apue 读书笔记- Process Control
文章目录
1 Process Identifiers
Every process has a unique process ID, a non-negative integer. The process ID is the only well-known identifier of a process that is always unique.
Process ID 0 is usually the scheduler process.
Process ID 1 is usually the init process and is invoked by the kernel at the end of the bootstrap procedure.
2 fork Function
An existing process can create a new one by calling the fork function.
The new process created by fork is called the child process. This function is called once but returns twice. The only difference in the returns is that the return value in the child is 0, whereas the return value in the parent is the process ID of the new child.
File Sharing
One characteristic of fork is that all file descriptors that are open in the parent are duplicated in the child. We say ‘‘duplicated’’ because it’s as if the dup function had been called for each descriptor. The parent and the child share a file table entry for every open descriptor.
Consider a process that has three different files opened for standard input, standard output, and standard error. On return from fork, we have the arrangement shown in Figure 8.2.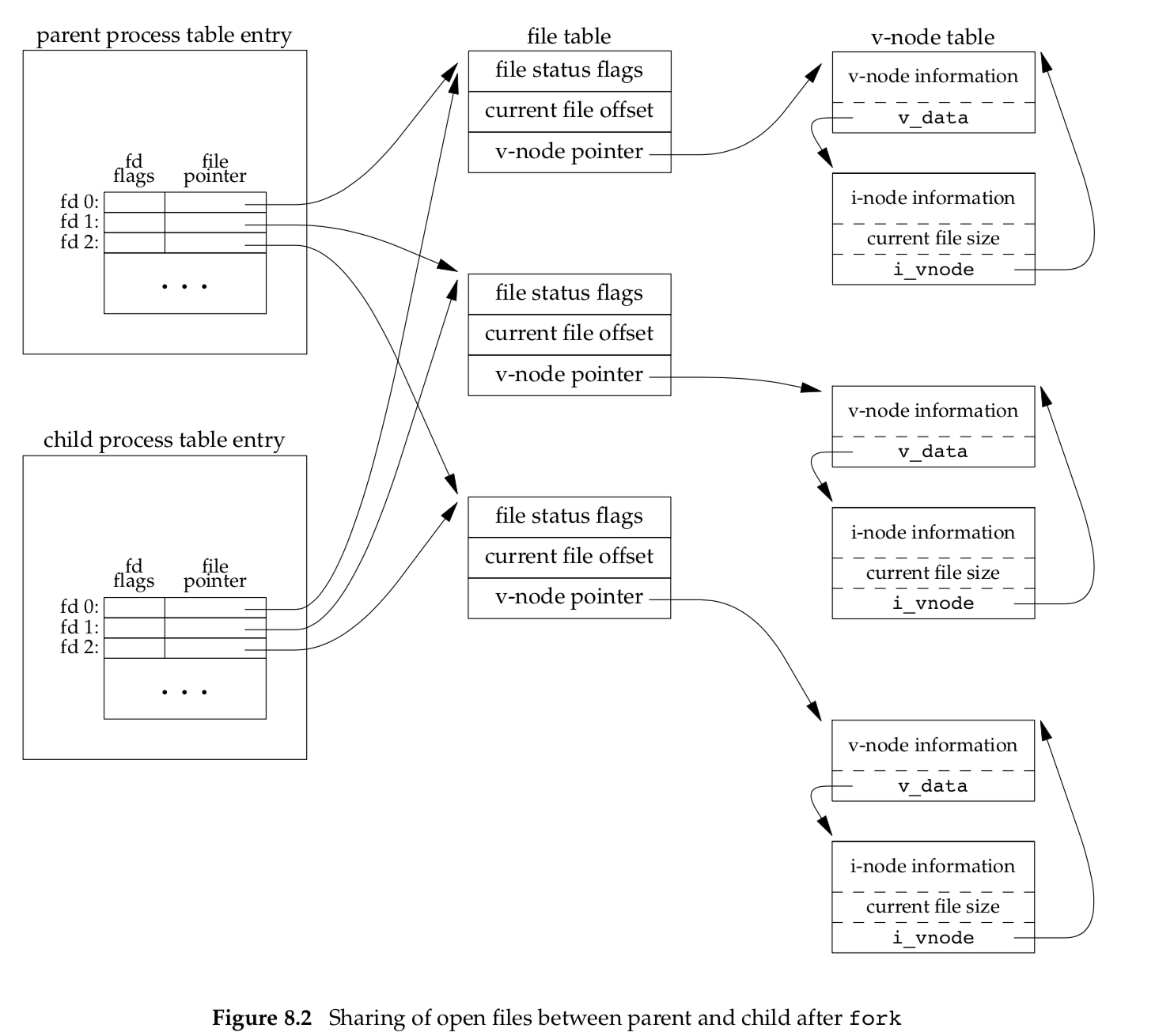
It is important that the parent and the child share the same file offset.
3 exit Functions
Regardless of how a process terminates, the same code in the kernel is eventually executed. This kernel code closes all the open descriptors for the process, releases the memory that it was using, and so on.
For any of the preceding cases, we want the terminating process to be able to notify its parent how it terminated. For the three exit functions (exit, _exit, and _Exit), this is done by passing an exit status as the argument to the function. In the case of an abnormal termination, however, the kernel—not the process—generates a termination status to indicate the reason for the abnormal termination. In any case, the parent of the process can obtain the termination status from either the wait or the waitpid function.
What happens if the parent terminates before the child? The answer is that the init process becomes the parent process of any process whose parent terminates. In such a case, we say that the process has been inherited by init.
Another condition we have to worry about is when a child terminates before its parent. If the child completely disappeared, the parent wouldn’t be able to fetch its termination status when and if the parent was finally ready to check if the child had terminated. The kernel keeps a small amount of information for every terminating process, so that the information is available when the parent of the terminating process calls wait or waitpid. Minimally, this information consists of the process ID, the termination status of the process, and the amount of CPU time taken by the process. The kernel can discard all the memory used by the process and close its open files. In UNIX System terminology, a process that has terminated, but whose parent has not yet waited for it, is called a zombie. The ps command prints the state of a zombie process as Z.
The final condition to consider is this: What happens when a process that has been inherited by init terminates? Does it become a zombie? The answer is ‘‘no,’’ because init is written so that whenever one of its children terminates, init calls one of the wait functions to fetch the termination status. By doing this, init prevents the system from being clogged by zombies.
4 wait and waitpid Functions
When a process terminates, either normally or abnormally, the kernel notifies the parent by sending the SIGCHLD signal to the parent. Because the termination of a child is an asynchronous event—it can happen at any time while the parent is running—this signal is the asynchronous notification from the kernel to the parent. The parent can choose to ignore this signal, or it can provide a function that is called when the signal occurs: a signal handler. The default action for this signal is to be ignored. For now, we need to be aware that a process that calls wait or waitpid can:
- Block, if all of its children are still running
- Return immediately with the termination status of a child, if a child has terminated and is waiting for its termination status to be fetched
- Return immediately with an error, if it doesn’t have any child processes
If the process is calling wait because it received the SIGCHLD signal, we expect wait to return immediately. But if we call it at any random point in time, it can block.1
2pid_t wait(int *statloc);
pid_t waitpid(pid_t pid, int *statloc, int options);
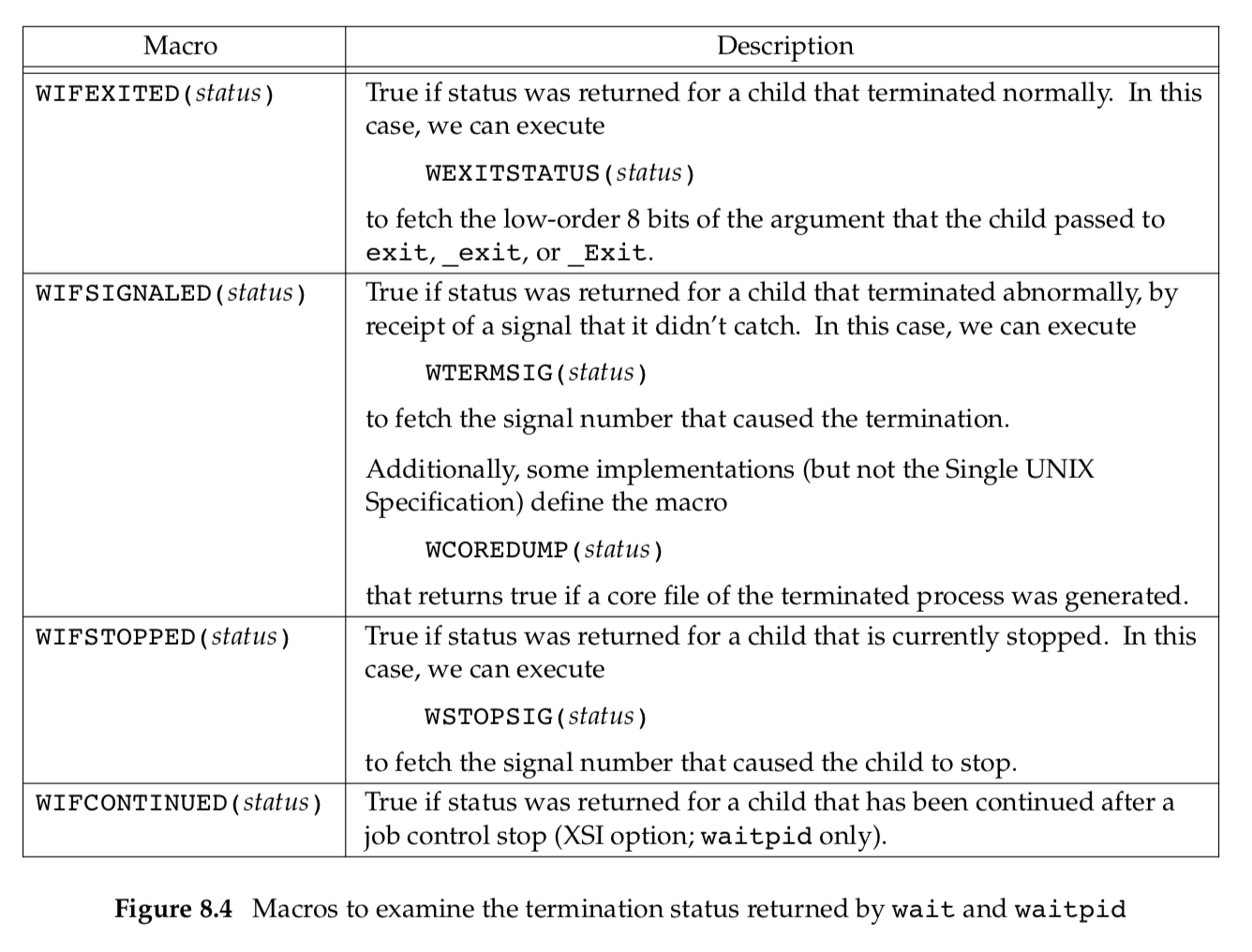
The waitpid function provides three features that aren’t provided by the wait
function.
- The
waitpidfunction lets us wait for one particular process, whereas thewaitfunction returns the status of any terminated child. - The
waitpidfunction provides a nonblocking version ofwait. There are times when we want to fetch a child’s status, but we don’t want to block. - The
waitpidfunction provides support for job control with theWUNTRACEDandWCONTINUEDoptions.
5 waitid Function
6 wait3 and wait4 Functions
7 exec Functions
One use of the fork function is to create a new process (the child) that then causes another program to be executed by calling one of the exec functions. When a process calls one of the exec functions, that process is completely replaced by the new program, and the new program starts executing at its main function. The process ID does not change across an exec, because a new process is not created; exec merely replaces the current process—its text, data, heap, and stack segments—with a brand-new program from disk.
With fork, we can create new processes; and with the exec functions, we can initiate new programs. The exit function and the wait functions handle termination and waiting for termination. These are the only process control primitives we need.
8 Changing User IDs and Group IDs
9 Interpreter Files
10 system Function
1 | int system(const char *cmdstring); |
11 Process Accounting
Most UNIX systems provide an option to do process accounting. When enabled, the kernel writes an accounting record each time a process terminates. These accounting records typically contain a small amount of binary data with the name of the command, the amount of CPU time used, the user ID and group ID, the starting time, and so on.
12 User Identification
13 Process Scheduling
The UNIX System provided processes with only coarse control over their scheduling priority. The scheduling policy and priority were determined by the kernel. A process could choose to run with lower priority by adjusting its nice value (thus a process could be ‘‘nice’’ and reduce its share of the CPU by adjusting its nice value). Only a privileged process was allowed to increase its scheduling priority.
14 Process Times
1 | clock_t times(struct tms *buf); |
This function fills in the tms structure pointed to by buf :1
2
3
4
5
6struct tms {
clock_t tms_utime; /* user CPU time */
clock_t tms_stime; /* system CPU time */
clock_t tms_cutime; /* user CPU time, terminated children */
clock_t tms_cstime; /* system CPU time, terminated children */
};