CPU Cache
文章目录
1. 为什么要有CPU Cache
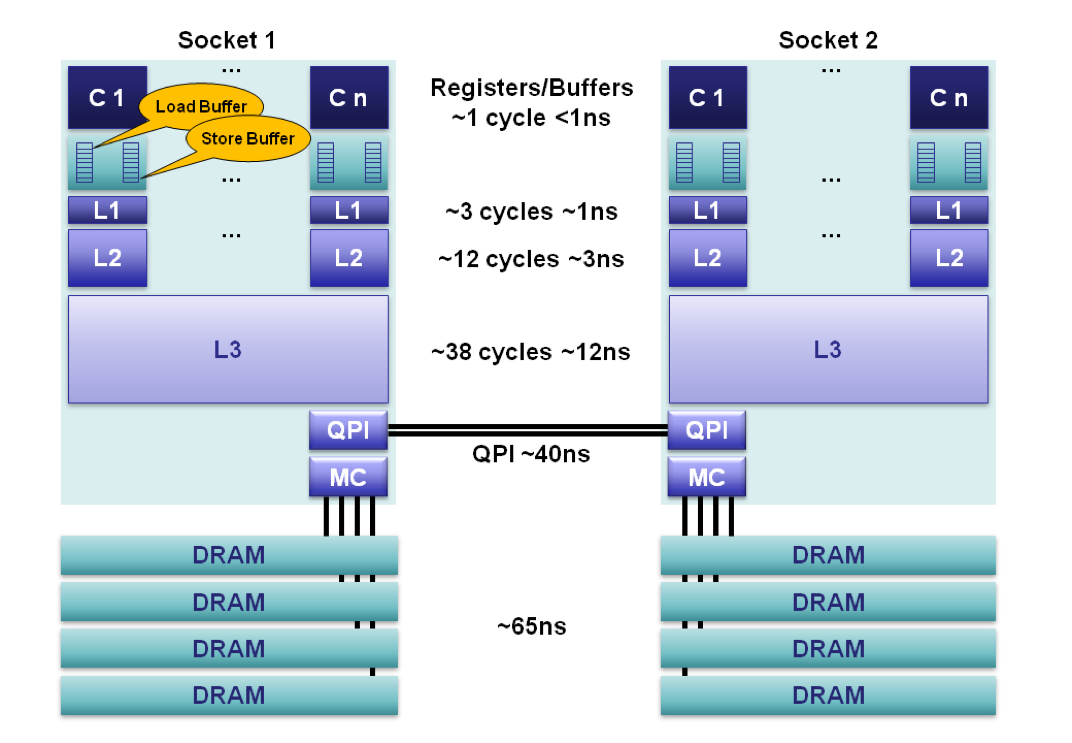
2. 为什么要有多级CPU Cache
Soon after the introduction of the cache the system got more complicated. The speed difference between the cache and the main memory increased again, to a point that another level of cache was added, bigger and slower than the first-level cache. Only increasing the size of the first-level cache was not an option for economical reasons.
此外,又由于程序指令和程序数据的行为和热点分布差异很大,因此L1 Cache也被划分成L1i (i for instruction)和L1d (d for data)两种专门用途的缓存。
3. CPU Cache 是如何存放数据的
如果对这部分知识有些遗忘,可以看下cse378即可。
3.1 为什么Cache不能做成Direct Mapped
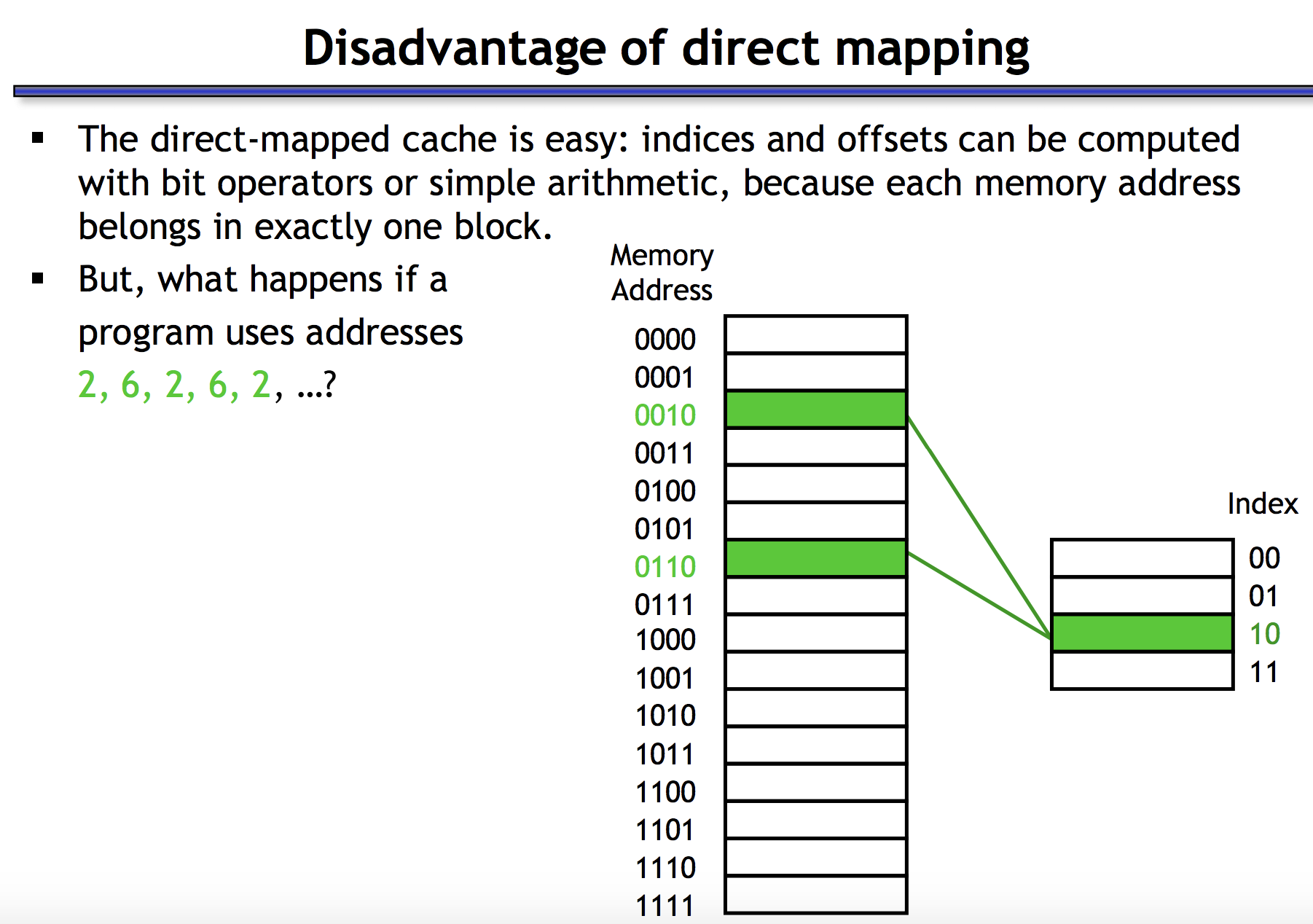
Direct-Mapped Cache is simplier (requires just one comparator and one multiplexer), as a result is cheaper and works faster. Given any address, it is easy to identify the single entry in cache, where it can be. A major drawback when using DM cache is called a conflict miss, when two different addresses correspond to one entry in the cache. Even if the cache is big and contains many stale entries, it can’t simply evict those, because the position within cache is predetermined by the address.
3.2 为什么Cache不能做成Fully Associative
Full Associative Cache is much more complex, and it allows to store an address into any entry. There is a price for that. In order to check if a particular address is in the cache, it has to compare all current entries (the tags to be exact).
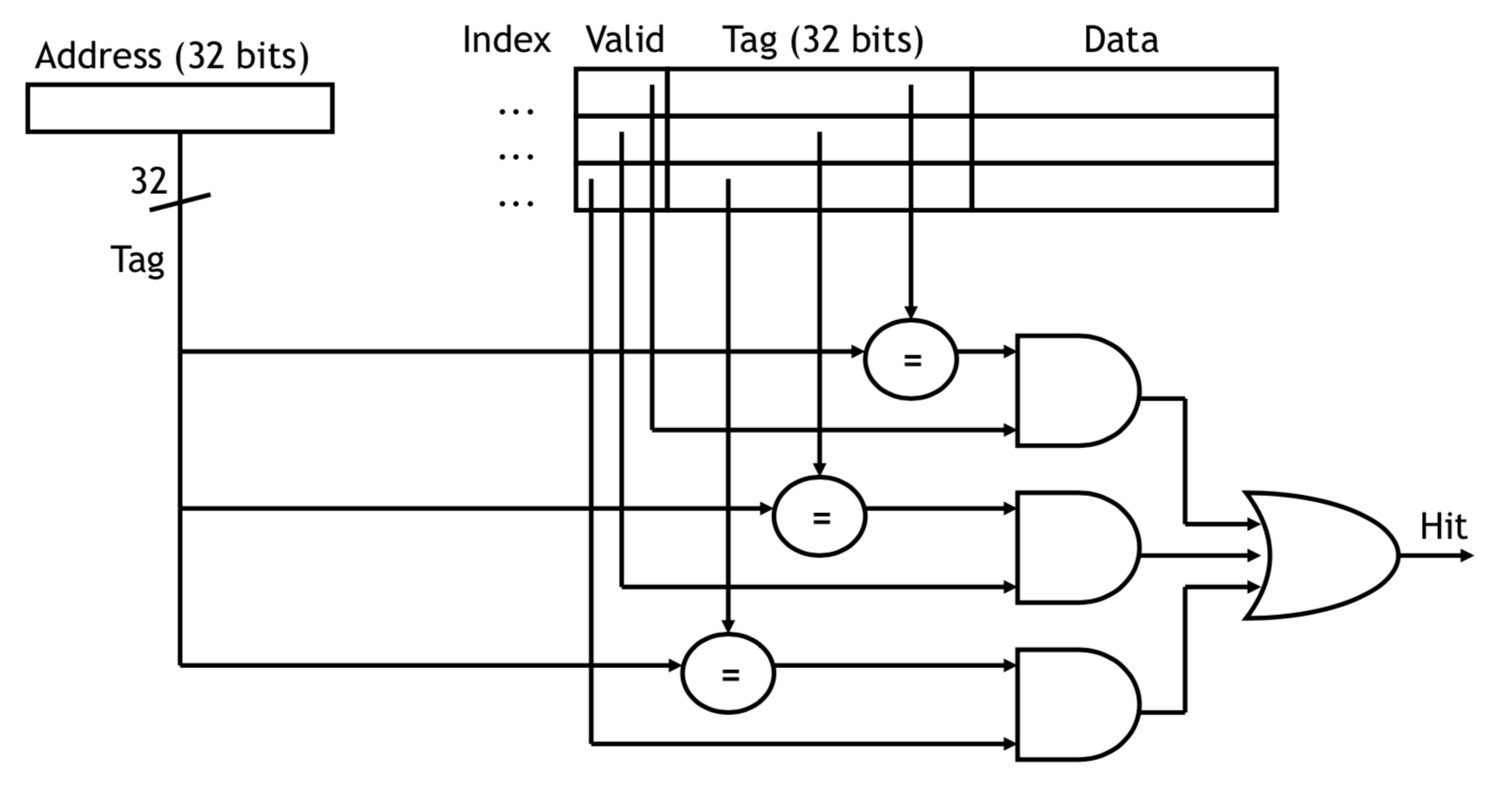
3.3 什么是N-Way Set Associative

阅读Gallery of Processor Cache Effects和7个示例科普CPU CACHE可以加深对N-Way Set Associative的理解。
参考资料: