深入理解 Linux 的 RCU 机制
文章目录
Read-copy update (RCU) is a synchronization mechanism. RCU achieves scalability improvements by allowing reads to occur concurrently with updates. In contrast with conventional locking primitives that ensure mutual exclusion among concurrent threads regardless of whether they be readers or updaters, or with reader-writer locks that allow concurrent reads but not in the presence of updates, RCU supports concurrency between a single updater and multiple readers. RCU ensures that reads are coherent by maintaining multiple versions of objects and ensuring that they are not freed up until all pre-existing read-side critical sections complete. RCU defines and uses efficient and scalable mechanisms for publishing and reading new versions of an object, and also for deferring the collection of old versions. These mechanisms distribute the work among read and update paths in such a way as to make read paths extremely fast.
RCU is made up of three fundamental mechanisms, the first being used for insertion, the second being used for deletion, and the third being used to allow readers to tolerate concurrent insertions and deletions. These mechanisms are described in the following sections, which focus on applying RCU to linked lists:
- Publish-Subscribe Mechanism (for insertion)
- Wait For Pre-Existing RCU Readers to Complete (for deletion)
- Maintain Multiple Versions of Recently Updated Objects (for readers)
Publish-Subscribe Mechanism
One key attribute of RCU is the ability to safely scan data, even though that data is being modified concurrently. To provide this ability for concurrent insertion, RCU uses what can be thought of as a publish-subscribe mechanism. For example, consider an initially NULL global pointer gp that is to be modified to point to a newly allocated and initialized data structure. The following code fragment (with the addition of appropriate locking) might be used for this purpose:1
2
3
4
5
6
7
8
9
10
11
12
13
14struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
gp = p;
Unfortunately, there is nothing forcing the compiler and CPU to execute the last four assignment statements in order. If the assignment to gp happens before the initialization of p‘s fields, then concurrent readers could see the uninitialized values. Memory barriers are required to keep things ordered, but memory barriers are notoriously difficult to use. We therefore encapsulate them into a primitive rcu_assign_pointer() that has publication semantics. The last four lines would then be as follows:1
2
3
4p->a = 1;
p->b = 2;
p->c = 3;
rcu_assign_pointer(gp, p);
The rcu_assign_pointer() would publish the new structure, forcing both the compiler and the CPU to execute the assignment to gp after the assignments to the fields referenced by p.
However, it is not sufficient to only enforce ordering at the updater, as the reader must enforce proper ordering as well. Consider for example the following code fragment:1
2
3
4p = gp;
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
Although this code fragment might well seem immune to misordering, unfortunately, the DEC Alpha CPU and value-speculation compiler optimizations can cause the values of p->a, p->b, and p->c to be fetched before the value of p!
Clearly, we need to prevent this sort of skullduggery on the part of both the compiler and the CPU. The rcu_dereference() primitive uses whatever memory-barrier instructions and compiler directives are required for this purpose:1
2
3
4
5
6rcu_read_lock();
p = rcu_dereference(gp);
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();
The rcu_dereference() primitive can thus be thought of as subscribing to a given value of the specified pointer, guaranteeing that subsequent dereference operations will see any initialization that occurred before the corresponding publish (rcu_assign_pointer()) operation. The rcu_read_lock() and rcu_read_unlock() calls are absolutely required: they define the extent of the RCU read-side critical section. Their purpose is explained in the next section, however, they never spin or block, nor do they prevent the list_add_rcu() from executing concurrently.
Although rcu_assign_pointer() and rcu_dereference() can in theory be used to construct any conceivable RCU-protected data structure, in practice it is often better to use higher-level constructs. Therefore, the rcu_assign_pointer() and rcu_dereference() primitives have been embedded in special RCU variants of Linux’s list-manipulation API. Linux has two variants of doubly linked list, the circular struct list_head and the linear struct hlist_head/struct hlist_node pair. The former is laid out as follows, where the green boxes represent the list header and the blue boxes represent the elements in the list.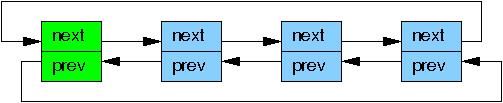
Adapting the pointer-publish example for the linked list gives the following:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15struct foo {
struct list_head list;
int a;
int b;
int c;
};
LIST_HEAD(head);
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
list_add_rcu(&p->list, &head);
Line 15 must be protected by some synchronization mechanism (most commonly some sort of lock) to prevent multiple list_add() instances from executing concurrently. However, such synchronization does not prevent this list_add() from executing concurrently with RCU readers.
Subscribing to an RCU-protected list is straightforward:1
2
3
4
5rcu_read_lock();
list_for_each_entry_rcu(p, head, list) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();
The list_add_rcu() primitive publishes an entry into the specified list, guaranteeing that the corresponding list_for_each_entry_rcu() invocation will properly subscribe to this same entry.
The set of RCU publish and subscribe primitives are shown in the following table, along with additional primitives to “unpublish”, or retract:
Note that the list_replace_rcu(), list_del_rcu(), hlist_replace_rcu(), and hlist_del_rcu() APIs add a complication. When is it safe to free up the data element that was replaced or removed? In particular, how can we possibly know when all the readers have released their references to that data element?
These questions are addressed in the following section.
Wait For Pre-Existing RCU Readers to Complete
In its most basic form, RCU is a way of waiting for things to finish. Of course, there are a great many other ways of waiting for things to finish, including reference counts, reader-writer locks, events, and so on. The great advantage of RCU is that it can wait for each of (say) 20,000 different things without having to explicitly track each and every one of them, and without having to worry about the performance degradation, scalability limitations, complex deadlock scenarios, and memory-leak hazards that are inherent in schemes using explicit tracking.
In RCU’s case, the things waited on are called “RCU read-side critical sections”. An RCU read-side critical section starts with an rcu_read_lock() primitive, and ends with a corresponding rcu_read_unlock() primitive. RCU read-side critical sections can be nested, and may contain pretty much any code, as long as that code does not explicitly block or sleep (although a special form of RCU called “SRCU“ does permit general sleeping in SRCU read-side critical sections). If you abide by these conventions, you can use RCU to wait for any desired piece of code to complete.
RCU accomplishes this feat by indirectly determining when these other things have finished, as has been described elsewhere for RCU Classic and realtime RCU.
In particular, as shown in the following figure, RCU is a way of waiting for pre-existing RCU read-side critical sections to completely finish, including memory operations executed by those critical sections.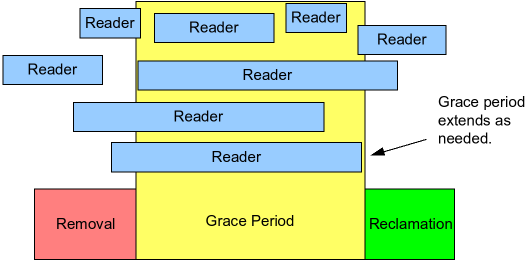
However, note that RCU read-side critical sections that begin after the beginning of a given grace period can and will extend beyond the end of that grace period.
The following pseudocode shows the basic form of algorithms that use RCU to wait for readers:
- Make a change, for example, replace an element in a linked list.
- Wait for all pre-existing RCU read-side critical sections to completely finish (for example, by using the
synchronize_rcu()primitive). The key observation here is that subsequent RCU read-side critical sections have no way to gain a reference to the newly removed element. - Clean up, for example, free the element that was replaced above.
The following code fragment, adapted from those in the previous section, demonstrates this process, with field a being the search key:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21struct foo {
struct list_head list;
int a;
int b;
int c;
};
LIST_HEAD(head);
/* . . . */
p = search(head, key);
if (p == NULL) {
/* Take appropriate action, unlock, and return. */
}
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);
Lines 19, 20, and 21 implement the three steps called out above. Lines 16-19 gives RCU (“read-copy update”) its name: while permitting concurrent reads, line 16 copies and lines 17-19 do an update.
The synchronize_rcu()must wait for all RCU read-side critical sections to complete.
RCU Classic read-side critical sections delimited by rcu_read_lock() and rcu_read_unlock() are not permitted to block or sleep.
What exactly do RCU readers see when traversing a concurrently updated list? This question is addressed in the following section.
Maintain Multiple Versions of Recently Updated Objects
This section demonstrates how RCU maintains multiple versions of lists to accommodate synchronization-free readers. Two examples are presented showing how an element that might be referenced by a given reader must remain intact while that reader remains in its RCU read-side critical section. The first example demonstrates deletion of a list element, and the second example demonstrates replacement of an element.
Example 1: Maintaining Multiple Versions During Deletion
To start the “deletion” example, we will modify lines 11-21 in the example in the previous section as follows:1
2
3
4
5
6p = search(head, key);
if (p != NULL) {
list_del_rcu(&p->list);
synchronize_rcu();
kfree(p);
}
The initial state of the list, including the pointer p, is as follows.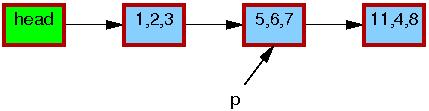
The triples in each element represent the values of fields a, b, and c, respectively. The red borders on each element indicate that readers might be holding references to them, and because readers do not synchronize directly with updaters, readers might run concurrently with this entire replacement process. Please note that we have omitted the backwards pointers and the link from the tail of the list to the head for clarity.
After the list_del_rcu() on line 3 has completed, the 5,6,7 element has been removed from the list, as shown below. Since readers do not synchronize directly with updaters, readers might be concurrently scanning this list. These concurrent readers might or might not see the newly removed element, depending on timing. However, readers that were delayed just after fetching a pointer to the newly removed element might see the old version of the list for quite some time after the removal. Therefore, we now have two versions of the list, one with element 5,6,7 and one without. The border of the 5,6,7 element is still red, indicating that readers might be referencing it.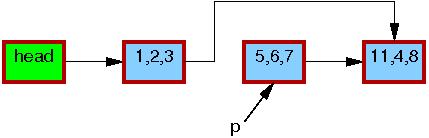
Please note that readers are not permitted to maintain references to element ,5,6,7 after exiting from their RCU read-side critical sections. Therefore, once the synchronize_rcu() on line 4 completes, so that all pre-existing readers are guaranteed to have completed, there can be no more readers referencing this element, as indicated by its black border below. We are thus back to a single version of the list.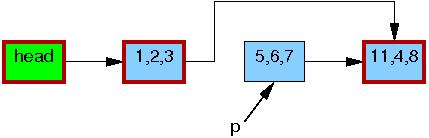
At this point, the 5,6,7 element may safely be freed, as shown below:
At this point, we have completed the deletion of element 5,6,7. The following section covers replacement.
Example 2: Maintaining Multiple Versions During Replacement
To start the replacement example, here are the last few lines of the example in the previous section:1
2
3
4
5
6
7q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);
The initial state of the list, including the pointer p, is the same as for the deletion example: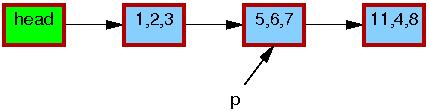
As before, the triples in each element represent the values of fields a, b, and c, respectively. The red borders on each element indicate that readers might be holding references to them, and because readers do not synchronize directly with updaters, readers might run concurrently with this entire replacement process. Please note that we again omit the backwards pointers and the link from the tail of the list to the head for clarity.
Line 1 kmalloc()s a replacement element, as follows: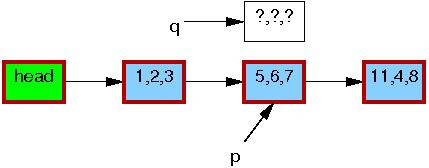
Line 2 copies the old element to the new one: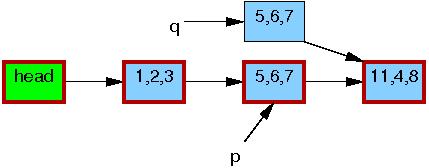
Line 3 updates q->b to the value “2”: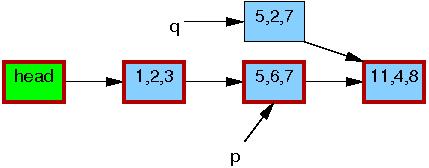
Line 4 updates q->c to the value “3”: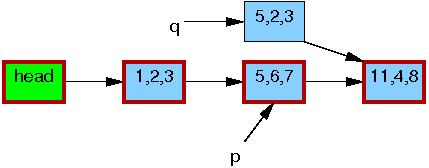
Now, line 5 does the replacement, so that the new element is finally visible to readers. At this point, as shown below, we have two versions of the list. Pre-existing readers might see the 5,6,7 element, but new readers will instead see the 5,2,3 element. But any given reader is guaranteed to see some well-defined list.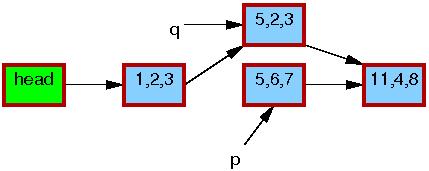
After the synchronize_rcu() on line 6 returns, a grace period will have elapsed, and so all reads that started before the list_replace_rcu() will have completed. In particular, any readers that might have been holding references to the 5,6,7 element are guaranteed to have exited their RCU read-side critical sections, and are thus prohibited from continuing to hold a reference. Therefore, there can no longer be any readers holding references to the old element, as indicated by the thin black border around the 5,6,7 element below. As far as the readers are concerned, we are back to having a single version of the list, but with the new element in place of the old.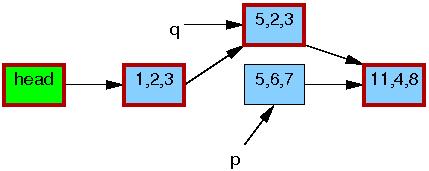
After the kfree() on line 7 completes, the list will appear as follows: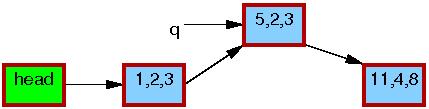
参考资料: