Understanding the Linux Kernel 读书笔记 -Process Scheduling
文章目录
This chapter deals with scheduling, which is concerned with when to switch and which process to choose.
1 Scheduling Policy
The set of rules used to determine when and how to select a new process to run is called scheduling policy.
Linux scheduling is based on the time sharing technique: several processes run in “time multiplexing” because the CPU time is divided into slices, one for each runnable process.
Programmers may change the scheduling priorities by means of the system calls illustrated in Table 7-1.

1.1 Process Preemption
Linux processes are preemptable. When a process enters the TASK_RUNNING state, the kernel checks whether its dynamic priority is greater than the priority of the currently running process. If it is, the execution of current is interrupted and the scheduler is invoked to select another process to run (usually the process that just became runnable).
Be aware that a preempted process is not suspended, because it remains in the TASK_ RUNNING state; it simply no longer uses the CPU.
1.2 How Long Must a Quantum Last?
The quantum[时间片] duration is critical for system performance: it should be neither too long nor too short.
2 The Scheduling Algorithm
The Multi-Level Feedback Queue
2.1 Scheduling of Conventional Processes
- Base time quantum
- Dynamic priority and average sleep time
- Active and expired processes
2.2 Scheduling of Real-Time Processes
3 Data Structures Used by the Scheduler
The runqueue lists link the process descriptors of all runnable processes—that is, of those in a TASK_RUNNING state—except the swapper process (idle process).
3.1 The runqueue Data Structure
The runqueue data structure.
Each CPU in the system has its own runqueue; all runqueue structures are stored in the runqueues per-CPU variable.
The most important fields of the runqueue data structure are those related to the lists of runnable processes.
The arrays field of the runqueue is an array consisting of two prio_array_t structures. Each data structure represents a set of runnable processes, and includes 140 doubly linked list heads (one list for each possible process priority), a priority bitmap, and a counter of the processes included in the set.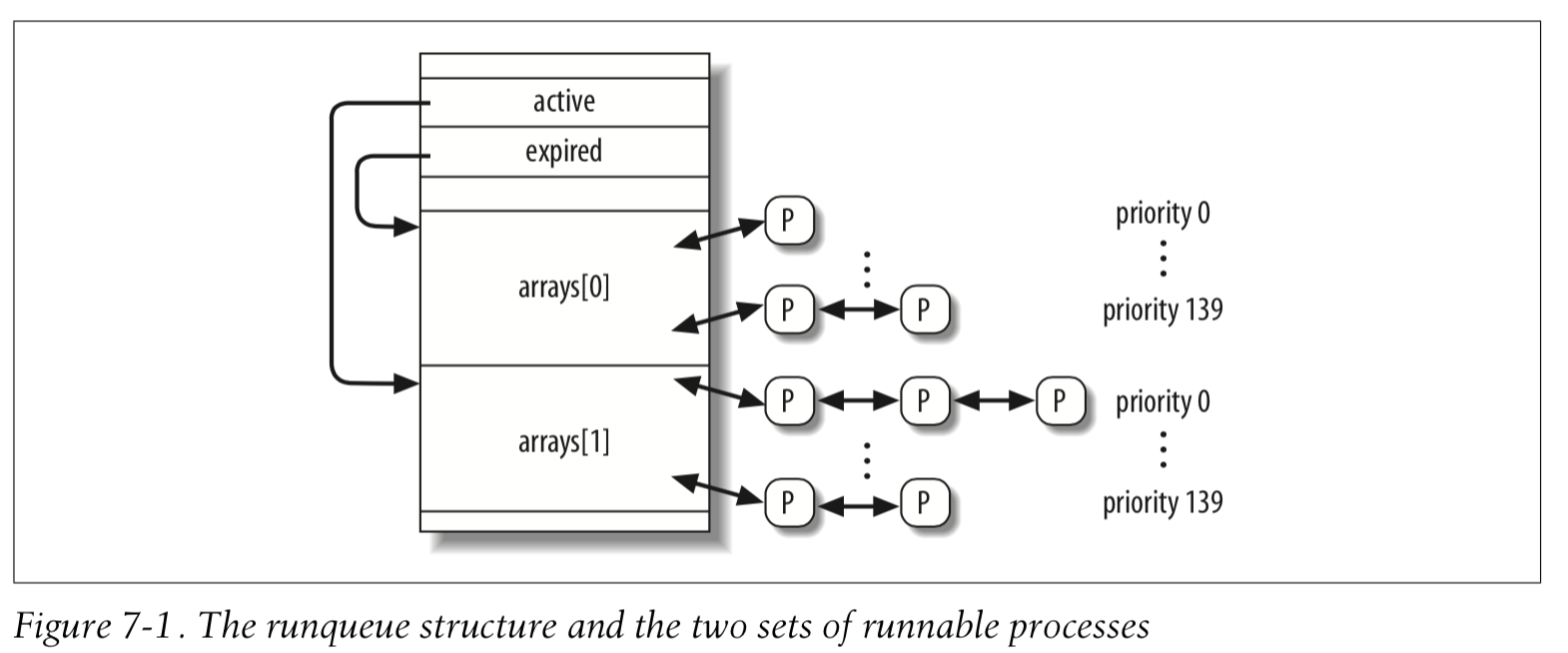
3.2 Process Descriptor
Each process descriptor includes several fields related to scheduling.
4 Functions Used by the Scheduler
The scheduler relies on several functions in order to do its work; the most important are:
scheduler_tick()
Keeps the time_slice counter of current up-to-date
try_to_wake_up()
Awakens a sleeping process
recalc_task_prio()
Updates the dynamic priority of a process
schedule()
Selects a new process to be executed
load_balance()
Keeps the runqueues of a multiprocessor system balanced
5 Runqueue Balancing in Multiprocessor Systems
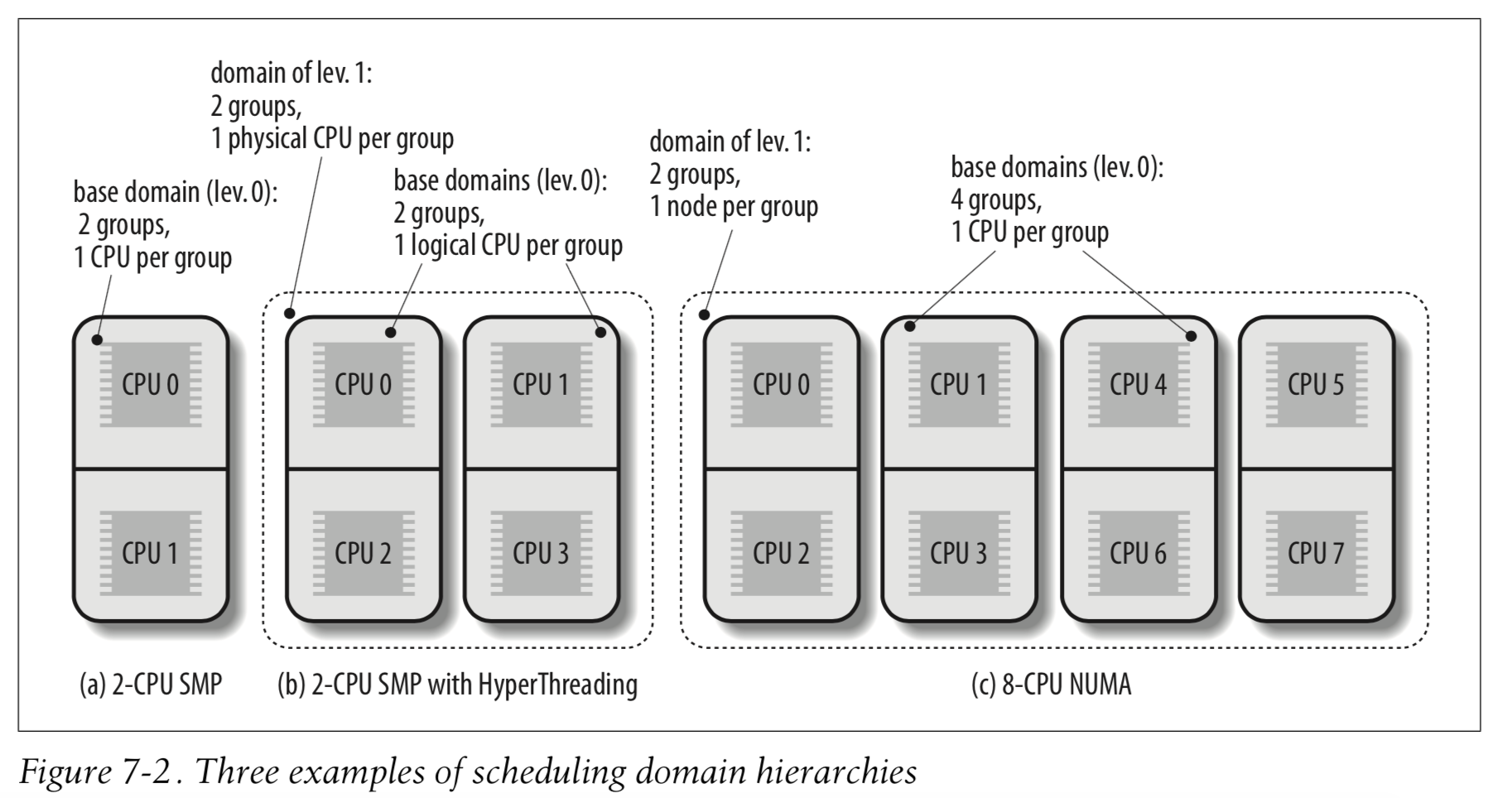
Multiprocessor machines come in many different flavors, and the scheduler behaves differently depending on the hardware characteristics. In particular, we will consider the following three types of multiprocessor machines:
- Classic multiprocessor architecture
Until recently, this was the most common architecture for multiprocessor machines. These machines have a common set of RAM chips shared by all CPUs.
- Hyper-threading
A hyper-threaded chip is a microprocessor that executes several threads of execution at once; it includes several copies of the internal registers and quickly switches between them. This technology allows the processor to exploit the machine cycles to execute another thread while the current thread is stalled for a memory access. A hyper-threaded physical CPU is seen by Linux as several different logical CPUs.
- NUMA
These basic kinds of multiprocessor systems are often combined. For instance, a motherboard that includes two different hyper-threaded CPUs is seen by the kernel as four logical CPUs.
A runnable process is always stored in exactly one runqueue: no runnable process ever appears in two or more runqueues. Therefore, until a process remains runnable, it is usually bound to one CPU.
This design choice is usually beneficial for system performance, because the hardware cache of every CPU is likely to be filled with data owned by the runnable processes in the runqueue. In some cases, however, binding a runnable process to a given CPU might induce a severe performance penalty. For instance, consider a large number of batch processes that make heavy use of the CPU: if most of them end up in the same runqueue, one CPU in the system will be overloaded, while the others will be nearly idle.
Therefore, the kernel periodically checks whether the workloads of the runqueues are balanced and, if necessary, moves some process from one runqueue to another. However, to get the best performance from a multiprocessor system, the load balancing algorithm should take into consideration the topology of the CPUs in the system. Linux sports a sophisticated runqueue balancing algorithm based on the notion of “scheduling domains.” Thanks to the scheduling domains, the algorithm can be easily tuned for all kinds of existing multiprocessor architectures.
5.1 Scheduling Domains
Essentially, a scheduling domain is a set of CPUs whose workloads should be kept balanced by the kernel. Generally speaking, scheduling domains are hierarchically organized: the top-most scheduling domain, which usually spans all CPUs in the system, includes children scheduling domains, each of which include a subset of the CPUs. Thanks to the hierarchy of scheduling domains, workload balancing can be done in a rather efficient way.
Figure 7-2 illustrates three examples of scheduling domain hierarchies, corresponding to the three main architectures of multiprocessor machines.