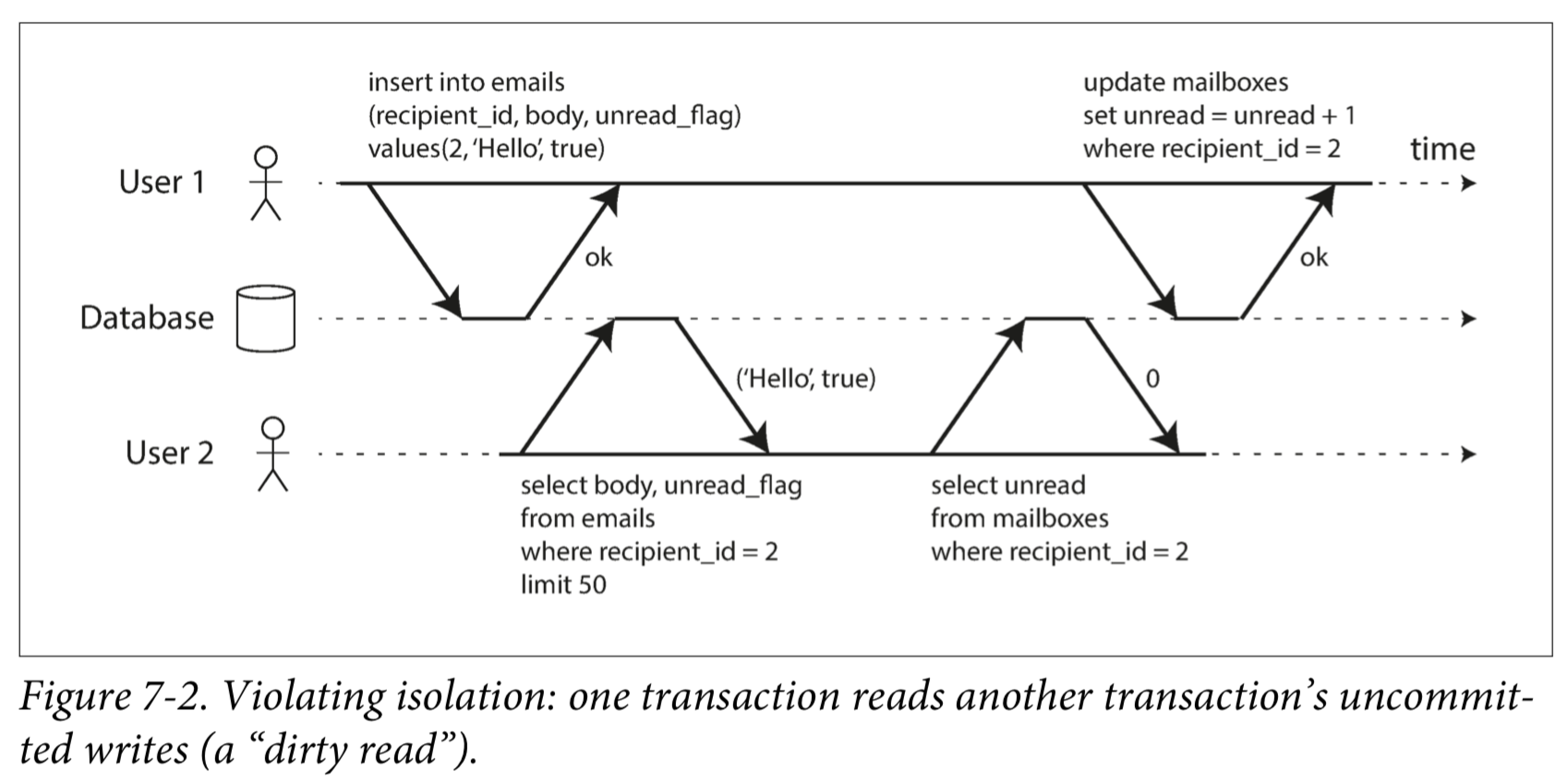
图7-3说明了对原子性的需求:如果在事务过程中发生错误,邮箱和未读计数器的内容可能会失去同步。在原子事务中,如果对计数器的更新失败,事务将被中止,并且插入的电子邮件将被回滚。
A transaction is usually understood as a mechanism for grouping multiple operations on multiple objects into one unit of execution.
Weak Isolation Levels
如果两个事务不触及相同的数据,它们可以安全地并行(parallel) 运行,因为两者都不依赖于另一个。当一个事务读取由另一个事务同时修改的数据时,或者当两个事务试图同时修改相同的数据时,并发问题(竞争条件)才会出现。
Read Committed
The most basic level of transaction isolation is read committed.It makes two guarantees:
- When reading from the database, you will only see data that has been committed (no dirty reads).
- When writing to the database, you will only overwrite data that has been committed (no dirty writes).
No dirty reads
Imagine a transaction has written some data to the database, but the transaction has not yet committed or aborted. Can another transaction see that uncommitted data? If yes, that is called a dirty read.
No dirty writes
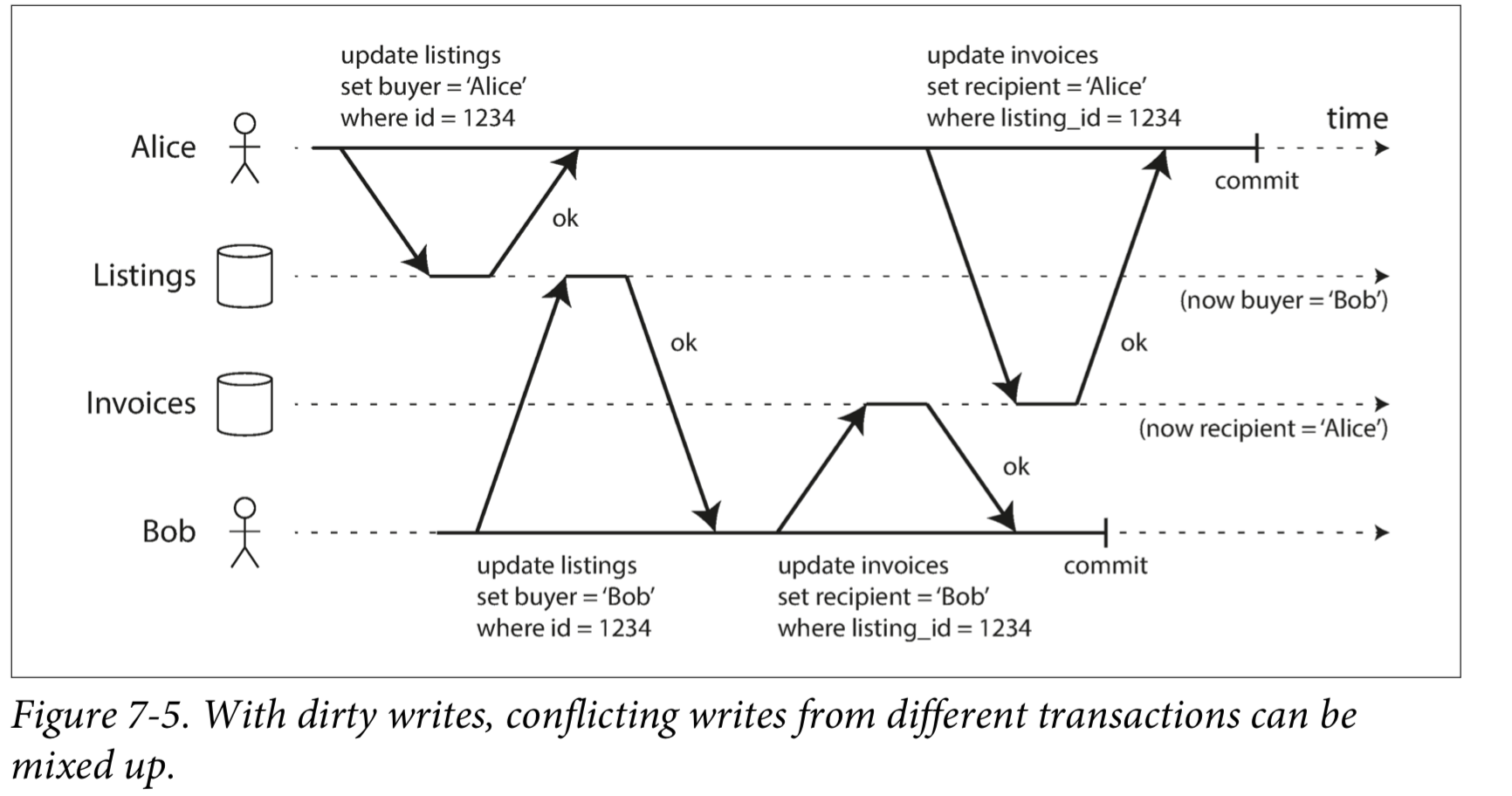
What happens if two transactions concurrently try to update the same object in a database? We don’t know in which order the writes will happen, but we normally assume that the later write overwrites the earlier write.
However, what happens if the earlier write is part of a transaction that has not yet committed, so the later write overwrites an uncommitted value? This is called a dirty write. Transactions running at the read committed isolation level must prevent dirty writes, usually by delaying the second write until the first write’s transaction has committed or aborted.
Implementing read committed
Most commonly, databases prevent dirty writes by using row-level locks.
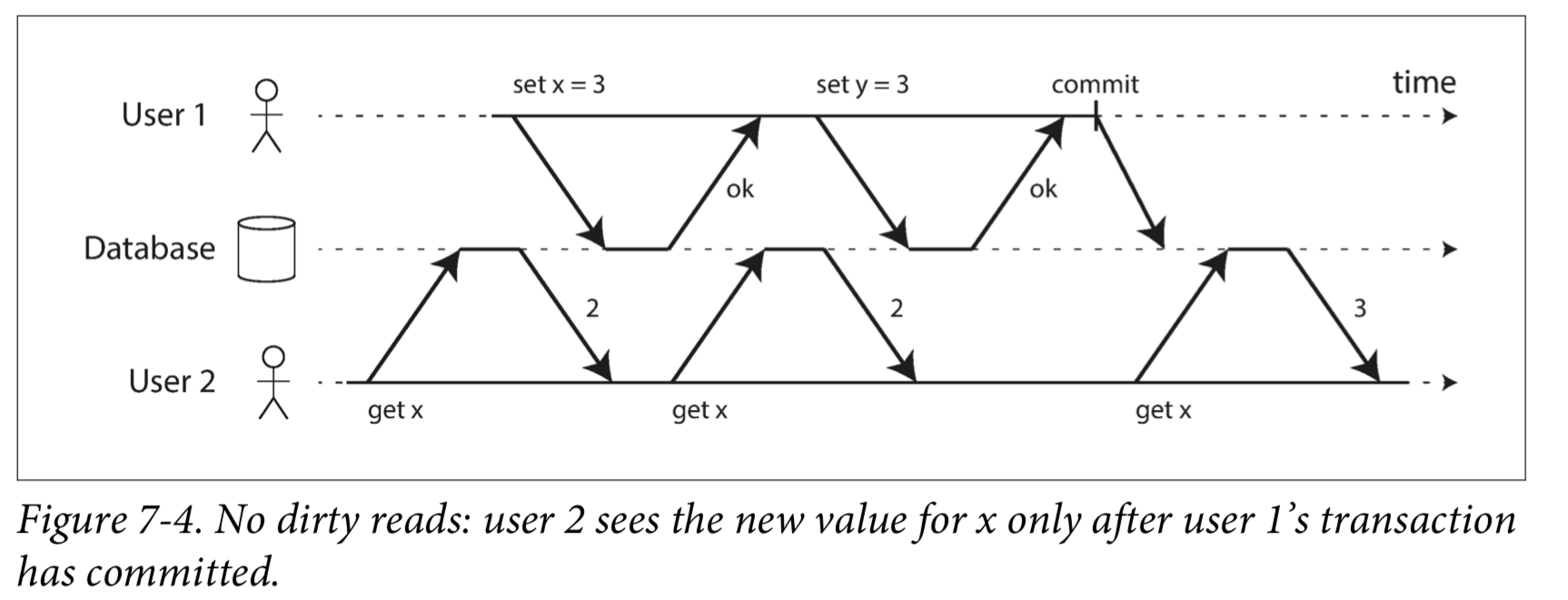
Most databases prevent dirty reads using the approach illustrated in Figure 7-4: for every object that is written, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock.
Snapshot Isolation
在PostgreSQL and MySQL中,Snapshot Isolation即为Repeatable Read。
图7-6说明了read committed可能发生的问题。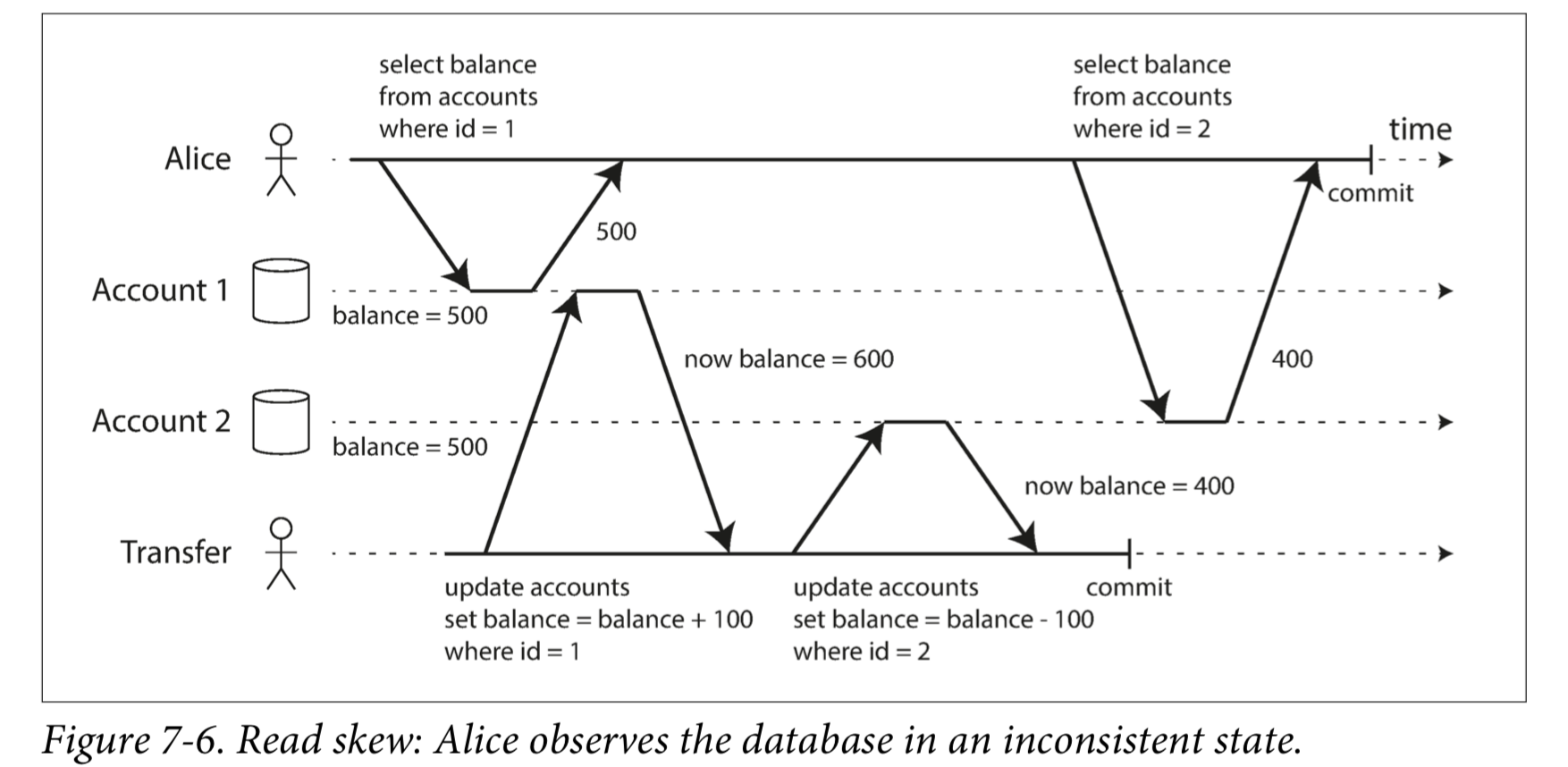
这种异常被称为不可重复读(nonrepeatable read)或读取偏差(read skew)。
Snapshot isolation能解决read skew问题。The idea is that each transaction reads from a consistent snapshot of the database—that is, the transaction sees all the data that was committed in the database at the start of the transaction. Even if the data is subsequently changed by another transaction, each transaction sees only the old data from that particular point in time.
Implementing snapshot isolation
A key principle of snapshot isolation is readers never block writers, and writers never block readers.
The database must potentially keep several different committed versions of an object, because various in-progress transactions may need to see the state of the database at different points in time. Because it maintains several versions of an object side by side, this technique is known as multi-version concurrency control(MVCC).
图7-7说明了如何在PostgreSQL中实现基于MVCC的快照隔离。当一个事务开始时,它被赋予一个唯一的事务ID。每当事务向数据库写入任何内容时,它所写入的数据都会被标记上写入者的事务ID。
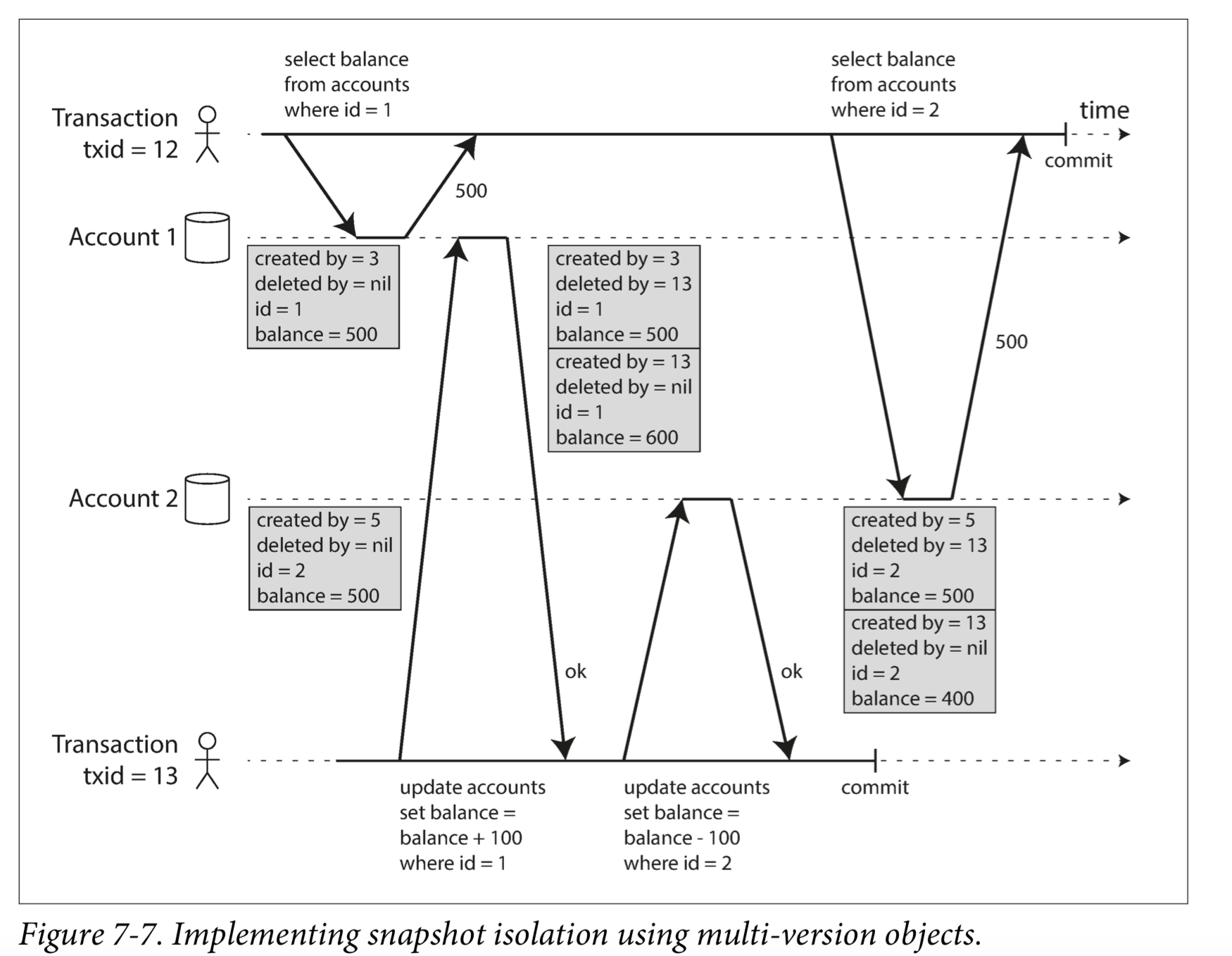
Visibility rules for observing a consistent snapshot
When a transaction reads from the database, transaction IDs are used to decide which objects it can see and which are invisible. By carefully defining visibility rules,the database can present a consistent snapshot of the database to the application.
Indexes and snapshot isolation
Preventing Lost Updates
到目前为止已经讨论的read committed和snapshot isolation级别,主要保证了只读事务在并发写入时可以看到什么。却忽略了两个事务并发写入的问题——我们只讨论了脏写。
并发的写入事务之间还有其他几种有趣的冲突。其中最着名的是丢失更新(lost update) 问题,如下图所示,以两个并发计数器增量为例。
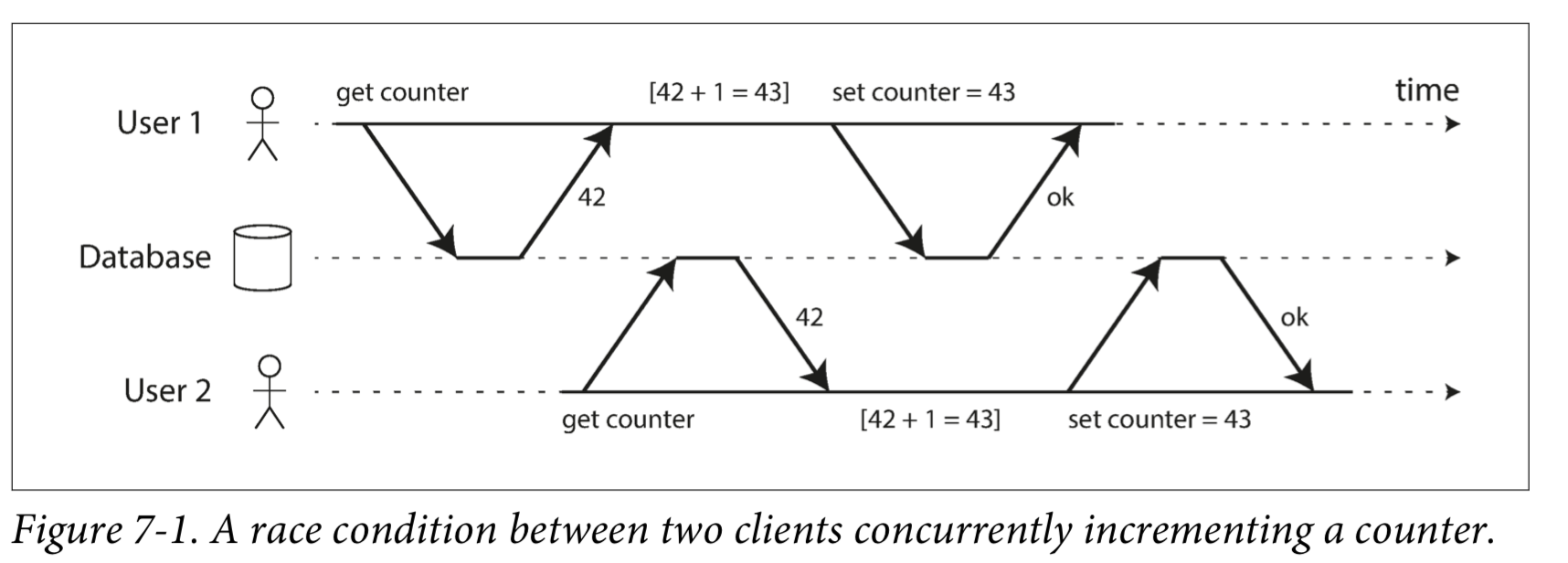
The lost update problem can occur if an application reads some value from the database, modifies it, and writes back the modified value (a read-modify-write cycle). If two transactions do this concurrently, one of the modifications can be lost, because the second write does not include the first modification.
Because this is such a common problem, a variety of solutions have been developed.
Atomic write operations
Many databases provide atomic update operations, which remove the need to implement read-modify-write cycles in application code.
Explicit locking
Another option for preventing lost updates, if the database’s built-in atomic operations don’t provide the necessary functionality, is for the application to explicitly lock objects that are going to be updated.

Automatically detecting lost updates
Atomic operations and locks are ways of preventing lost updates by forcing the read-modify-write cycles to happen sequentially. An alternative is to allow them to execute in parallel and, if the transaction manager detects a lost update, abort the transaction and force it to retry its read-modify-write cycle.
Compare-and-set(CAS)
In databases that don’t provide transactions, you sometimes find an atomic compare-and-set operation. The purpose of this operation is to avoid lost updates by allowing an update to happen only if the value has not changed since you last read it. If the current value does not match what you previously read, the update has no effect, and the read-modify-write cycle must be retried.
For example, to prevent two users concurrently updating the same wiki page, you might try something like this, expecting the update to occur only if the content of the page hasn’t changed since the user started editing it:

Conflict resolution and replication
Locks and compare-and-set operations assume that there is a single up-to-date copy of the data. However, databases with multi-leader or leaderless replication usually allow several writes to happen concurrently and replicate them asynchronously, so they cannot guarantee that there is a single up-to-date copy of the data. Thus, techniques based on locks or CAS do not apply in this context.
Write Skew and Phantoms
phantoms在本文中的含义是幻读。
想象一下这个例子:你正在为医院写一个医生轮班管理程序。医院通常会同时要求几位医生值班,但底线是至少有一位医生在值班。医生可以放弃他们的班次(例如,如果他们自己生病了),只要至少有一个同事在这一班中继续工作。
现在想象一下,Alice和Bob是两位值班医生。两人都感到不适,所以他们都决定请假。不幸的是,他们恰好在同一时间点击按钮下班。图7-8说明了接下来的事情。
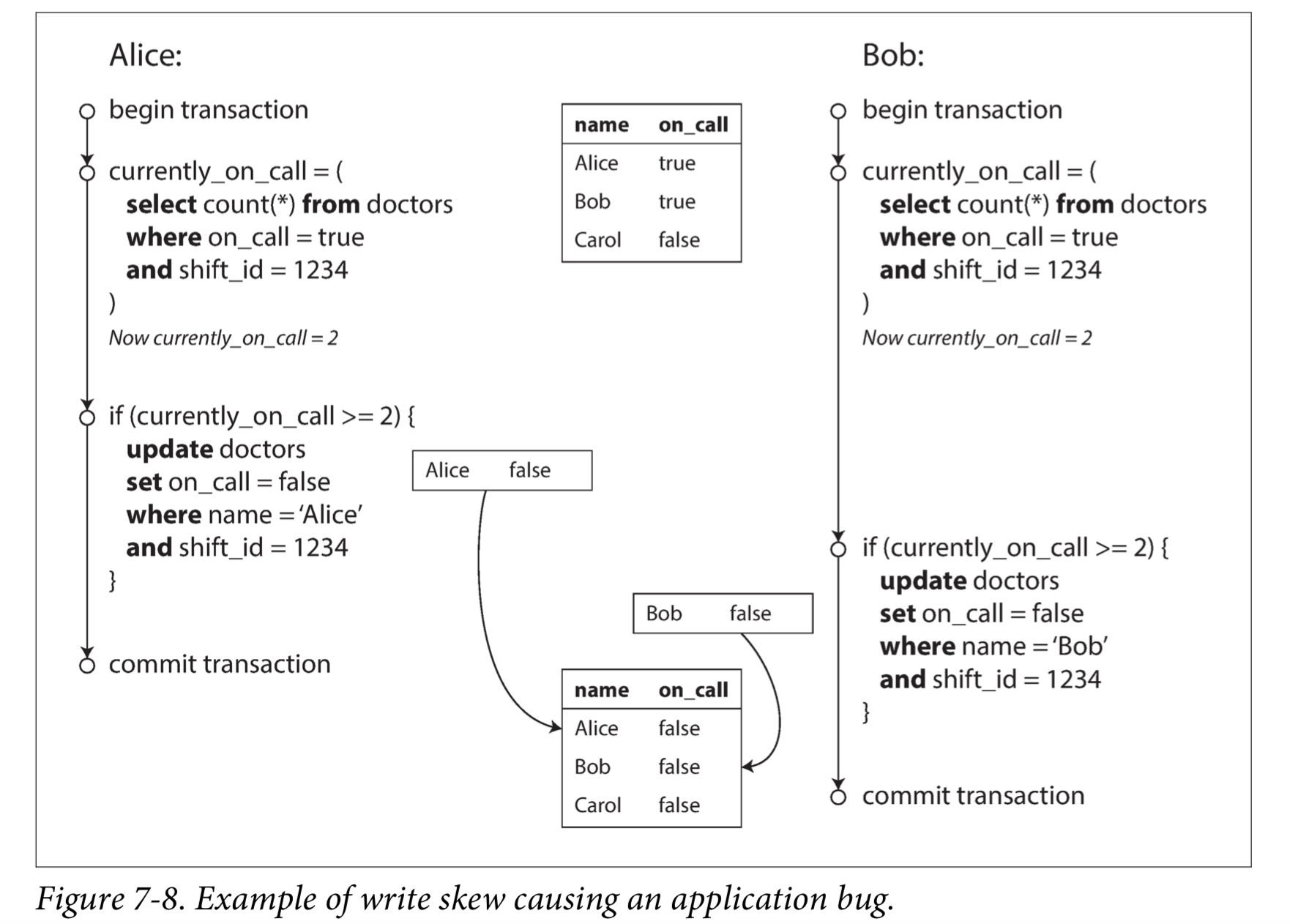
在两个事务中,应用首先检查是否有两个或以上的医生正在值班;如果是的话,它就假定一名医生可以安全地休班。由于数据库使用Snapshot Isolation,两次检查都返回 2 ,所以两个事务都进入下一个阶段。Alice更新自己的记录休班了,而Bob也做了一样的事情。两个事务都成功提交了,现在没有医生值班了。违反了至少有一名医生在值班的要求。
Characterizing write skew
这种异常称为 write skew.
Write skew can occur if two transactions read the same objects, and then update some of those objects (different transactions may update different objects). In the special case where different transactions update the same object, you get a dirty write or lost update anomaly (depending on the timing).
More examples of write skew
Phantoms causing write skew
This effect, where a write in one transaction changes the result of a search query in another transaction, is called a phantom.
Serializability
目前大多数提供可序列化的数据库都使用了三种技术。
Actual Serial Execution
If you can make each transaction very fast to execute, and the transaction throughput is low enough to process on a single CPU core, this is a simple and effective option.
Two-Phase Locking (2PL)
Implementation of two-phase locking
After a transaction has acquired the lock, it must continue to hold the lock until the end of the transaction (commit or abort). This is where the name “two-phase” comes from: the first phase (while the transaction is executing) is when the locks are acquired, and the second phase (at the end of the transaction) is when all the locks are released.
Serializable Snapshot Isolation (SSI)
Pessimistic versus optimistic concurrency control
Two-phase locking is a so-called pessimistic concurrency control mechanism.
Serializable snapshot isolation is an optimistic concurrency control technique.
SSI is based on snapshot isolation—that is, all reads within a transaction are made from a consistent snapshot of the database. This is the main difference compared to earlier optimistic concurrency control techniques. On top of snapshot isolation, SSI adds an algorithm for detecting serialization conflicts among writes and determining which transactions to abort.
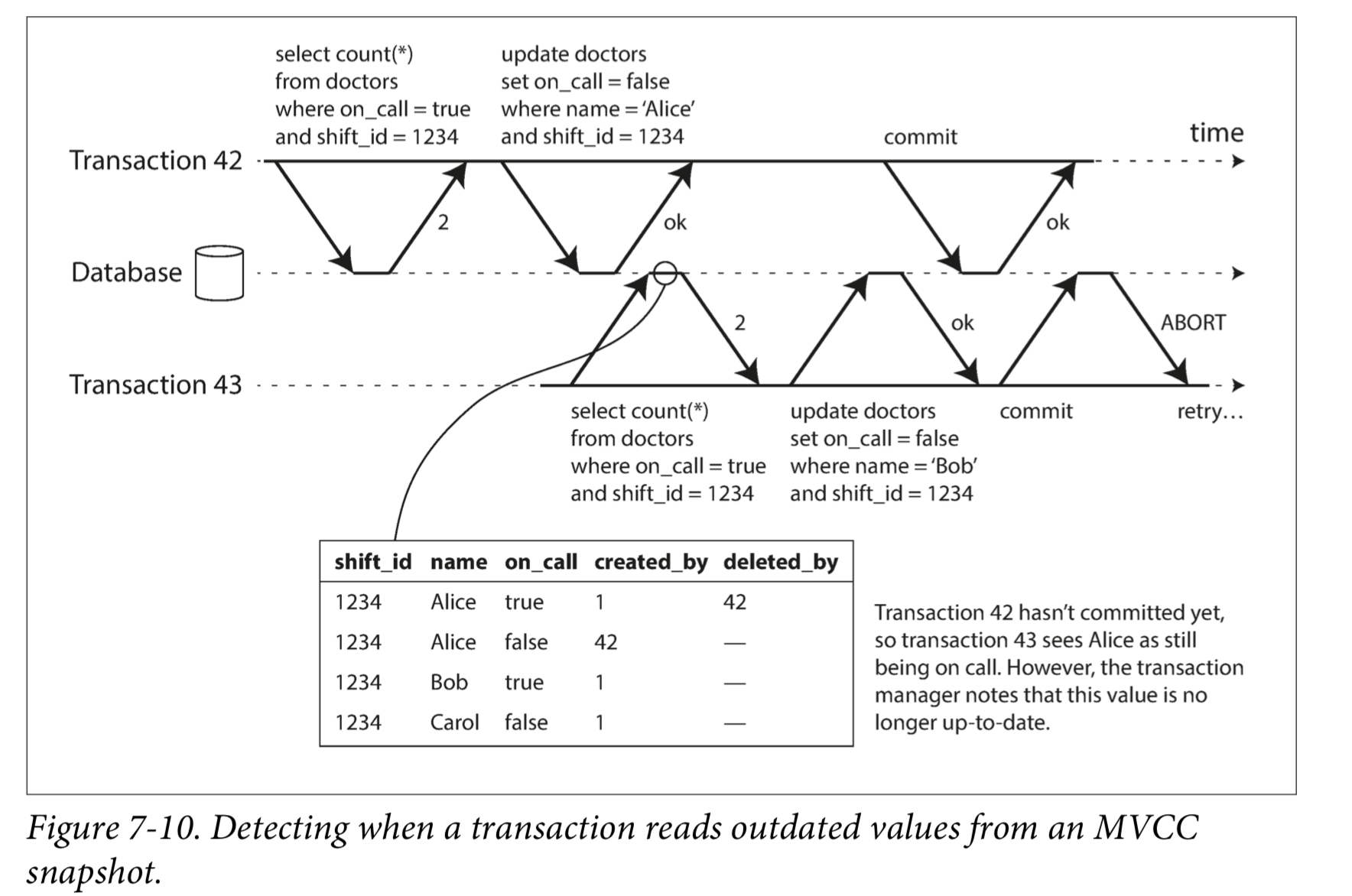
In order to provide serializable isolation, the database must detect situations in which a transaction may have acted on an outdated premise and abort the transaction in that case.
How does the database know if a query result might have changed? There are two cases to consider:
- Detecting reads of a stale MVCC object version (uncommitted write occurred before the read)
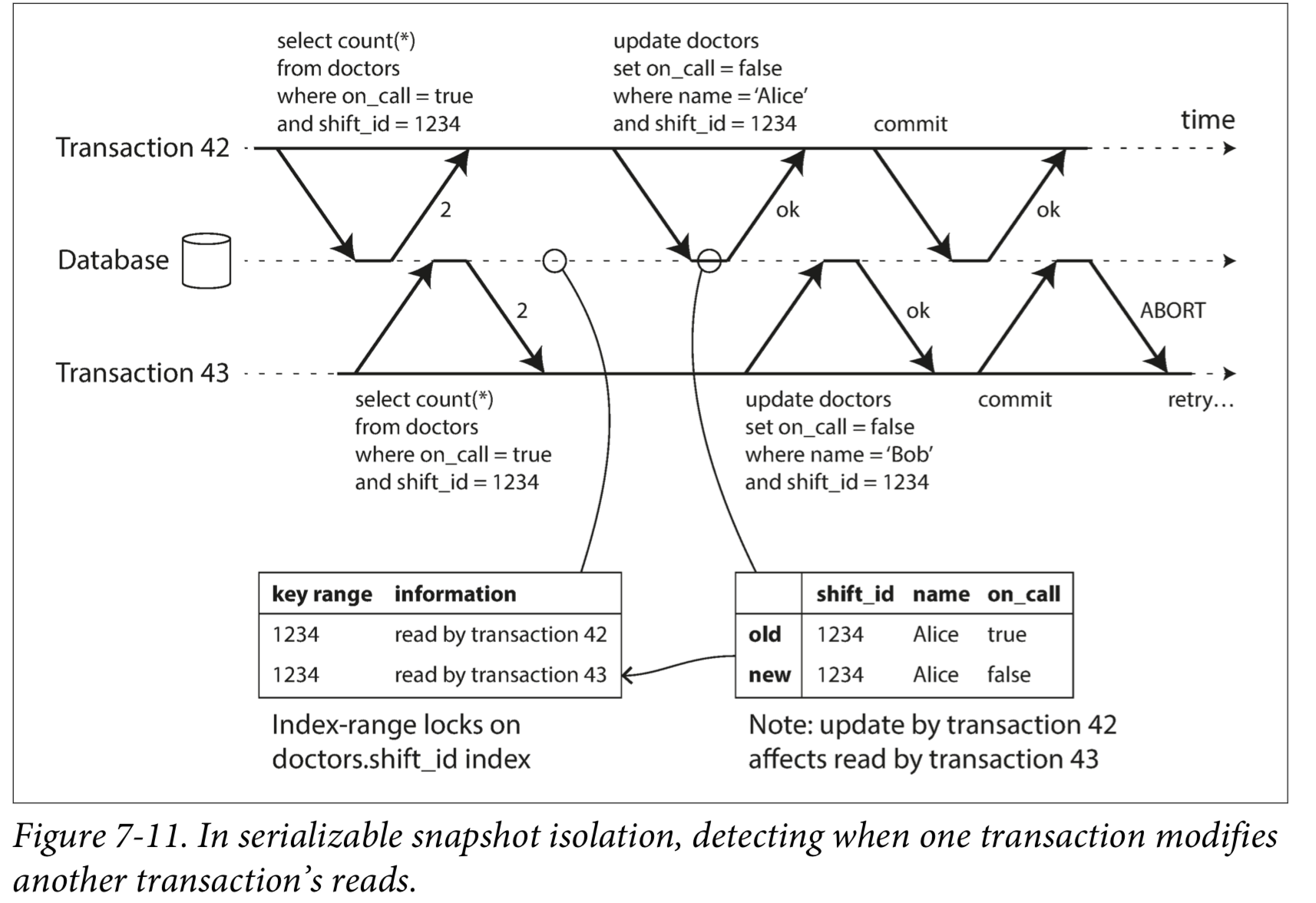
- Detecting writes that affect prior reads (the write occurs after the read)
Detecting stale MVCC reads
Detecting writes that affect prior reads
参考资料: