Designing Data-Intensive Applications 读书笔记 -The Trouble with Distributed Systems
Unreliable Networks
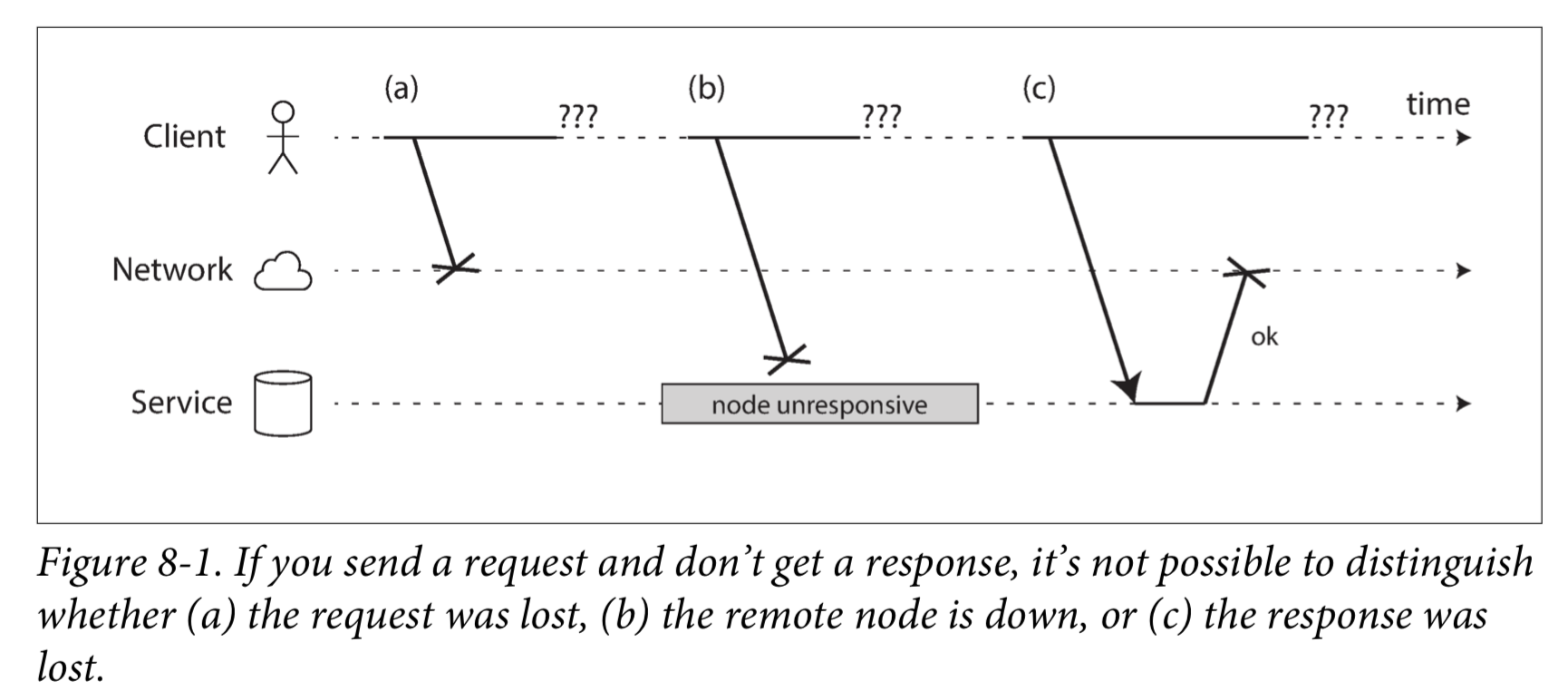
The usual way of handling this issue is a timeout: after some time you give up waiting and assume that the response is not going to arrive. However, when a timeout occurs, you still don’t know whether the remote node got your request or not.
Network Faults in Practice
Detecting Faults
Timeouts and Unbounded Delays
如果超时是检测故障的唯一可靠方法,那么超时应该等待多久?不幸的是没有简单的答案。
Synchronous Versus Asynchronous Networks
It is possible to give hard real-time response guarantees and bounded delays in networks, but doing so is very expensive and results in lower utilization of hardware resources. Most non-safety-critical systems choose cheap and unreliable over expensive and reliable.
Unreliable Clocks
可以在一定程度上同步时钟:最常用的机制是网络时间协议(NTP),它允许根据一组服务器报告的时间来调整计算机时钟。服务器则从更精确的时间源(如GPS接收机)获取时间。
Monotonic Versus Time-of-Day Clocks
时钟可以及时跳回。
单调钟适用于测量持续时间(时间间隔),例如超时或服务的响应时间。
在分布式系统中,使用单调钟测量经过时间(比如超时)通常很好,因为它不假定不同节点的时钟之间存在任何同步,并且对测量的轻微不准确性不敏感。
Clock Synchronization and Accuracy
Relying on Synchronized Clocks
Process Pauses
Say you have a database with a single leader per partition. Only the leader is allowed to accept writes. How does a node know that it is still leader (that it hasn’t been declared dead by the others), and that it may safely accept writes?
One option is for the leader to obtain a lease from the other nodes. Only one node can hold the lease at any one time—thus, when a node obtains a lease, it knows that it is the leader for some amount of time, until the lease expires. In order to remain leader, the node must periodically renew the lease before it expires. If the node fails, it stops renewing the lease, so another node can take over when it expires.
You can imagine the request-handling loop looking something like this:

Firstly, it’s relying on synchronized clocks.However, what if there is an unexpected pause in the execution of the program? For example, imagine the thread stops for 15 seconds around the line lease.isValid() before finally continuing. In that case, it’s likely that the lease will have expired by the time the request is processed, and another node has already taken over as leader. However, there is nothing to tell this thread that it was paused for so long, so this code won’t notice that the lease has expired until the next iteration of the loop—by which time it may have already done something unsafe by processing the request.
Knowledge, Truth, and Lies
So far in this chapter we have explored the ways in which distributed systems are different from programs running on a single computer: there is no shared memory, only message passing via an unreliable network with variable delays, and the systems may suffer from partial failures, unreliable clocks, and processing pauses.
The Truth Is Defined by the Majority
A node cannot necessarily trust its own judgment of a situation.A distributed system cannot exclusively rely on a single node, because a node may fail at any time, potentially leaving the system stuck and unable to recover. Instead, many distributed algorithms rely on a quorum, that is, voting among the nodes.
That includes decisions about declaring nodes dead. If a quorum of nodes declares another node dead, then it must be considered dead, even if that node still very much feels alive. The individual node must abide by the quorum decision and step down.
The leader and the lock
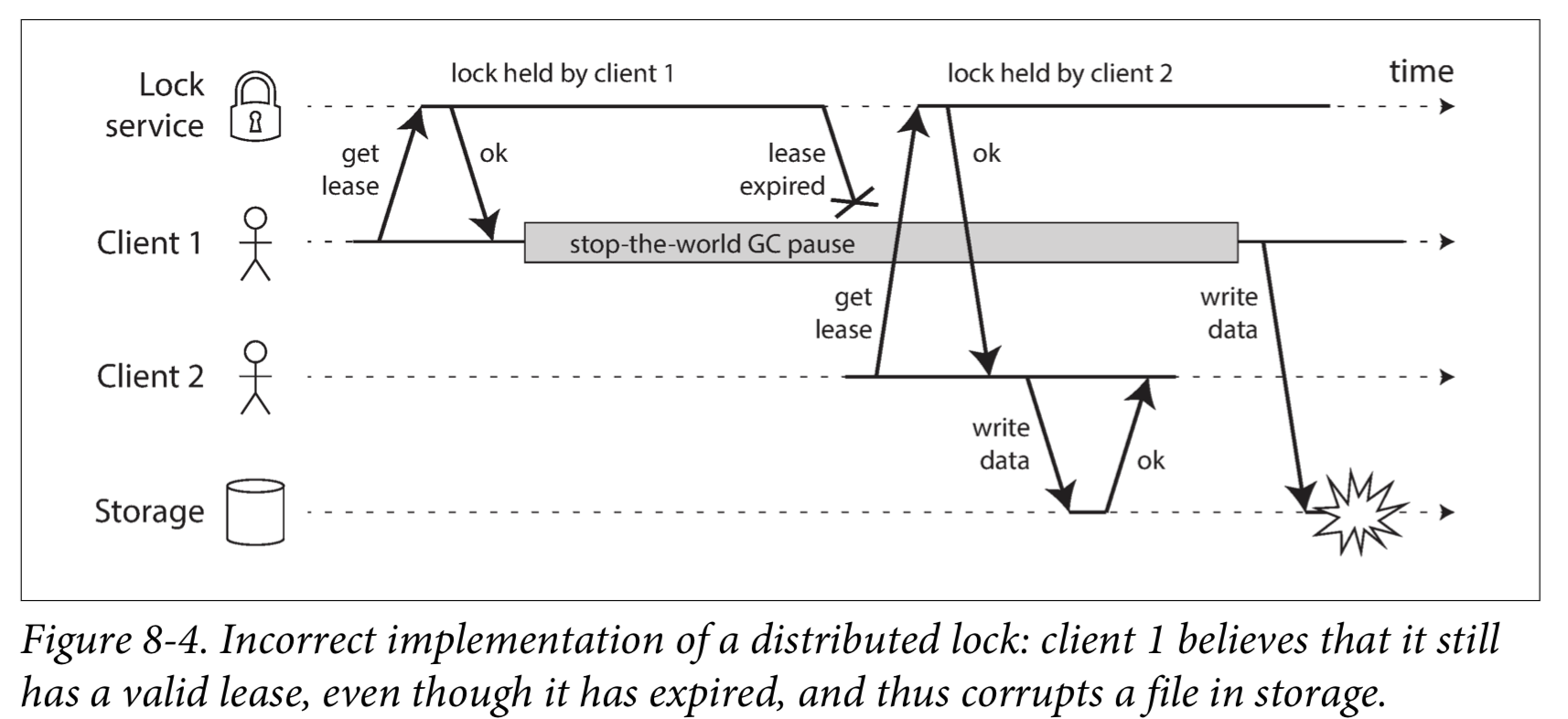
If the client holding the lease is paused for too long, its lease expires. Another client can obtain a lease for the same file, and start writing to the file. When the paused client comes back, it believes (incorrectly) that it still has a valid lease and proceeds to also write to the file. As a result, the clients’ writes clash and corrupt the file.
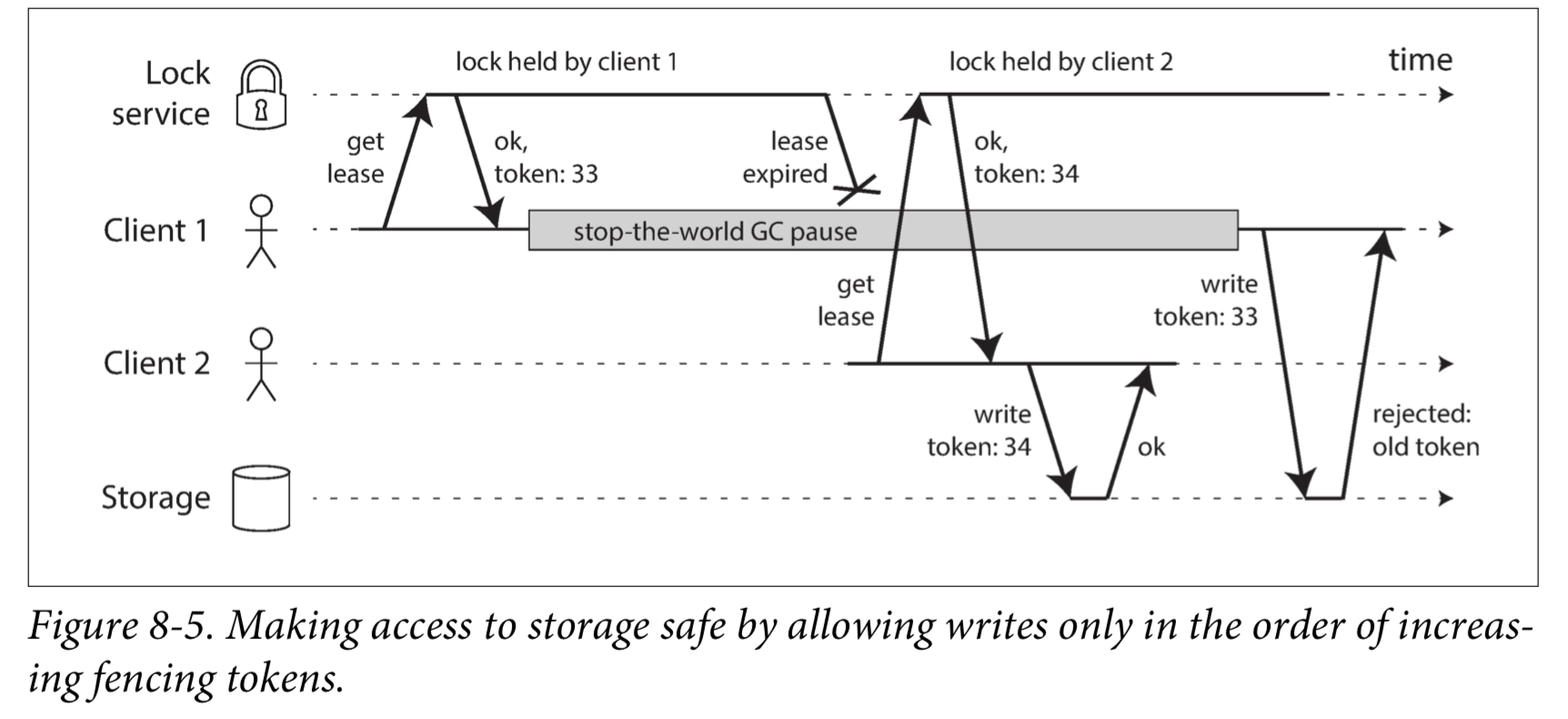
Fencing tokens
Fencing tokens(防护令牌)
We need to ensure that a node that is under a false belief of being “the chosen one” cannot disrupt the rest of the system.
Byzantine Faults
Fencing tokens can detect and block a node that is inadvertently acting in error.If the node deliberately wanted to subvert the system’s guarantees, it could easily do so by sending messages with a fake fencing token.
Distributed systems problems become much harder if there is a risk that nodes may “lie” (send arbitrary faulty or corrupted responses)—for example, if a node may claim to have received a particular message when in fact it didn’t. Such behavior is known as a Byzantine fault, and the problem of reaching consensus in this untrusting environment is known as the Byzantine Generals Problem.
A system is Byzantine fault-tolerant if it continues to operate correctly even if some of the nodes are malfunctioning and not obeying the protocol, or if malicious attackers are interfering with the network.
Byzantine是错综复杂的意思。
System Model and Reality
With regard to timing assumptions, three system models are in common use:
- Synchronous model
- Partially synchronous model
- Asynchronous model
Moreover, besides timing issues, we have to consider node failures. The three most common system models for nodes are:
- Crash-stop faults
- Crash-recovery faults
- Byzantine (arbitrary) faults
For modeling real systems, the partially synchronous model with crash-recovery faults is generally the most useful model.
Correctness of an algorithm
Safety and liveness
Liveness properties often include the word “eventually” in their definition.
Safety is often informally defined as nothing bad happens, and liveness as something good eventually happens.
An advantage of distinguishing between safety and liveness properties is that it helps us deal with difficult system models.
Mapping system models to the real world
Safety and liveness properties and system models are very useful for reasoning about the correctness of a distributed algorithm.
Proving an algorithm correct does not mean its implementation on a real system will necessarily always behave correctly.