Designing Data-Intensive Applications 读书笔记 -Consistency and Consensus
文章目录
- 1. Consistency Guarantees
- 2. Linearizability
- 3. Ordering Guarantees
- 4. Distributed Transactions and Consensus
- 5. Summary
consensus: that is, getting all of the nodes to agree on something.
If two nodes both believe that they are the leader, that situation is called split brain, and it often leads to data loss. Correct implementations of consensus help avoid such problems.
Consistency Guarantees
Systems with stronger guarantees may have worse performance or be less fault-tolerant than systems with weaker guarantees.
Transaction isolation is primarily about avoiding race conditions due to concurrently executing transactions, whereas distributed consistency is mostly about coordinating the state of replicas in the face of delays and faults.
Linearizability
中文翻译:线性一致性(强一致性)
Linearizability,the basic idea is to make a system appear as if there were only one copy of the data, and all operations on it are atomic.
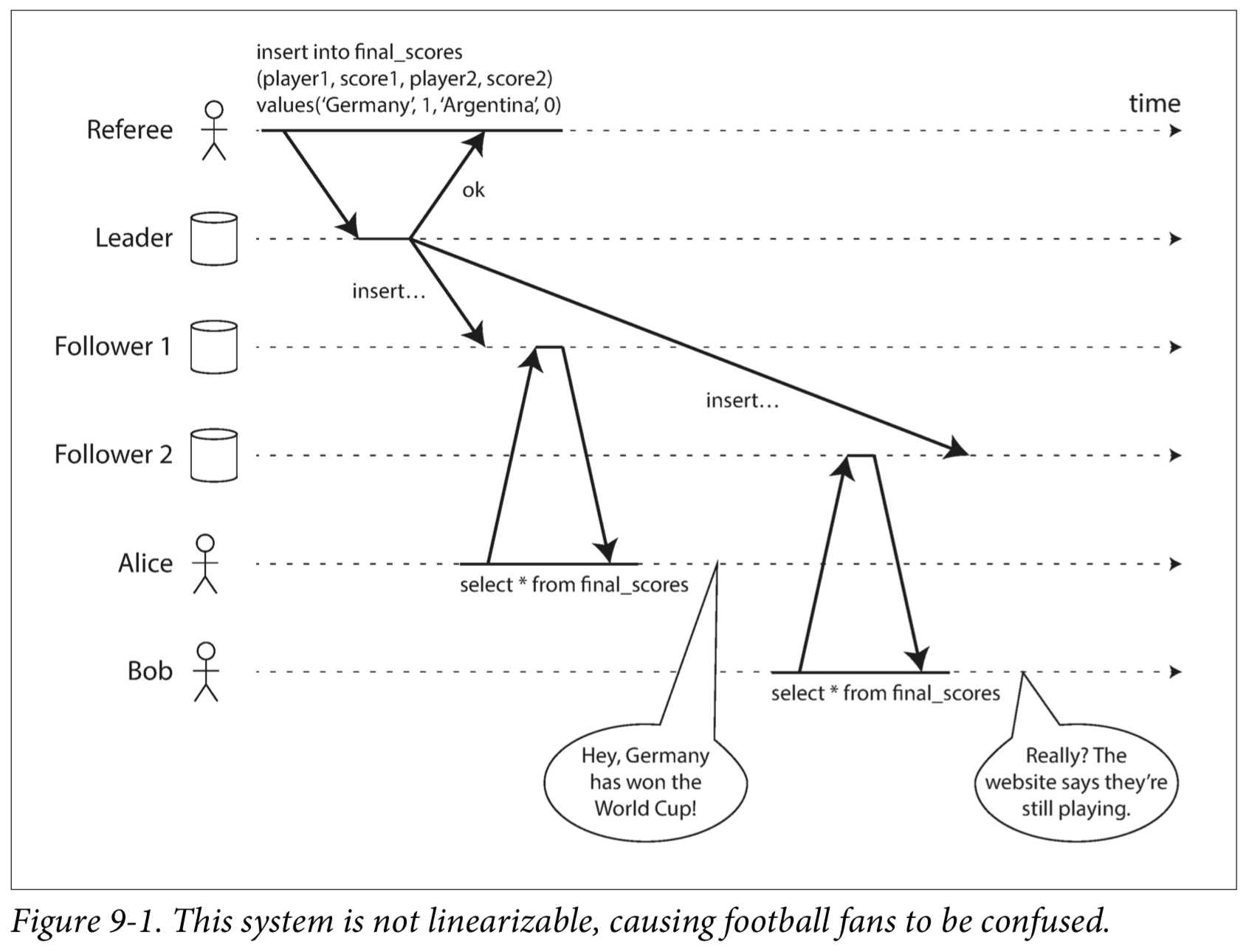
What Makes a System Linearizable?
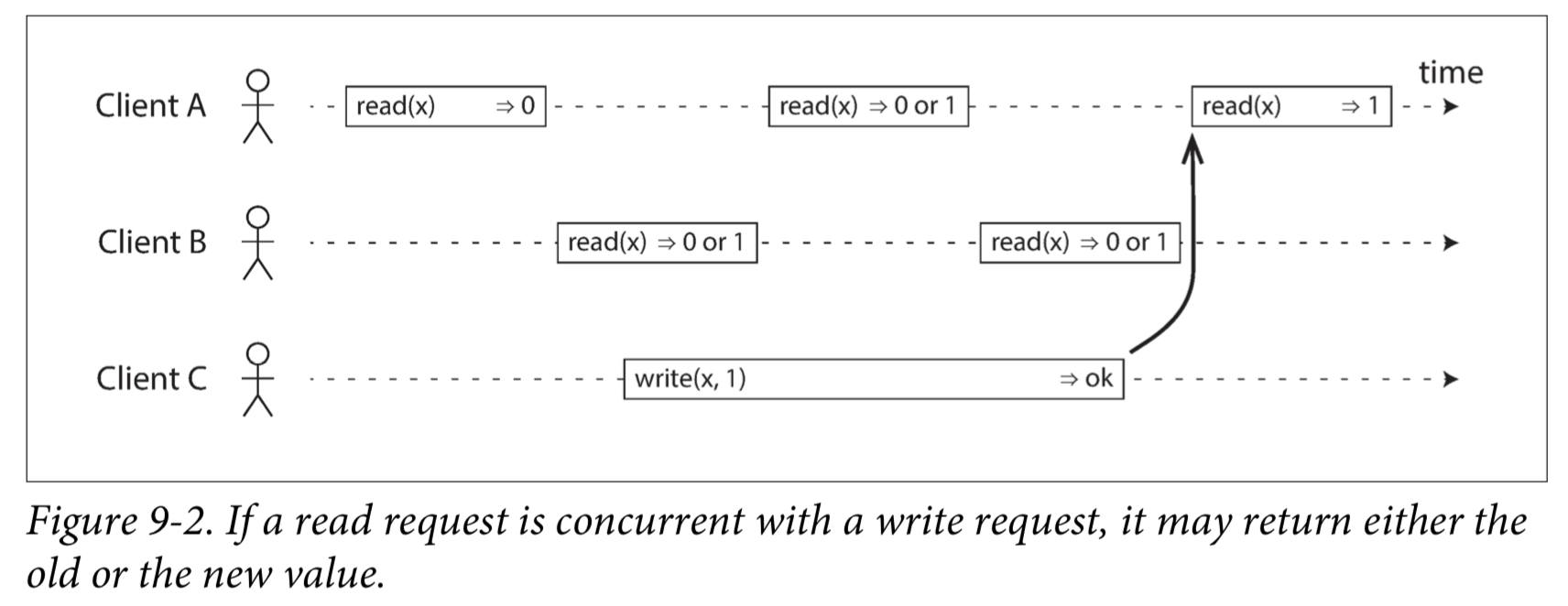
To make the system linearizable, we need to add another constraint.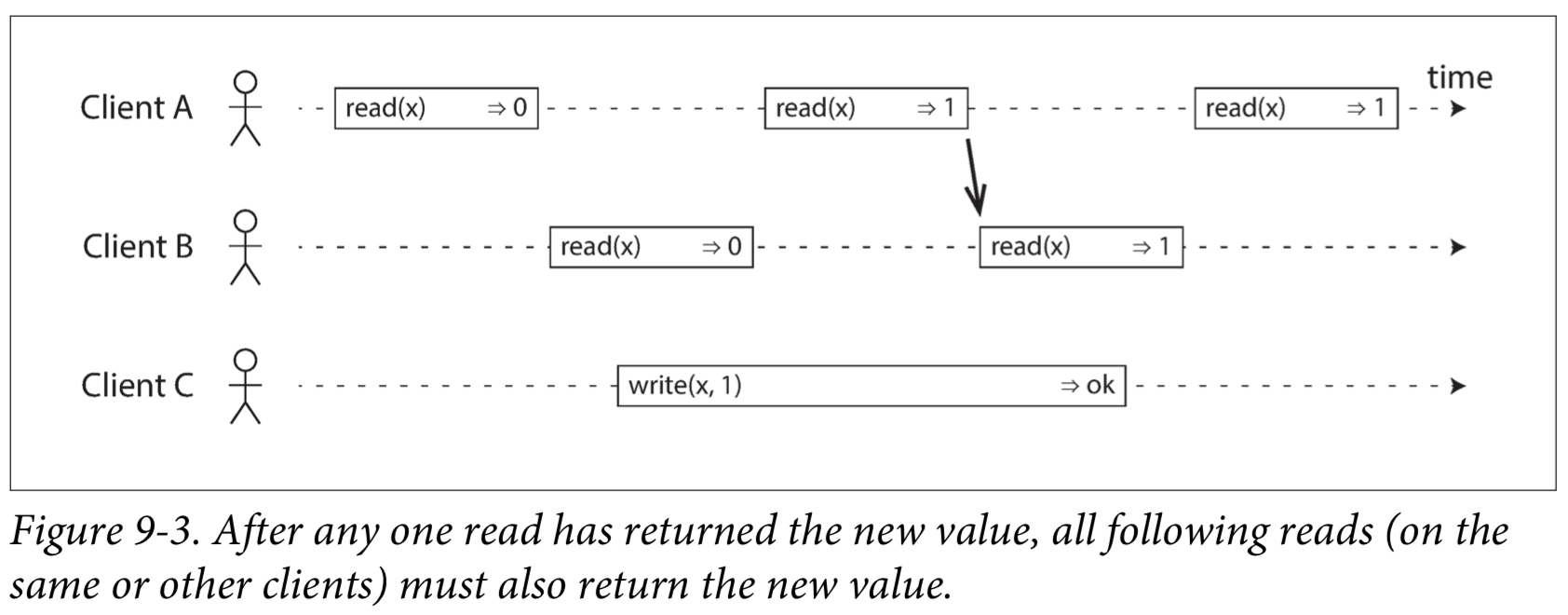
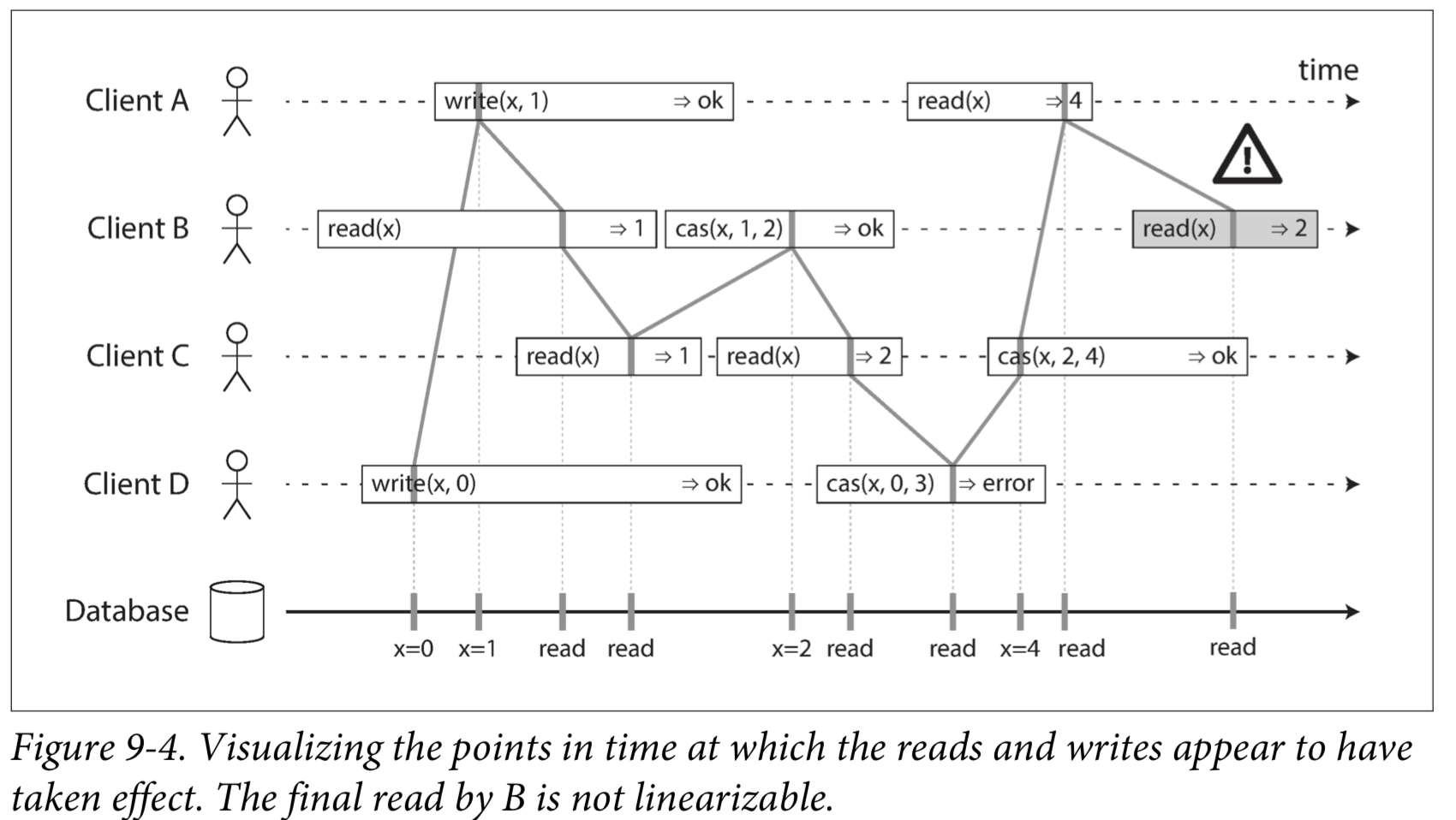
Linearizability Versus Serializability
- Serializability
Serializability is an isolation property of transactions, where every transaction may read and write multiple objects (rows, documents, records).It guarantees that transactions behave the same as if they had executed in some serial order (each transaction running to completion before the next transaction starts).
- Linearizability
Linearizability is a recency guarantee on reads and writes of a register (an individual object). It doesn’t group operations together into transactions, so it does not prevent problems such as write skew, unless you take additional measures.
Relying on Linearizability
Locking and leader election
Constraints and uniqueness guarantees
Uniqueness constraints are common in databases.
Similar issues arise if you want to ensure that a bank account balance never goes neg‐ ative, or that you don’t sell more items than you have in stock in the warehouse, or that two people don’t concurrently book the same seat on a flight or in a theater. These constraints all require there to be a single up-to-date value (the account balance, the stock level, the seat occupancy) that all nodes agree on.
Cross-channel timing dependencies
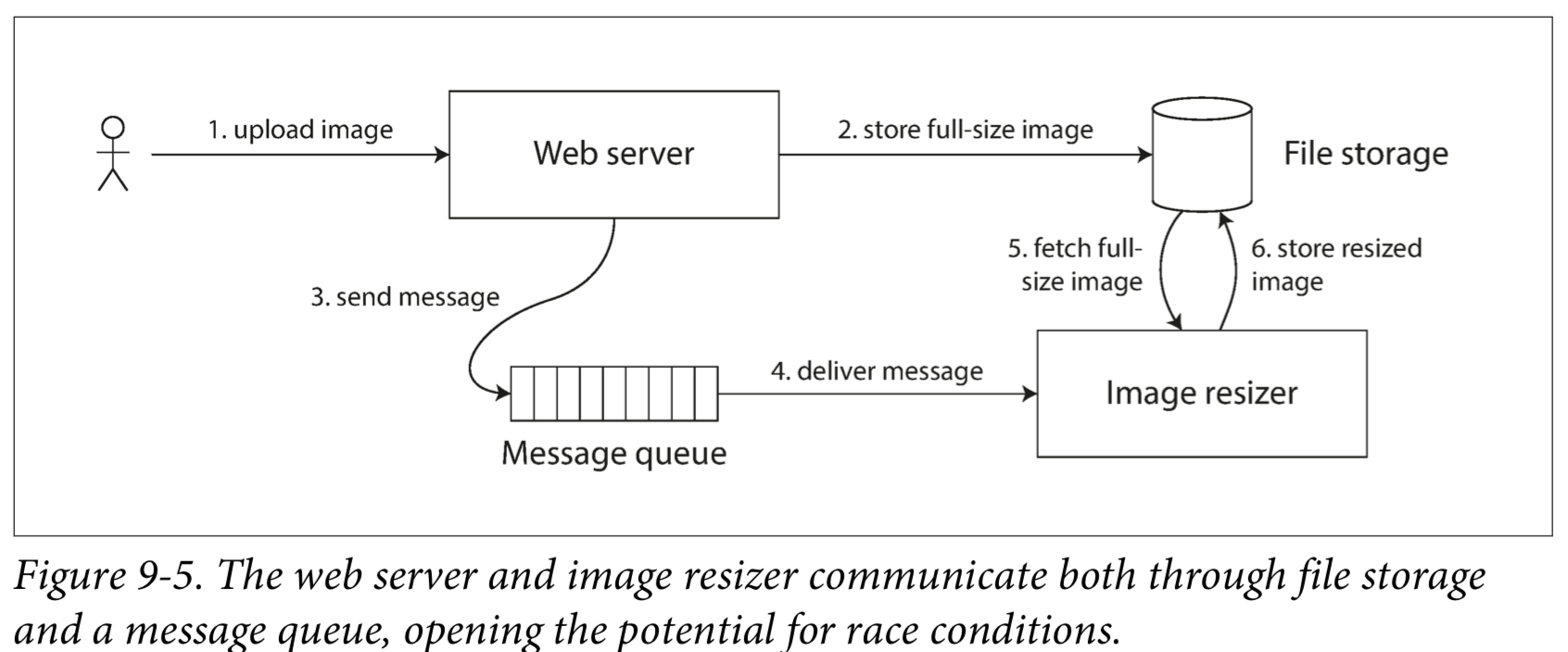
The message queue (steps 3 and 4 in Figure 9-5) might be faster than the internal replication inside the storage service.
This problem arises because there are two different communication channels between the web server and the resizer: the file storage and the message queue.
Implementing Linearizable Systems
Linearizability essentially means “behave as though there is only a single copy of the data, and all operations on it are atomic”.
- Single-leader replication (potentially linearizable)
- Consensus algorithms (linearizable)
- Multi-leader replication (not linearizable)
- Leaderless replication (probably not linearizable)
Linearizability and quorums
Intuitively, it seems as though strict quorum reads and writes should be linearizable in a Dynamo-style model. However, when we have variable network delays, it is possible to have race conditions, as demonstrated in Figure 9-6.
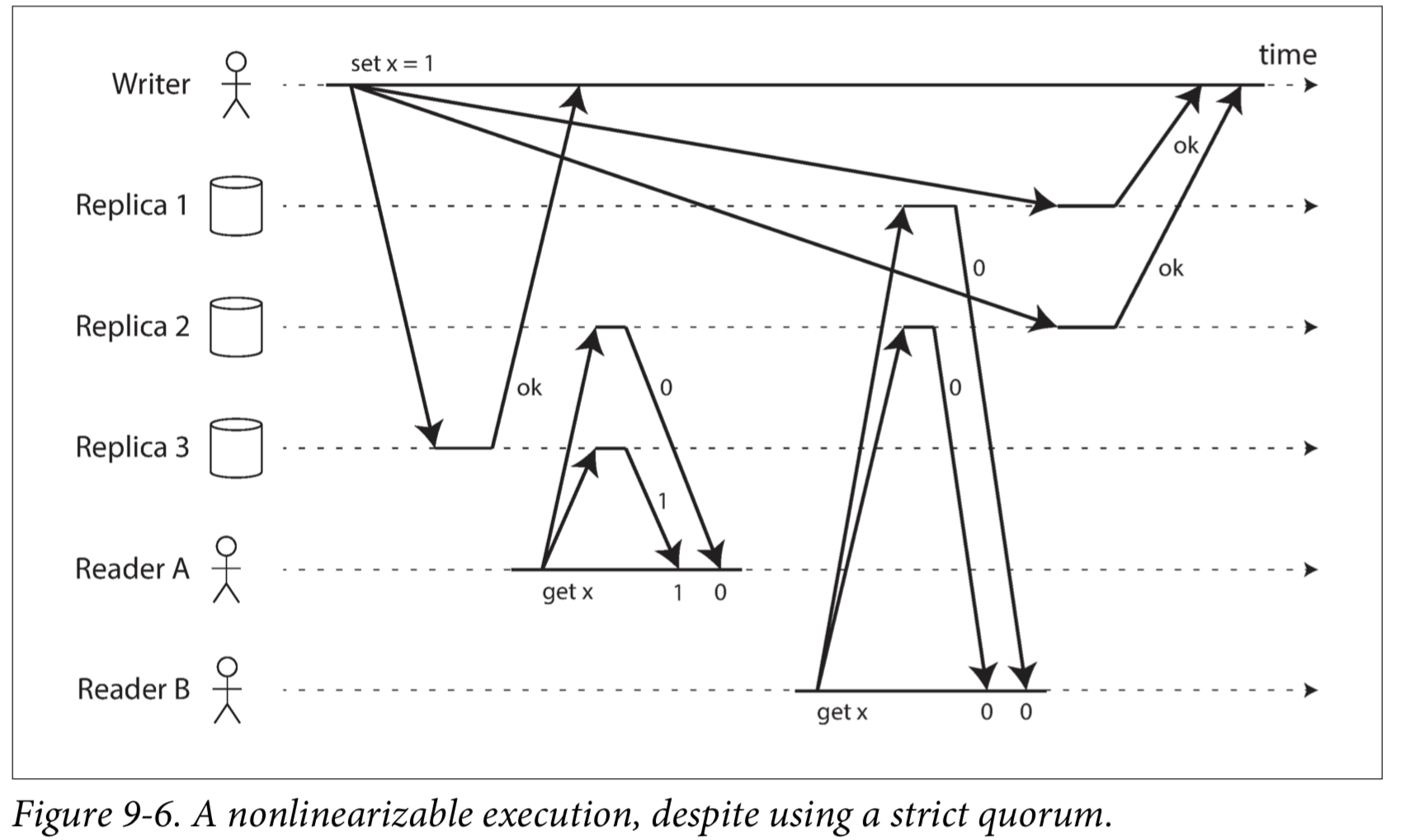
It is safest to assume that a leaderless system with Dynamo-style replication does not provide linearizability.
The Cost of Linearizability
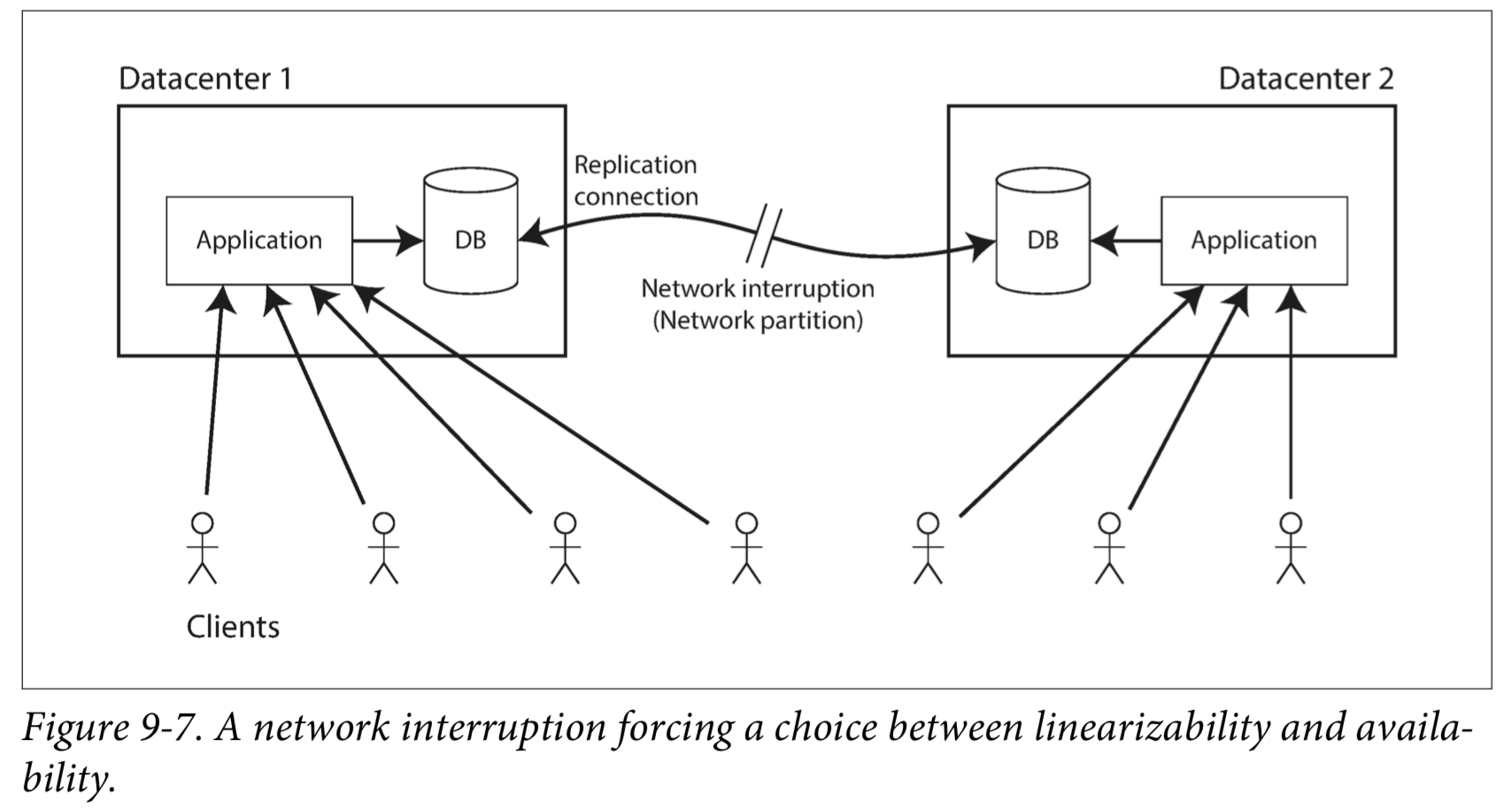
The CAP theorem
The CAP theorem as formally defined is of very narrow scope: it only considers one consistency model (namely linearizability) and one kind of fault(network partitions). It doesn’t say anything about network delays, dead nodes, or other trade-offs. Thus, although CAP has been historically influential, it has little practical value for designing systems.
Linearizability and network delays
Ordering Guarantees
Ordering and Causality
Causality imposes an ordering on events: cause comes before effect.If a system obeys the ordering imposed by causality, we say that it is causally consistent.
The causal order is not a total order
Linearizability is stronger than causal consistency
Causal consistency is the strongest possible consistency model that does not slow down due to network delays, and remains available in the face of network failures.
Capturing causal dependencies
In order to maintain causality, you need to know which operation happened before which other operation.
Sequence Number Ordering
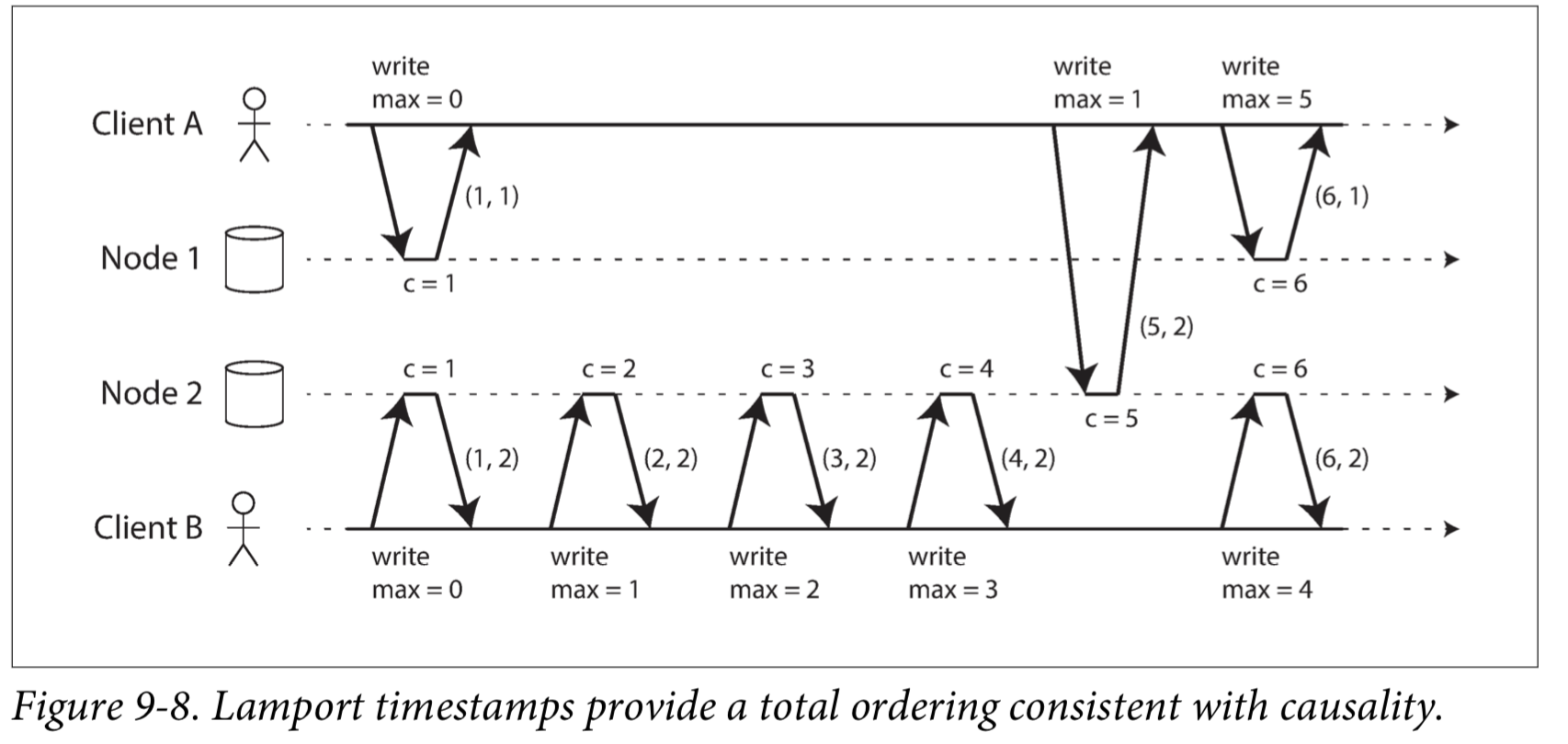
We can use sequence numbers or timestamps to order events.
Lamport timestamps
Timestamp ordering is not sufficient
It is not sufficient when a node has just received a request from a user to create a username, and needs to decide right now whether the request should succeed or fail.
In order to be sure that no other node is in the process of concurrently creating an account with the same username and a lower timestamp, you would have to check with every other node to see what it is doing.
The problem here is that the total order of operations only emerges after you have collected all of the operations.
In order to implement something like a uniqueness constraint for usernames, it’s not sufficient to have a total ordering of operations—you also need to know when that order is finalized.
This idea of knowing when your total order is finalized is captured in the topic of total order broadcast.
Total Order Broadcast
Total order broadcast is usually described as a protocol for exchanging messages between nodes. Informally, it requires that two safety properties always be satisfied:
- Reliable delivery
- Totally ordered delivery
Using total order broadcast
Consensus services such as ZooKeeper and etcd actually implement total order broadcast.
An important aspect of total order broadcast is that the order is fixed at the time the messages are delivered.
Implementing linearizable storage using total order broadcast
Total order broadcast is asynchronous: messages are guaranteed to be delivered reliably in a fixed order, but there is no guarantee about when a message will be delivered. By contrast, linearizability is a recency guarantee: a read is guaranteed to see the latest value written.
Distributed Transactions and Consensus
- Leader election
- Atomic commit
Atomic Commit and Two-Phase Commit (2PC)
From single-node to distributed atomic commit
Introduction to two-phase commit
Two-phase commit is an algorithm for achieving atomic transaction commit across multiple nodes—i.e., to ensure that either all nodes commit or all nodes abort.
The commit/abort process in 2PC is split into two phases (hence the name).
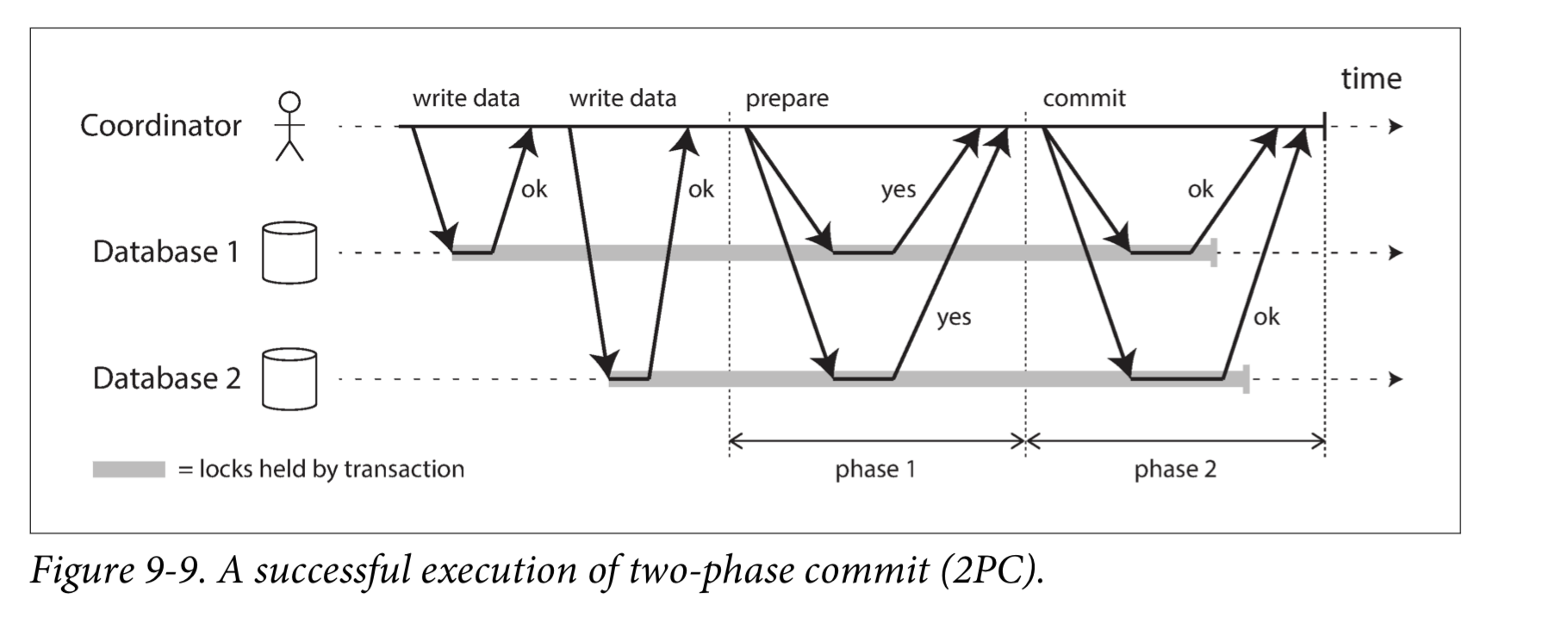
Coordinator failure
If any of the prepare requests fail or time out, the coordinator aborts the transaction; if any of the commit or abort requests fail, the coordinator retries them indefinitely.
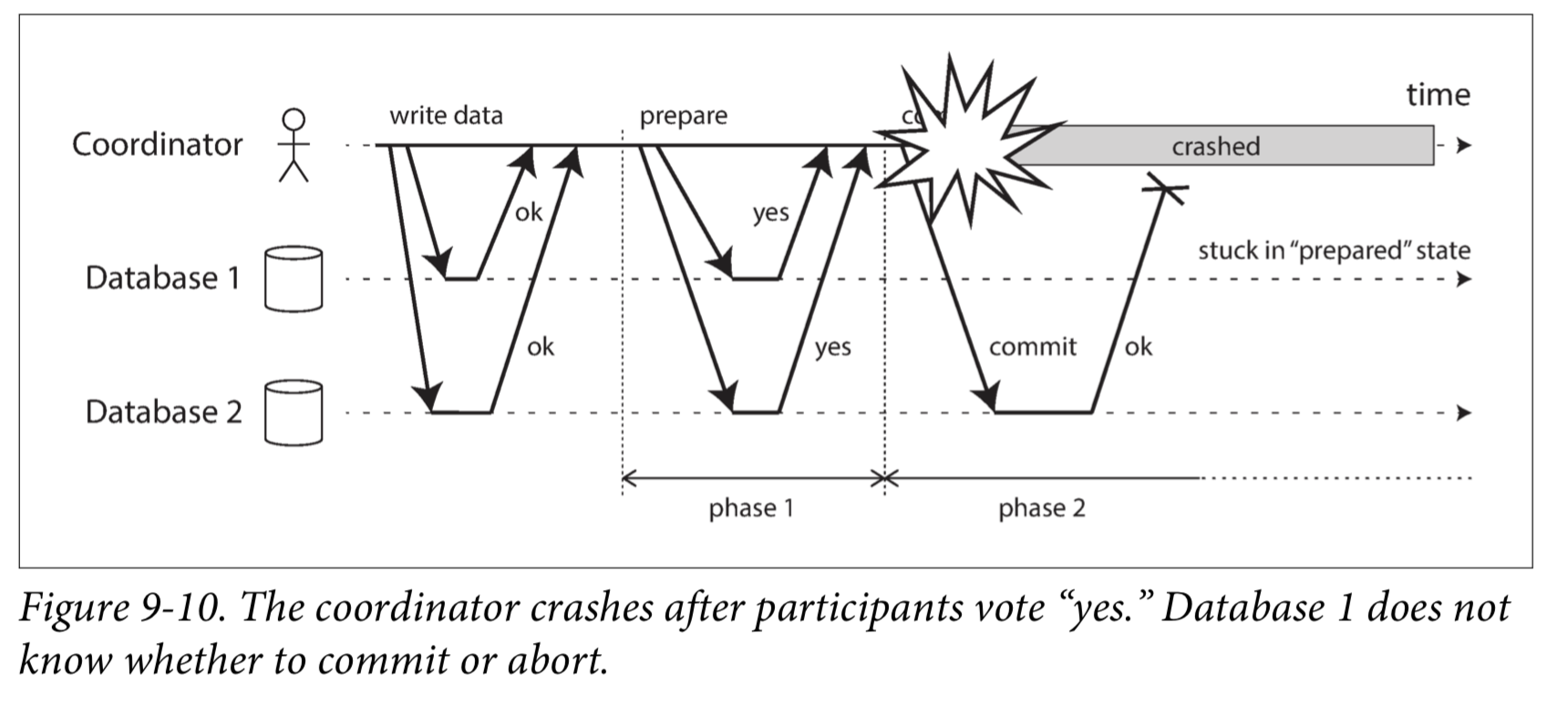
The only way 2PC can complete is by waiting for the coordinator to recover.
Three-phase commit
Two-phase commit is called a blocking atomic commit protocol due to the fact that 2PC can become stuck waiting for the coordinator to recover.
three-phase commit (3PC) assumes a network with bounded delay and nodes with bounded response times; in most practical systems with unbounded network delay and process pauses , it cannot guarantee atomicity.
Distributed Transactions in Practice
Database-internal distributed transactions
Heterogeneous distributed transactions
Exactly-once message processing
XA transactions
XA is not a network protocol—it is merely a C API for interfacing with a transaction coordinator.
Holding locks while in doubt
Recovering from coordinator failure
Limitations of distributed transactions
Fault-Tolerant Consensus
Informally, consensus means getting several nodes to agree on something.
The consensus problem is normally formalized as follows: one or more nodes may propose values, and the consensus algorithm decides on one of those values.
In this formalism, a consensus algorithm must satisfy the following properties:
- Uniform agreement
- Integrity
- Validity
- Termination
Consensus algorithms and total order broadcast
The best-known fault-tolerant consensus algorithms are Viewstamped Replication (VSR), Paxos, Raft, and Zab.
They decide on a sequence of values, which makes them total order broadcast algorithms
Single-leader replication and consensus
Epoch numbering and quorums
All of the consensus protocols discussed so far internally use a leader in some form or another, but they don’t guarantee that the leader is unique. Instead, they can make a weaker guarantee: the protocols define an epoch number and guarantee that within each epoch, the leader is unique.
We have two rounds of voting: once to choose a leader, and a second time to vote on a leader’s proposal.
This voting process looks superficially similar to two-phase commit. The biggest differences are that in 2PC the coordinator is not elected, and that fault-tolerant consensus algorithms only require votes from a majority of nodes, whereas 2PC requires a “yes” vote from every participant. Moreover, consensus algorithms define a recovery process by which nodes can get into a consistent state after a new leader is elected, ensuring that the safety properties are always met. These differences are key to the correctness and fault tolerance of a consensus algorithm.
Limitations of consensus
The process by which nodes vote on proposals before they are decided is a kind of synchronous replication.
Consensus systems always require a strict majority to operate.
Most consensus algorithms assume a fixed set of nodes that participate in voting, which means that you can’t just add or remove nodes in the cluster.
Consensus systems generally rely on timeouts to detect failed nodes.
Sometimes, consensus algorithms are particularly sensitive to network problems.
Membership and Coordination Services
ZooKeeper and etcd are designed to hold small amounts of data that can fit entirely in memory.That small amount of data is replicated across all the nodes using a fault-tolerant total order broadcast algorithm.
ZooKeeper is modeled after Google’s Chubby lock service , implementing not only total order broadcast (and hence consensus), but also an interesting set of other features that turn out to be particularly useful when building distributed systems:
- Linearizable atomic operations
- Total ordering of operations
- Failure detection
- Change notifications
Allocating work to nodes
Normally, the kind of data managed by ZooKeeper is quite slow-changing.
Service discovery
Membership services
A membership service determines which nodes are currently active and live members of a cluster.
Summary
It turns out that a wide range of problems are actually reducible to consensus and are equivalent to each other.
- Linearizable compare-and-set registers
- Atomic transaction commit
- Total order broadcast
- Locks and leases
- Membership/coordination service
- Uniqueness constraint
Not every system necessarily requires consensus: for example, leaderless and multi-leader replication systems typically do not use global consensus.