Understanding the Linux Kernel 读书笔记 -Interrupts and Exceptions
文章目录
An interrupt is usually defined as an event that alters the sequence of instructions executed by a processor.
Intel microprocessor manuals designate synchronous and asynchronous interrupts as exceptions and interrupts. We’ll occasionally use the term “interrupt signal” to designate both types together (synchronous as well as asynchronous).
Interrupts are issued by interval timers and I/O devices.
Exceptions, on the other hand, are caused either by programming errors or by anomalous conditions that must be handled by the kernel.
1 The Role of Interrupt Signals
When an interrupt signal arrives, the CPU must stop what it’s currently doing and switch to a new activity; it does this by saving the current value of the program counter (i.e., the content of the eip and cs registers) in the Kernel Mode stack and by placing an address related to the interrupt type into the program counter.
There is a key difference between interrupt handling and process switching: the code executed by an interrupt or by an exception handler is not a process. Rather, it is a kernel control path that runs at the expense of the same process that was running when the interrupt occurred. As a kernel control path, the interrupt handler is lighter than a process (it has less context and requires less time to set up or tear down).
2 Interrupts and Exceptions
- Interrupts
- Exceptions
- Processor-detected exceptions
- Faults
- Traps
- Aborts
- Programmed exceptions
- Processor-detected exceptions
Processor-detected exceptions: These are further divided into three groups, depending on the value of the eip register that is saved on the Kernel Mode stack when the CPU control unit raises the exception.
**Traps:**The saved value of eip is the address of the instruction that should be executed after the one that caused the trap.
**Aborts:**A serious error occurred; the control unit is in trouble, and it may be unable to store in the eip register the precise location of the instruction causing the exception. Aborts are used to report severe errors, such as hardware failures and invalid or inconsistent values in system tables.
**Programmed exceptions:**Occur at the request of the programmer. Programmed exceptions are handled by the control unit as traps; they are often called software interrupts. Such exceptions have two common uses: to implement system calls and to notify a debugger of a specific event.
Each interrupt or exception is identified by a number ranging from 0 to 255; Intel calls this 8-bit unsigned number a vector. The vectors of nonmaskable interrupts and exceptions are fixed, while those of maskable interrupts can be altered by programming the Interrupt Controller.
2.1 IRQs and Interrupts
Each hardware device controller capable of issuing interrupt requests usually has a single output line designated as the Interrupt ReQuest (IRQ) line.All existing IRQ lines are connected to the input pins of a hardware circuit called the Programmable Interrupt Controller(PIC).
The Advanced Programmable Interrupt Controller (APIC)
However, if the system includes two or more CPUs, this approach is no longer valid and more sophisticated PICs are needed.

Besides distributing interrupts among processors, the multi-APIC system allows CPUs to generate interprocessor interrupts(IPI).
2.2 Exceptions
Each exception is handled by a specific exception handler, which usually sends a Unix signal to the process that caused the exception.
2.3 Interrupt Descriptor Table
A system table called Interrupt Descriptor Table (IDT) associates each interrupt or exception vector with the address of the corresponding interrupt or exception handler.
The IDT may include three types of descriptors;

Linux uses interrupt gates to handle interrupts and trap gates to handle exceptions.
2.4 Hardware Handling of Interrupts and Exceptions
After the interrupt or exception is processed, the corresponding handler must relinquish control to the interrupted process.
3 Nested Execution of Exception and Interrupt Handlers
Every interrupt or exception gives rise to a kernel control path or separate sequence of instructions that execute in Kernel Mode on behalf of the current process.
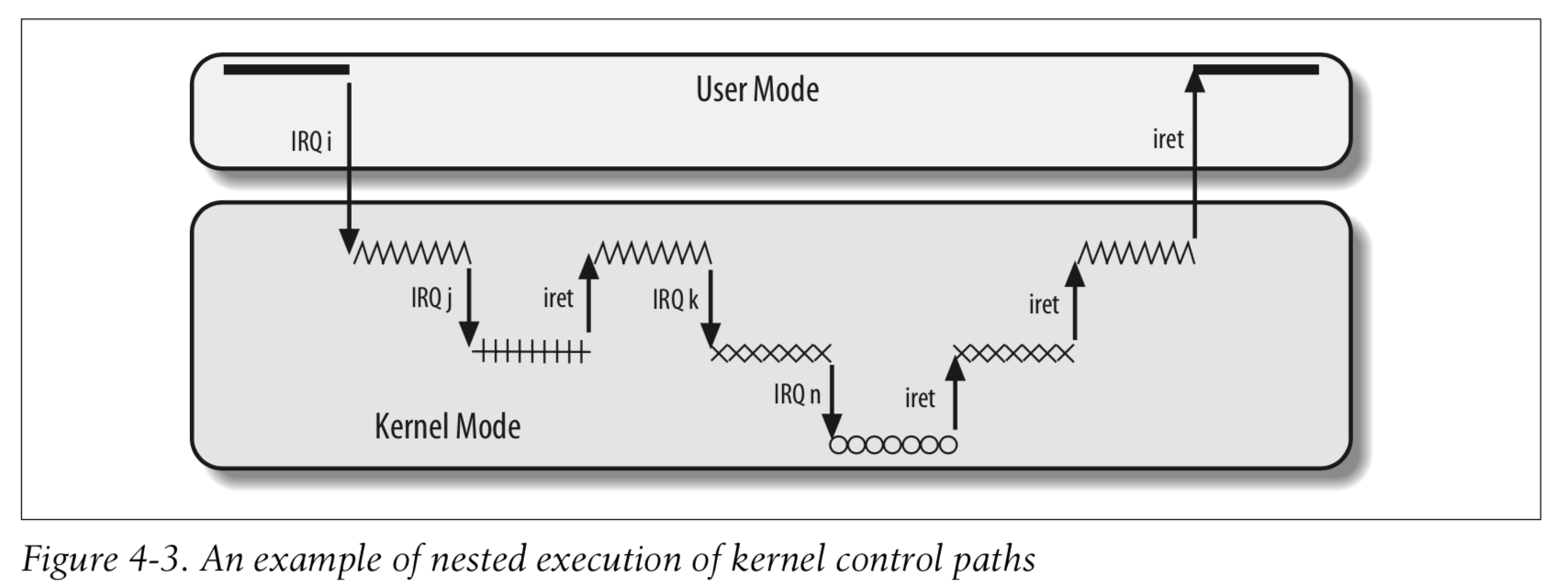
The price to pay for allowing nested kernel control paths is that an interrupt handler must never block, that is, 中断处理程序运行期间不能发生进程切换.
An interrupt handler may preempt both other interrupt handlers and exception handlers. Conversely, an exception handler never preempts an interrupt handler. Interrupt handlers never perform operations that can induce page faults, and thus, potentially, a process switch.
On multiprocessor systems, several kernel control paths may execute concurrently. Moreover, a kernel control path associated with an exception may start executing on a CPU and, due to a process switch, migrate to another CPU.
4 Initializing the Interrupt Descriptor Table
5 Exception Handling
When one of them occurs, the kernel sends a signal to the process that caused the exception to notify it of an anomalous condition.
Exception handlers have a standard structure consisting of three steps:
- Save the contents of most registers in the Kernel Mode stack (this part is coded in assembly language).
- Handle the exception by means of a high-level C function.
- Exit from the handler by means of the
ret_from_exception()function.
5.1 Saving the Registers for the Exception Handler
5.2 Entering and Leaving the Exception Handler
Store the hardware error code and the exception vector in the process descriptor of current, and then send a suitable signal to that process:
1 | current->thread.error_code = error_code; |
The current process takes care of the signal right after the termination of the exception handler. The signal will be handled either in User Mode by the process’s own signal handler (if it exists) or in Kernel Mode. In the latter case, the kernel usually kills the process.
6 Interrupt Handling
Most exceptions are handled simply by sending a Unix signal to the process that caused the exception. The action to be taken is thus deferred until the process receives the signal; as a result, the kernel is able to process the exception quickly.
Interrupt handling depends on the type of interrupt.
- I/O interrupts
- Timer interrupts
- Interprocessor interrupts
6.1 I/O Interrupt Handling
In the PCI bus architecture, for instance, several devices may share the same IRQ line. This means that the interrupt vector alone does not tell the whole story.
- IRQ sharing
- IRQ dynamic allocation
The interrupt handler executes several interrupt service routines (ISRs).
Not all actions to be performed when an interrupt occurs have the same urgency.Long noncritical operations should be deferred, because while an interrupt handler is running, the signals on the corresponding IRQ line are temporarily ignored. Most important, the process on behalf of which an interrupt handler is executed must always stay in the TASK_RUNNING state, or a system freeze can occur.Therefore, interrupt handlers cannot perform any blocking procedure such as an I/O disk operation. Linux divides the actions to be performed following an interrupt into three classes:
- Critical
- Noncritical
- Noncritical deferrable
Regardless of the kind of circuit that caused the interrupt, all I/O interrupt handlers perform the same four basic actions:
- Save the IRQ value and the register’s contents on the Kernel Mode stack.
- Send an acknowledgment to the PIC that is servicing the IRQ line, thus allowing it to issue further interrupts.
- Execute the interrupt service routines (ISRs) associated with all the devices that share the IRQ.
- Terminate by jumping to the
ret_from_intr()address.
7 Softirqs and Tasklets
We mentioned earlier in the section “Interrupt Handling” that several tasks among those executed by the kernel are not critical: they can be deferred for a long period of time, if necessary.
The deferrable tasks can execute with all interrupts enabled. Taking them out of the interrupt handler helps keep kernel response time small. This is a very important property for many time-critical applications that expect their interrupt requests to be serviced in a few milliseconds.
Linux 2.6 answers such a challenge by using two kinds of non-urgent interruptible kernel functions: the so-called deferrable functions (softirqs and tasklets), and those executed by means of some work queues.
Softirqs and tasklets are strictly correlated, because tasklets are implemented on top of softirqs. As a matter of fact, the term “softirq,” which appears in the kernel source code, often denotes both kinds of deferrable functions.
8 Work Queues
The work queues allow kernel functions to be activated (much like deferrable functions) and later executed by special kernel threads called worker threads.
Despite their similarities, deferrable functions and work queues are quite different. The main difference is that deferrable functions run in interrupt context while functions in work queues run in process context. Running in process context is the only way to execute functions that can block. No process switch can take place in interrupt context. A function in a work queue is executed by a kernel thread,
参考资料: