CPU Cache一致性问题
文章目录
本文首先介绍下产生CPU cache一致性问题的原因,然后给出CPU cache一致性的定义,最后给出解决CPU Cache一致性问题的解决方案。
1. 为什么会有CPU cache一致性问题?
在多处理器架构中,每个处理器都拥有自己的CPU Cache,同时这些处理器共享内存资源。这样会导致多个处理器的CPU cache缓存了相同的内存数据块(以Cache Line为粒度),此时可能会出现cache不一致问题。为了直观地展示Cache不一致问题,下图给出了一个具体的例子: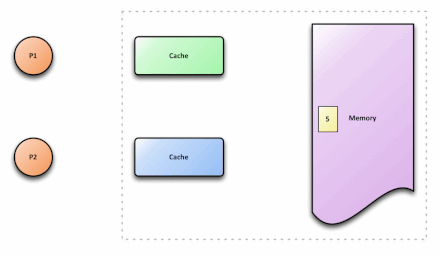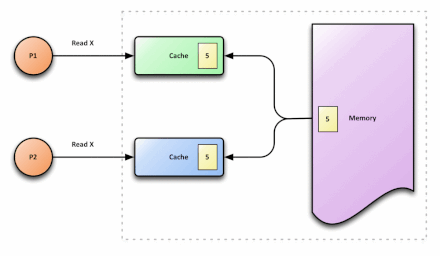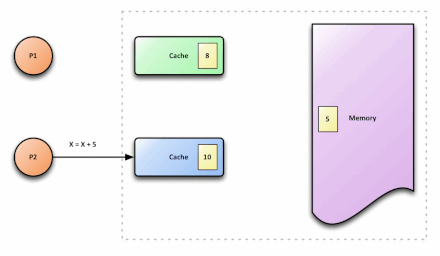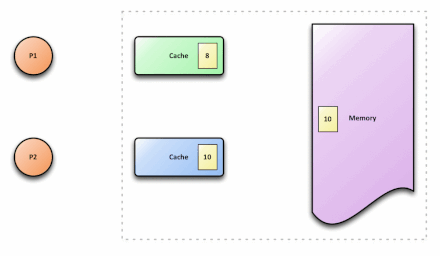
p1和p2代表两个不同的处理器,在内存中,x的值为5。p1和p2都需要读取x,因而会将x读取到各自的cache中,此时,在cache中,x的值都为5。p1执行x=x+3时,在p1的cache中,x=8。与此同时,p2执行x=x+5,在p2的cache中,x=10。之后,写回p1的cache数据,此时,在内存中,x的值为8。接着,写回p2的cache数据,此时,在内存中,x的值为10。此刻,就出现了cache不一致问题:p1 cache中的x值与p2 cache中的x值不同。
下图展示了cache一致的结果: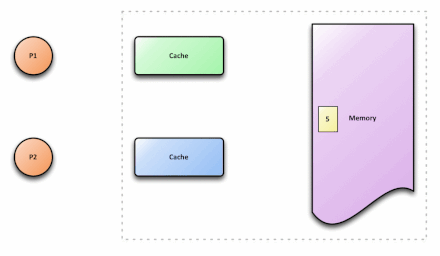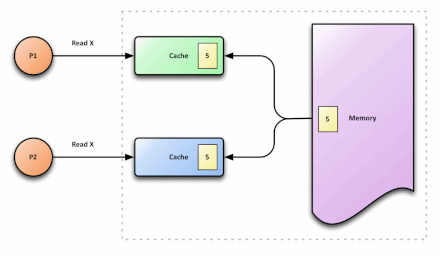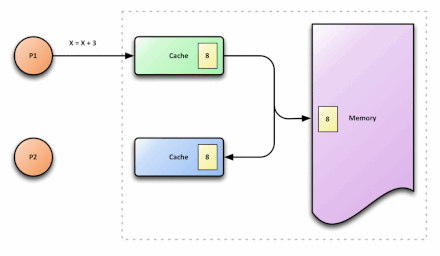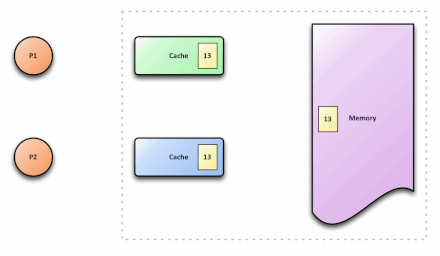
In a shared memory multiprocessor system with a separate cache memory for each processor, it is possible to have many copies of shared data: one copy in the main memory and one in the local cache of each processor that requested it. When one of the copies of data is changed, the other copies must reflect that change. Cache coherence is the discipline which ensures that the changes in the values of shared operands(data) are propagated throughout the system in a timely fashion.
The following are the requirements for cache coherence:
Write Propagation
Changes to the data in any cache must be propagated to other copies (of that cache line) in the peer caches.Transaction Serialization
Reads/Writes to a single memory location must be seen by all processors in the same order.
2. CPU cache一致性的定义
Coherence defines the behavior of reads and writes to a single address location.
In a multiprocessor system, consider that more than one processor has cached a copy of the memory location X. The following conditions are necessary to achieve cache coherence:
- In a read made by a processor P to a location X that follows a write by the same processor P to X, with no writes to X by another processor occurring between the write and the read instructions made by P, X must always return the value written by P.
- In a read made by a processor P1 to location X that follows a write by another processor P2 to X, with no other writes to X made by any processor occurring between the two accesses and with the read and write being sufficiently separated, X must always return the value written by P2. This condition defines the concept of coherent view of memory. Propagating the writes to the shared memory location ensures that all the caches have a coherent view of the memory. If processor P1 reads the old value of X, even after the write by P2, we can say that the memory is incoherent.
The above conditions satisfy the Write Propagation criteria required for cache coherence. However, they are not sufficient as they do not satisfy the Transaction Serialization condition. To illustrate this better, consider the following example:
A multi-processor system consists of four processors - P1, P2, P3 and P4, all containing cached copies of a shared variable S whose initial value is 0. Processor P1 changes the value of S (in its cached copy) to 10 following which processor P2 changes the value of S in its own cached copy to 20. If we ensure only write propagation, then P3 and P4 will certainly see the changes made to S by P1 and P2. However, P3 may see the change made by P1 after seeing the change made by P2 and hence return 10 on a read to S. P4 on the other hand may see changes made by P1 and P2 in the order in which they are made and hence return 20 on a read to S. The processors P3 and P4 now have an incoherent view of the memory.
Therefore, in order to satisfy Transaction Serialization, and hence achieve Cache Coherence, the following condition along with the previous two mentioned in this section must be met:
- Writes to the same location must be sequenced. In other words, if location X received two different values A and B, in this order, from any two processors, the processors can never read location X as B and then read it as A. The location X must be seen with values A and B in that order.
3. CPU Cache一致性问题的解决方案
for bus-based machines,通常采用Snooping based protocols方案。for NUMA machines using a scalable switch,通常采用Directory Based Solutions。
Snooping based protocols tend to be faster, if enough bandwidth is available, since all transactions are a request/response seen by all processors. The drawback is that snooping isn’t scalable. Every request must be broadcast to all nodes in a system, meaning that as the system gets larger, the size of the (logical or physical) bus and the bandwidth it provides must grow. Directories, on the other hand, tend to have longer latencies (with a 3 hop request/forward/respond) but use much less bandwidth since messages are point to point and not broadcast. For this reason, many of the larger systems (>64 processors) use this type of cache coherence.
3.1 Snooping based protocols
Snooping is a process where the individual caches monitor address lines for accesses to memory locations that they have cached.
Write propagation in snoopy protocols can be implemented by either of the following methods:
Write Invalidate
When a processor writes into x, all copies of it in other processors are invalidated. These processors have to read a valid copy either from memory, or from the processor that modified the variable.Write Broadcast
Instead of invalidating, why not broadcast the updated value to the other processors sharing that copy?
MSI、MESI等protocol是较为常见的Snooping based protocols。MESI Cache Coherence Protocol | Vasileios Trigonakis很好了阐述了MESI protocol。

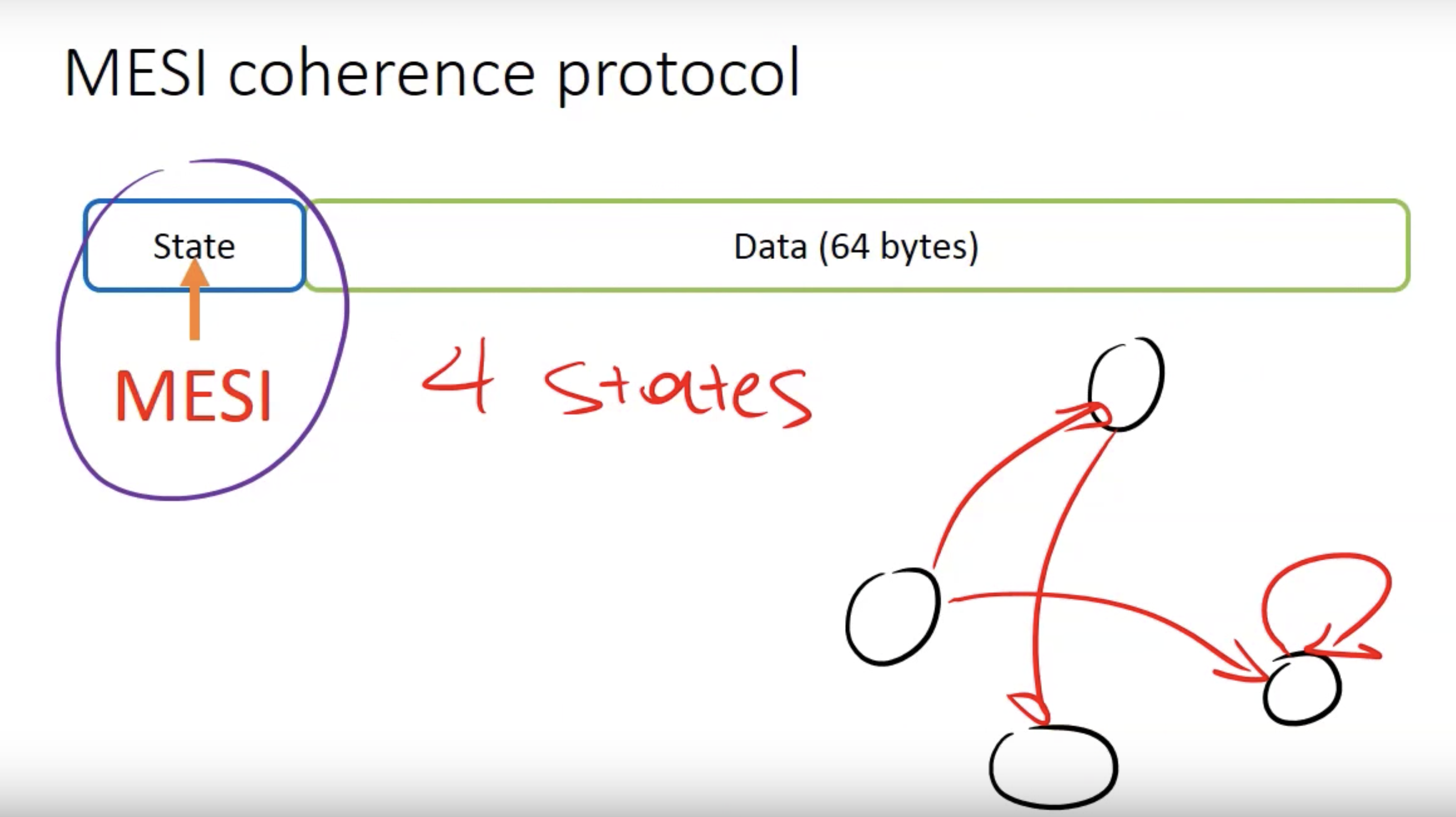
概要地讲:在MESI协议中,每个cache line有四种状态,当遇到不同事件时,会改变cache line的状态,由此构成了一个有限自动机。
3.2 Directory Based Solutions
In a directory-based system, the data being shared is placed in a common directory that maintains the coherence between caches.
Directory Entry与Directory Example给出了Directory的具体例子。
参考资料: