Understanding the Linux Kernel 读书笔记 -Process
文章目录
Processes, Lightweight Processes, and Threads
A process is an instance of a program in execution. You might think of it as the collection of data structures that fully describes how far the execution of the program has progressed. The purpose of a process is to act as an entity to which system resources (CPU time, memory, etc.) are allocated.
Linux uses lightweight processes to offer better support for multithreaded applications. A straightforward way to implement multithreaded applications is to associate a lightweight process with each thread. Each thread can be scheduled independently by the kernel so that one may sleep while another remains runnable.
Process Descriptor
This is the role of the process descriptor—a task_ struct type structure whose fields contain all the information related to a single process.
2.1 Process State
2.2 Identifying a Process
Linux associates a different PID with each process or lightweight process in the system. However, POSIX standard states that all threads of a multithreaded application must have the same PID.
To comply with this standard, the identifier shared by the threads is the PID of the thread group leader, that is, the PID of the first lightweight process in the group; it is stored in the tgid field of the process descriptors.
The getpid() system call returns the value of tgid relative to the current process instead of the value of pid, so all the threads of a multithreaded application share the same identifier.
2.2.1 Process descriptors handling
For each process, Linux packs two different data structures in a single per-process memory area: a small data structure linked to the process descriptor, namely the thread_info structure, and the Kernel Mode process stack.
2.2.2 Identifying the current process
The kernel can easily obtain the address of the thread_info structure of the process currently running on a CPU from the value of the esp register.
2.2.3 The process list
2.2.4 The lists of TASK_RUNNING processes
When looking for a new process to run on a CPU, the kernel has to consider only the runnable processes (that is, the processes in the TASK_RUNNINGstate).
Linux 2.6 implements the runqueue without putting all runnable processes in the same list. The aim is to allow the scheduler to select the best runnable process in constant time.
The trick is splitting the runqueue in many lists of runnable processes, one list per process priority. Each task_struct descriptor includes a run_listfield which points to the corresponding runqueue.
All these are implemented by a single data structure prio_array_t. Noted that each CPU has its own runqueue.1
2
3
4
5struct prio_array {
unsigned int nr_active; /* The number of process descriptors linked into the lists */
unsigned long bitmap[BITMAP_SIZE]; /* A priority bitmap: each flag is set if and only if the corre- sponding priority list is not empty */
struct list_head queue[MAX_PRIO]; /* The 140 heads of the priority lists */
};
2.3 Relationships Among Processes
The pidhash table and chained lists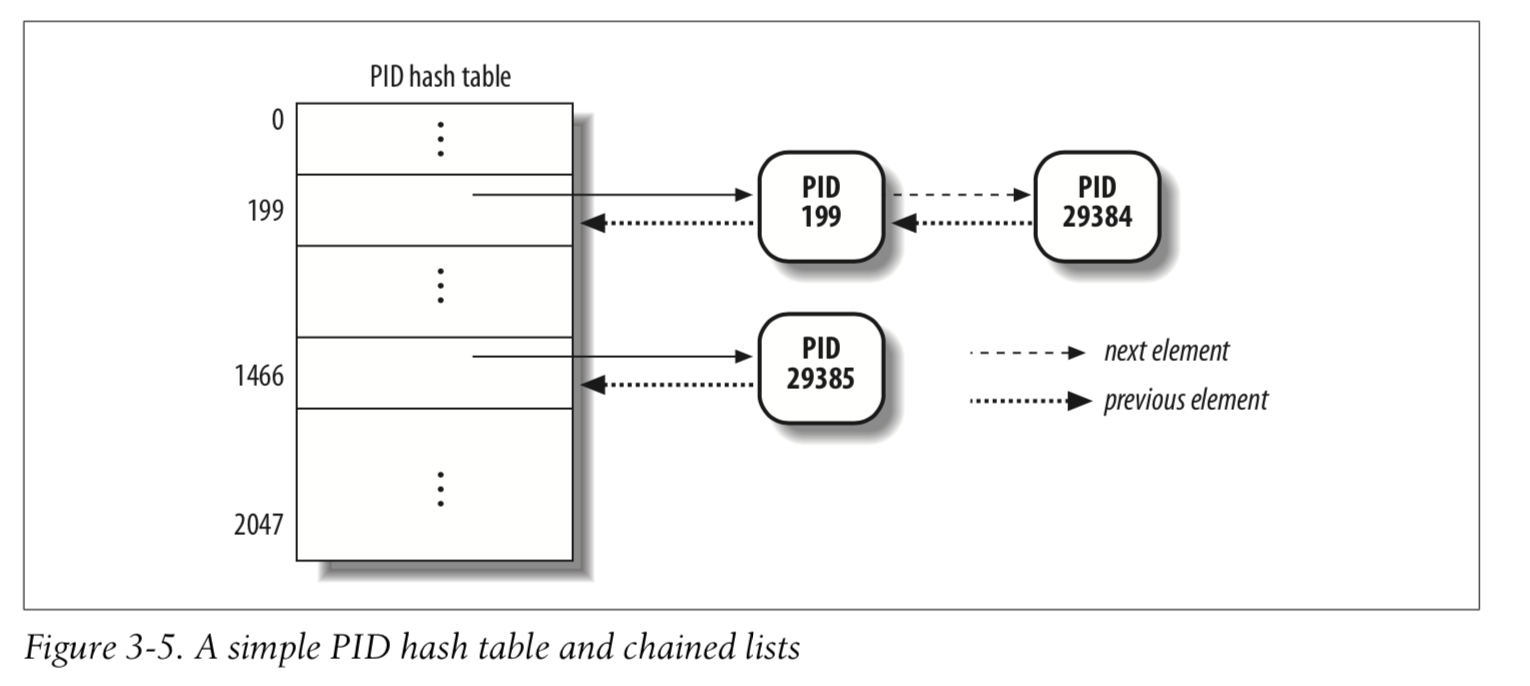

2.4 How Processes Are Organized
2.4.1 Wait queues
A wait queue represents a set of sleeping processes, which are woken up by the kernel when some condition becomes true.
2.4.2 Handling wait queues
2.5 Process Resource Limits
Each process has an associated set of resource limits, which specify the amount of system resources it can use.
The resource limits are stored in an array (task_struct->signal) of elements of type struct rlimit.1
2
3
4struct rlimit {
unsigned long rlim_cur;
unsigned long rlim_max;
};
Process Switch
3.1 Hardware Context
The set of data that must be loaded into the registers before the process resumes its execution on the CPU is called the hardware context. The hardware context is a subset of the process execution context, which includes all information needed for the process execution. In Linux, a part of the hardware context of a process is stored in the process descriptor, while the remaining part is saved in the Kernel Mode stack.
Process switching occurs only in Kernel Mode. The contents of all registers used by a process in User Mode have already been saved on the Kernel Modestack before performing process switching.
3.2 Task State Segment
The 80x86 architecture includes a specific segment type called the Task State Segment(TSS), to store hardware contexts. While in Linux, there is only single TSS for each processor, each process descriptor includes additional field struct thread_struct thread, in which the kernel saves the hardware context whenever the process is being switched out. The data structutr includes fields for most of the CPU registers, except the general-purpose registers such as eax, ebx, etc., which are stored in the Kernel Mode stack.
3.3 Performing the Process Switch
Essentially, every process switch consists of two steps:
- Switching the Page Global Directory to install a new address space;
- Switching the Kernel Mode stack and the hardware context
The switch_to macro is used to switch the Kernel Mode stack and the hardware context. The macro is a hardware-dependent routine.
Creating Processes
- Copy On Write: Allow both the parent and the child to read the same physical pages. Whenever either one tries to write on a physical page, the kernel copies its contents into a new physical page that is assigned to the writing process.
- Lightweight process: Allow both the parent and the child to share many per-process kernel data structures, such as the paging tables (and therefore the entire User Mode address space), the open file tables, and the signal dispositions.
vfork()system call: Create a process that shares the memory address space of its parent. To prevent the parent from overwriting data needed by the child, the parent’s execution is blocked until the child exits or executes a new program.
4.1 The clone(), fork(), and vfork() System Calls
Lightweight processes are created in Linux by using a function named clone().clone() is actually a wrapper function defined in the C library, which sets up the stack of the new lightweight process and invokes a clone() system call hidden to the programmer.
fork will make an exact copy of the parent’s address space and give it to the child. Therefore, the parent and child processes have separate address spaces.
4.2 Kernel Threads
In Linux, kernel threads differ from regular processes in the following ways:
- Kernel threads run only in Kernel Mode, while regular processes run alterna- tively in Kernel Mode and in User Mode.
- Because kernel threads run only in Kernel Mode, they use only linear addresses greater than PAGE_OFFSET.
0号线程是scheduler,1号线程是init/systemd(所有user thread的祖先),2号线程是[kthreadd](所有kernel thread的父进程)。
参考资料: