apue 读书笔记-File I/O
文章目录
The functions described in this chapter are often referred to as unbuffered I/O.The term unbuffered means that each read or write invokes a system call in the kernel.
1 Introduction
1.1 File Descriptors
To the kernel, all open files are referred to by file descriptors. A file descriptor is a non-negative integer. When we open an existing file or create a new file, the kernel returns a file descriptor to the process.
By convention, UNIX System shells associate file descriptor 0 with the standard input of a process, file descriptor 1 with the standard output, and file descriptor 2 with the standard error.
Although their values are standardized by POSIX.1, the magic numbers 0, 1, and 2 should be replaced in POSIX-compliant applications with the symbolic constants STDIN_FILENO, STDOUT_FILENO, and STDERR_FILENO to improve readability.
1.2 open and openat Functions
A file is opened or created by calling either the open function or the openat function.
1.3 creat Function
A new file can also be created by calling the creat function.
1.4 close Function
An open file is closed by calling the close function.
When a process terminates, all of its open files are closed automatically by the kernel. Many programs take advantage of this fact and don’t explicitly close open files.
1.5 lseek Function
Every open file has an associated current file offset, normally a non-negative integer that measures the number of bytes from the beginning of the file.
An open file’s offset can be set explicitly by calling lseek.
lseek only records the current file offset within the kernel — it does not cause any I/O to take place. This offset is then used by the next read or write operation.
The file’s offset can be greater than the file’s current size, in which case the next write to the file will extend the file. This is referred to as creating a hole in a file and is allowed. Any bytes in a file that have not been written are read back as 0. A hole in a file isn’t required to have storage backing it on disk.
We use the od command to look at the contents of the file.
1.6 read Function
Data is read from an open file with the read function.
1.7 write Function
Data is written to an open file with the write function.
2 I/O Efficiency
1 |
|
Figure 3.6 shows the results for reading a 516,581,760-byte file, using 20 different buffer sizes.
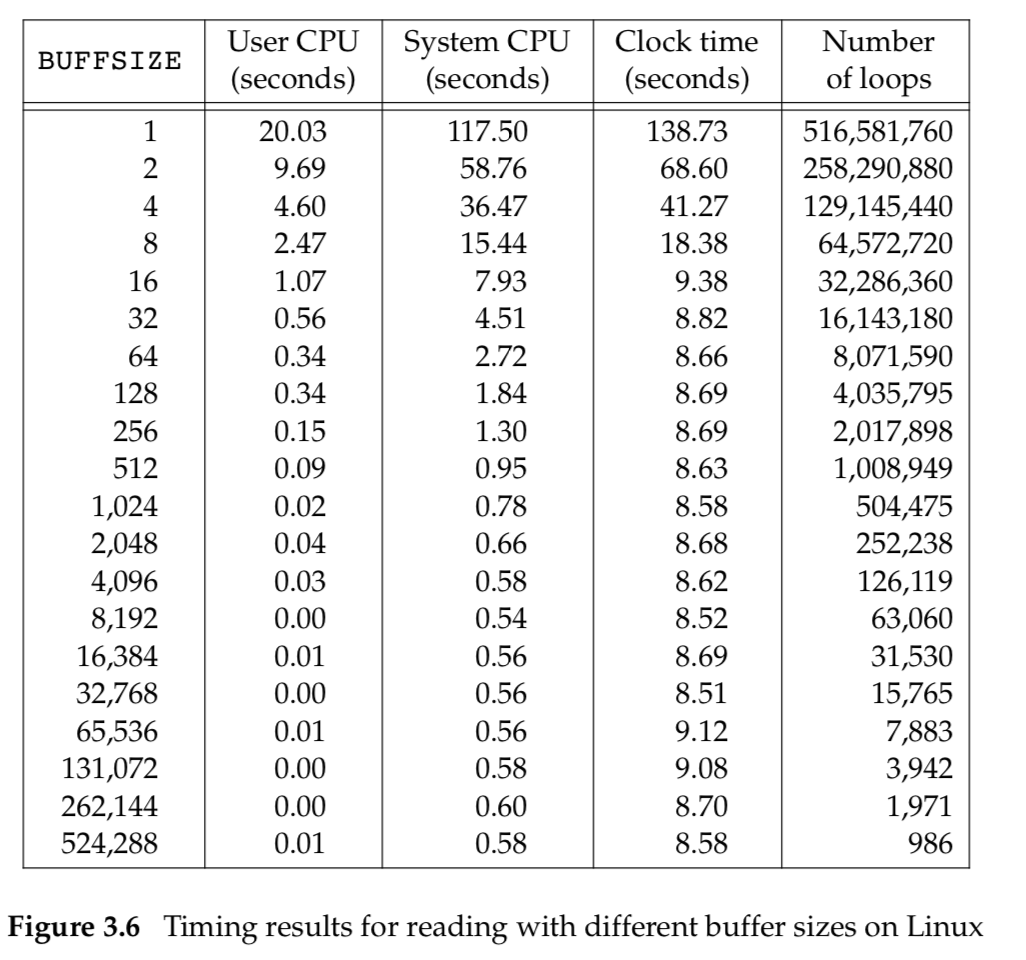
This accounts for the minimum in the system time occurring at the few timing measurements starting around a BUFFSIZE of 4,096. Increasing the buffer size beyond this limit has little positive effect.
Most file systems support some kind of read-ahead to improve performance. When sequential reads are detected, the system tries to read in more data than an application requests, assuming that the application will read it shortly. The effect of read-ahead can be seen in Figure 3.6, where the elapsed time for buffer sizes as small as 32 bytes is as good as the elapsed time for larger buffer sizes.
3 File Sharing
The UNIX System supports the sharing of open files among different processes.
- Every process has an entry in the process table. Within each process table entry is a table of open file descriptors, which we can think of as a vector, with one entry per descriptor. Associated with each file descriptor are:
- The file descriptor flags
- A pointer to a file table entry
- The kernel maintains a file table for all open files. Each file table entry contains:
- The file status flags for the file, such as read, write, append, sync, and nonblocking
- The current file offset
- A pointer to the v-node table entry for the file
- Each open file (or device) has a v-node structure that contains information about the type of file and pointers to functions that operate on the file. For most files, the v-node also contains the i-node for the file. This information is read from disk when the file is opened, so that all the pertinent information about the file is readily available. For example, the i-node contains the owner of the file, the size of the file, pointers to where the actual data blocks for the file are located on disk, and so on.
Linux has no v-node. Instead, a generic i-node structure is used.
Figure 3.7 shows a pictorial arrangement of these three tables for a single process that has two different files open: one file is open on standard input (file descriptor 0), and the other is open on standard output (file descriptor 1).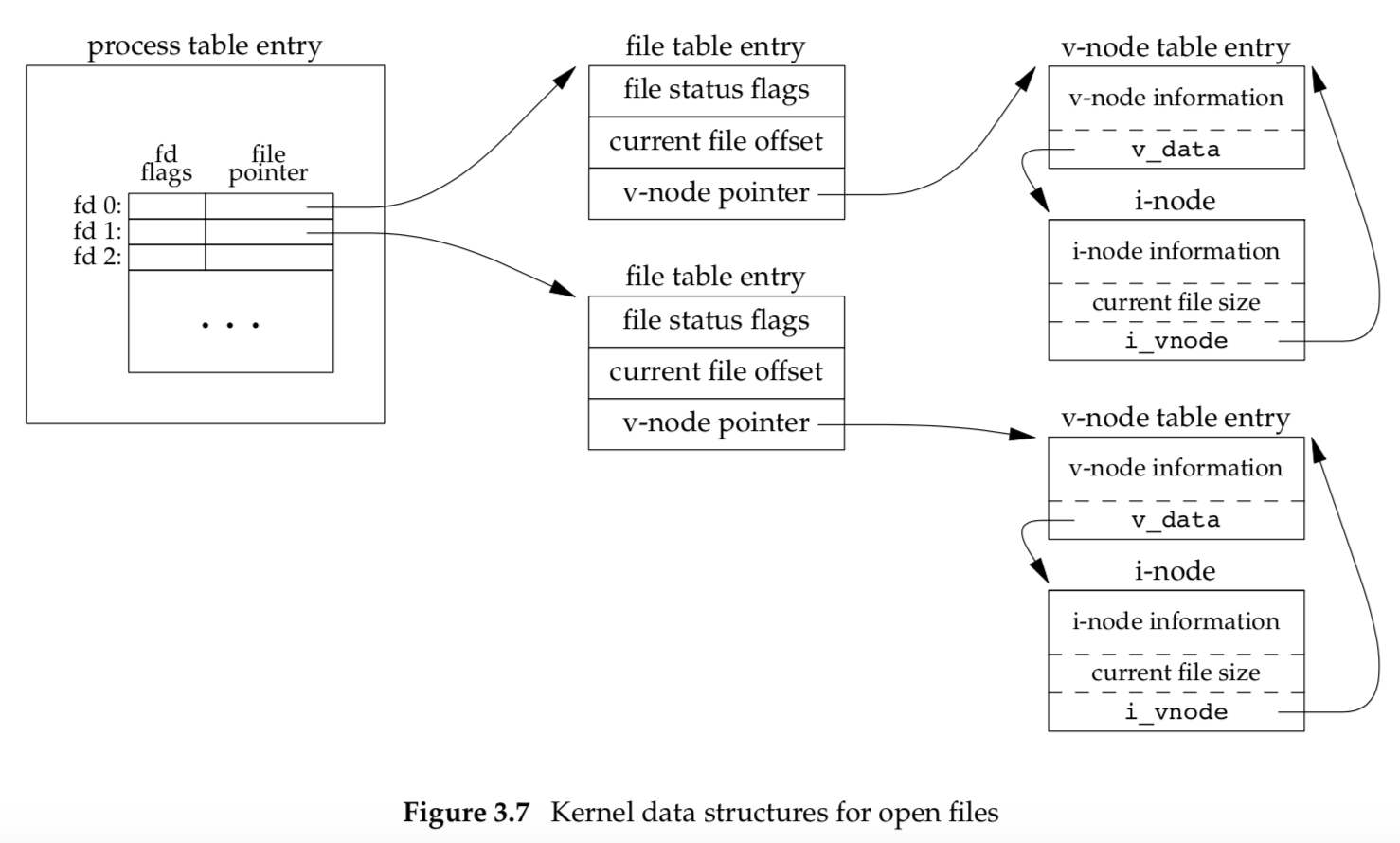
If two independent processes have the same file open, we could have the arrangement shown in Figure 3.8.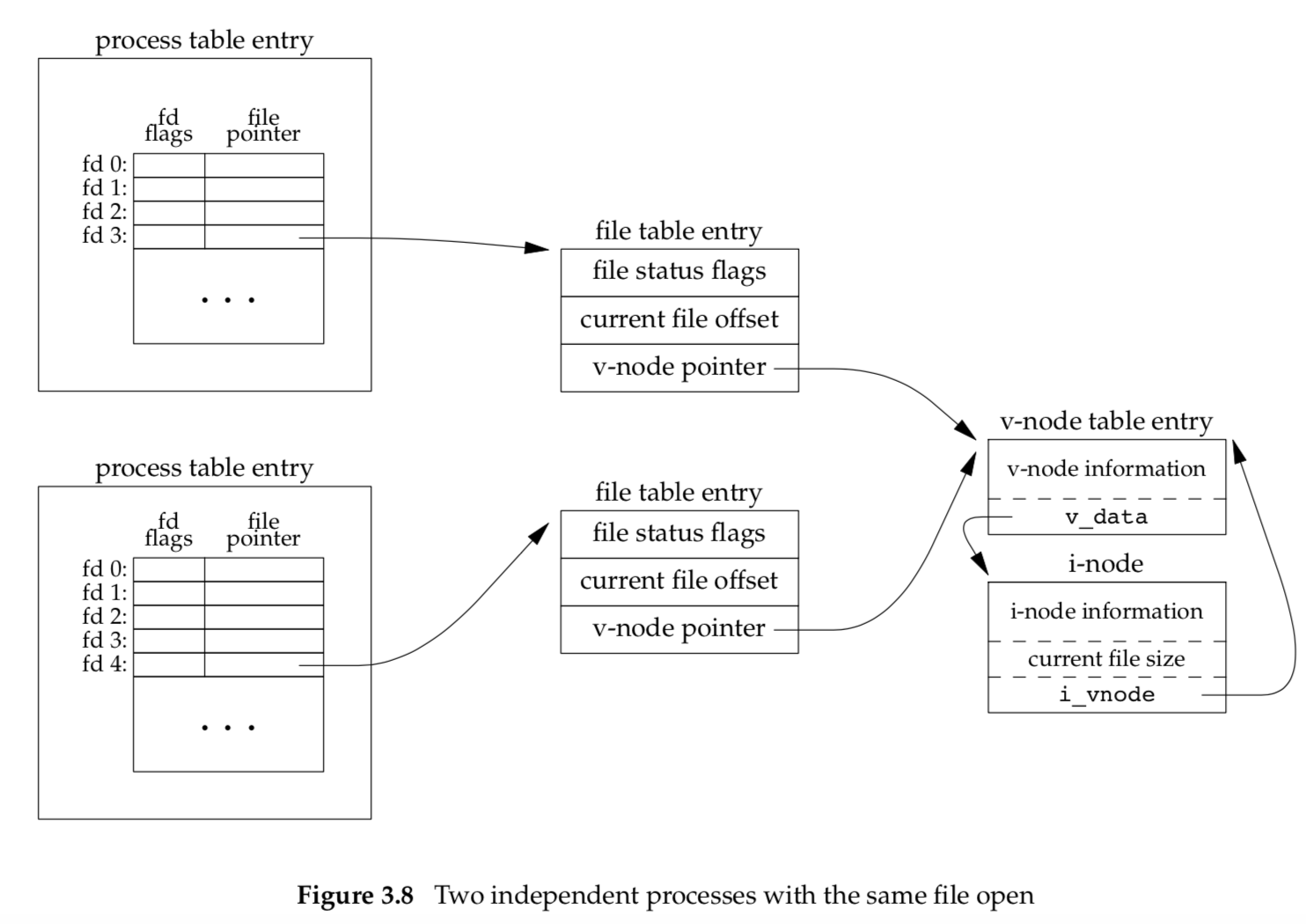
We assume here that the first process has the file open on descriptor 3 and that the second process has that same file open on descriptor 4. Each process that opens the file gets its own file table entry, but only a single v-node table entry is required for a given file. One reason each process gets its own file table entry is so that each process has its own current offset for the file.
4 Atomic Operations
4.1 Appending to a File
Consider a single process that wants to append to the end of a file.This works fine for a single process, but problems arise if multiple processes use this technique to append to the same file. (This scenario can arise if multiple instances of the same program are appending messages to a log file, for example.)
Assume that two independent processes, A and B, are appending to the same file. Each has opened the file but without the O_APPEND flag. This gives us the same picture as Figure 3.8. Each process has its own file table entry, but they share a single v-node table entry. Assume that process A does the lseek and that this sets the current offset for the file for process A to byte offset 1,500 (the current end of file). Then the kernel switches processes, and B continues running. Process B then does the lseek, which sets the current offset for the file for process B to byte offset 1,500 also (the current end of file). Then B calls write, which increments B’s current file offset for the file to 1,600. Because the file’s size has been extended, the kernel also updates the current file size in the v-node to 1,600. Then the kernel switches processes and A resumes. When A calls write, the data is written starting at the current file offset for A, which is byte offset 1,500. This overwrites the data that B wrote to the file.
The problem here is that our logical operation of ‘‘position to the end of file and write’’ requires two separate function calls (as we’ve shown it). The solution is to have the positioning to the current end of file and the write be an atomic operation with regard to other processes. Any operation that requires more than one function call cannot be atomic, as there is always the possibility that the kernel might temporarily suspend the process between the two function calls (as we assumed previously).
The UNIX System provides an atomic way to do this operation if we set the O_APPEND flag when a file is opened. As we described in the previous section, this causes the kernel to position the file to its current end of file before each write. We no longer have to call lseek before each write.
4.2 pread and pwrite Functions
Calling pread is equivalent to calling lseek followed by a call to read, with the following exceptions.
- There is no way to interrupt the two operations that occur when we call
pread. - The current file offset is not updated.
4.3 Creating a File
When O_CREAT and O_EXCL options for the open function are specified, the open will fail if the file already exists. We also said that the check for the existence of the file and the creation of the file was performed as an atomic operation. If we didn’t have this atomic operation, we might try:1
2
3
4
5
6
7
8 if ((fd = open(path, O_WRONLY)) < 0) {
if (errno == ENOENT) {
if ((fd = creat(path, mode)) < 0)
err_sys("creat error");
} else {
err_sys("open error");
}
}
The problem occurs if the file is created by another process between the open and the creat. If the file is created by another process between these two function calls, and if that other process writes something to the file, that data is erased when this creat is executed. Combining the test for existence and the creation into a single atomic operation avoids this problem.
In general, the term atomic operation refers to an operation that might be composed of multiple steps. If the operation is performed atomically, either all the steps are performed (on success) or none are performed (on failure). It must not be possible for only a subset of the steps to be performed.
5 dup and dup2 Functions
An existing file descriptor is duplicated by either of the following functions:1
2int dup(int fd);
int dup2(int fd, int fd2);
The new file descriptor returned by dup is guaranteed to be the lowest-numbered available file descriptor.
The new file descriptor that is returned as the value of the functions shares the same file table entry as the fd argument. We show this in Figure 3.9.
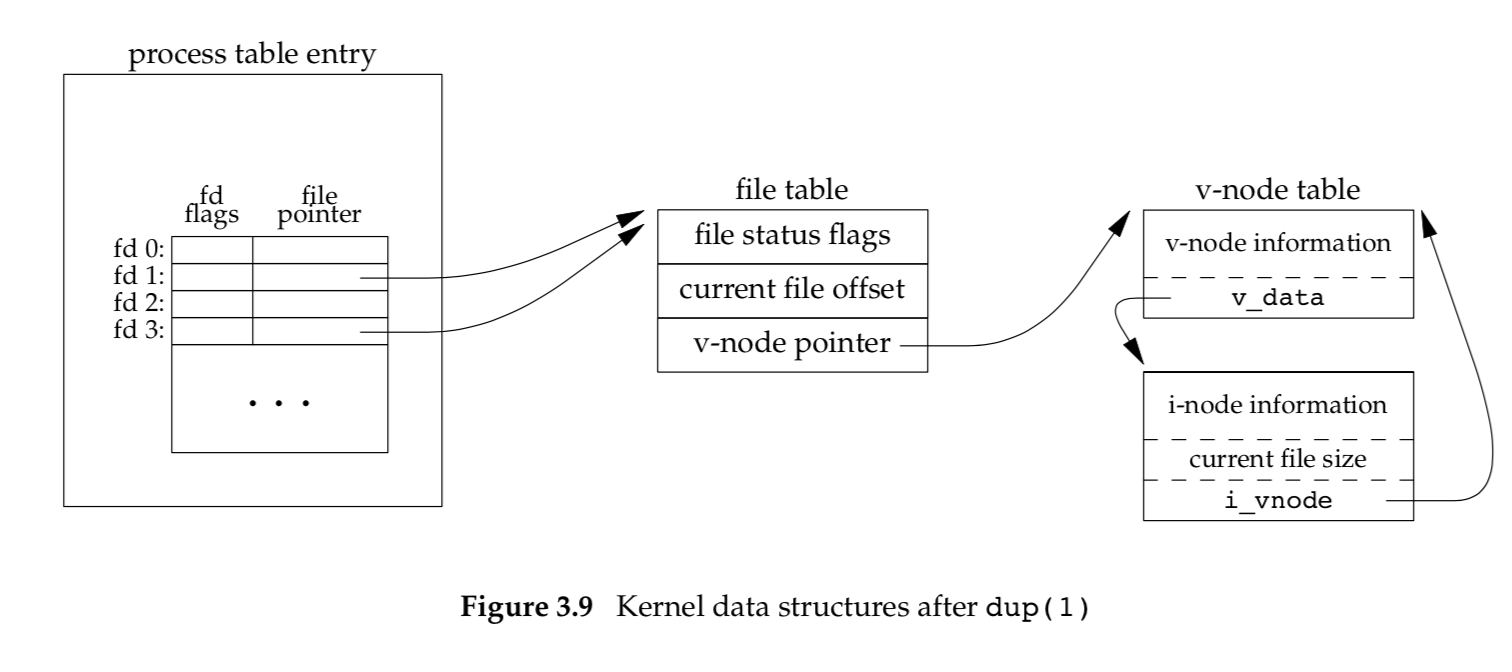
Each descriptor has its own set of file descriptor flags.
6 sync, fsync, and fdatasync Functions
Traditional implementations of the UNIX System have a buffer cache or page cache in the kernel through which most disk I/O passes. When we write data to a file, the data is normally copied by the kernel into one of its buffers and queued for writing to disk at some later time. This is called delayed write.
The kernel eventually writes all the delayed-write blocks to disk.
To ensure consistency of the file system on disk with the contents of the buffer cache, the sync, fsync, and fdatasync functions are provided.1
2
3int fsync(int fd);
int fdatasync(int fd);
void sync(void);
The sync function simply queues all the modified block buffers for writing and returns; it does not wait for the disk writes to take place.
The function sync is normally called periodically (usually every 30 seconds) from a system daemon, often called update. This guarantees regular flushing of the kernel’s block buffers.
The function fsync refers only to a single file, specified by the file descriptor fd, and waits for the disk writes to complete before returning. This function is used when an application, such as a database, needs to be sure that the modified blocks have been written to the disk.
The fdatasync function is similar to fsync, but it affects only the data portions of a file. With fsync, the file’s attributes are also updated synchronously.
7 fcntl Function
The fcntl function can change the properties of a file that is already open.
The fcntl function is used for five different purposes.
- Duplicate an existing descriptor (cmd =
F_DUPFDorF_DUPFD_CLOEXEC) - Get/set file descriptor flags (cmd =
F_GETFDorF_SETFD) - Get/set file status flags (cmd =
F_GETFLorF_SETFL) - Get/set asynchronous I/O ownership (cmd =
F_GETOWNorF_SETOWN) - Get/set record locks (cmd =
F_GETLK,F_SETLK, orF_SETLKW)
8 ioctl Function
The ioctl function has always been the catchall for I/O operations.
Terminal I/O was the biggest user of this function.Each device driver can define its own set of ioctl commands. The system, however, provides generic ioctl commands for different classes of devices.
9 /dev/fd
Newer systems provide a directory named /dev/fd whose entries are files named 0, 1, 2, and so on.
The main use of the /dev/fd files is from the shell. It allows programs that use pathname arguments to handle standard input and standard output in the same manner as other pathnames.