Introduction to GPUDirect RDMA
阅读了浅析GPU通信技术(下)-GPUDirect RDMA 一文,收获颇丰,故转载到博客中。
1. 背景
当前深度学习模型越来越复杂,计算数据量暴增,对于大规模深度学习训练任务,单机已经无法满足计算要求,多机多卡的分布式训练成为了必要的需求,这个时候多机间的通信成为了分布式训练性能的重要指标。
本篇文章我们就来谈谈GPUDirect RDMA技术,这是用于加速多机间GPU通信的技术。
2. RDMA介绍
我们先来看看RDMA技术是什么?RDMA即Remote DMA,是Remote Direct Memory Access的英文缩写。
2.1 DMA原理
在介绍RDMA之前,我们先来复习下DMA技术。
我们知道DMA(直接内存访问)技术是Offload CPU负载的一项重要技术。DMA的引入,使得原来设备内存与系统内存的数据交换必须要CPU参与,变为交给DMA控制来进行数据传输。
直接内存访问(DMA)方式,是一种完全由硬件执行I/O交换的工作方式。在这种方式中, DMA控制器从CPU完全接管对总线的控制,数据交换不经过CPU,而直接在内存和IO设备之间进行。DMA工作时,由DMA 控制器向内存发出地址和控制信号,进行地址修改,对传送字的个数计数,并且以中断方式向CPU 报告传送操作的结束。
使用DMA方式的目的是减少大批量数据传输时CPU 的开销。采用专用DMA控制器(DMAC) 生成访存地址并控制访存过程。优点有操作均由硬件电路实现,传输速度快;CPU 基本不干预,仅在初始化和结束时参与,CPU与外设并行工作,效率高。
2.2 RMDA原理
RDMA则是在计算机之间网络数据传输时Offload CPU负载的高吞吐、低延时通信技术。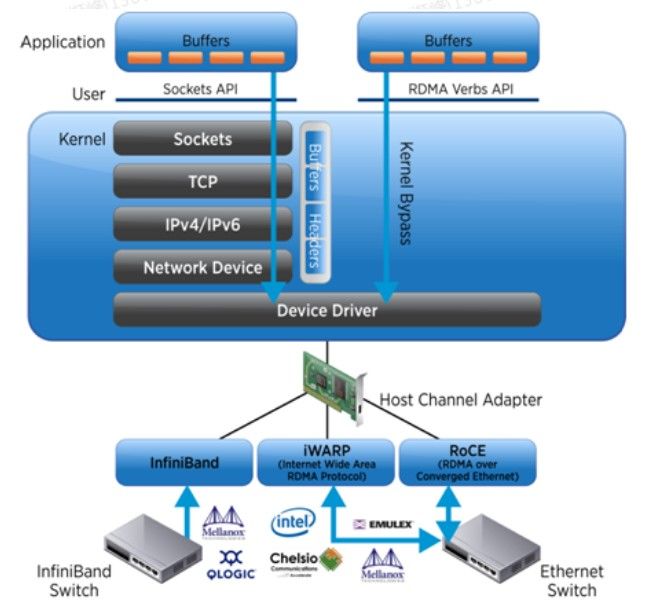
如上图所示,传统的TCP/IP协议,应用程序需要要经过多层复杂的协议栈解析,才能获取到网卡中的数据包,而使用RDMA协议,应用程序可以直接旁路内核获取到网卡中的数据包。
RDMA可以简单理解为利用相关的硬件和网络技术,服务器1的网卡可以直接读写服务器2的内存,最终达到高带宽、低延迟和低资源利用率的效果。如下图所示,应用程序不需要参与数据传输过程,只需要指定内存读写地址,开启传输并等待传输完成即可。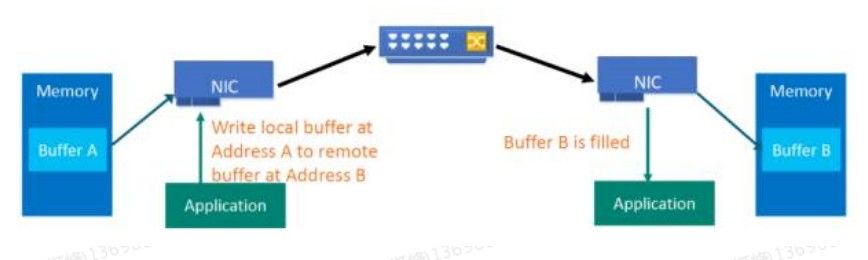
在实现上,RDMA实际上是一种智能网卡与软件架构充分优化的远端内存直接高速访问技术,通过在网卡上将RDMA协议固化于硬件,以及支持零复制网络技术和内核内存旁路技术这两种途径来达到其高性能的远程直接数据存取的目标。
- 零复制:零复制网络技术使网卡可以直接与应用内存相互传输数据,从而消除了在应用内存与内核之间复制数据的需要。因此,传输延迟会显著减小。
- 内核旁路:内核协议栈旁路技术使应用程序无需执行内核内存调用就可向网卡发送命令。在不需要任何内核内存参与的条件下,RDMA请求从用户空间发送到本地网卡并通过网络发送给远程网卡,这就减少了在处理网络传输流时内核内存空间与用户空间之间环境切换的次数。
在具体的远程内存读写中,RDMA操作用于读写操作的远程虚拟内存地址包含在RDMA消息中传送,远程应用程序要做的只是在其本地网卡中注册相应的内存缓冲区。远程节点的CPU除在连接建立、注册调用等之外,在整个RDMA数据传输过程中并不提供服务,因此没有带来任何负载。
2.3 RDMA实现
如下图RMDA软件栈所示,目前RDMA的实现方式主要分为InfiniBand和Ethernet两种传输网络。而在以太网上,又可以根据与以太网融合的协议栈的差异分为iWARP和RoCE(包括RoCEv1和RoCEv2)。
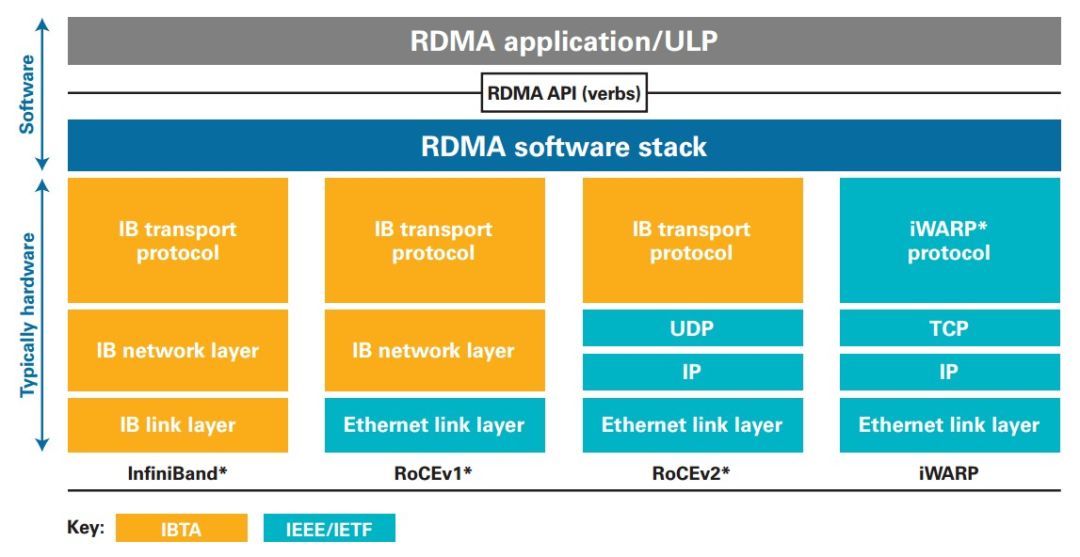
其中,InfiniBand是最早实现RDMA的网络协议,被广泛应用到高性能计算中。但是InfiniBand和传统TCP/IP网络的差别非常大,需要专用的硬件设备,承担昂贵的价格。相比之下RoCE和iWARP的硬件成本则要低的多。
3. GPUDirect RDMA介绍
3.1 原理
有了前文RDMA的介绍,从下图我们可以很容易明白,所谓GPUDirect RDMA,就是计算机1的GPU可以直接访问计算机2的GPU内存。而在没有这项技术之前,GPU需要先将数据从GPU内存搬移到系统内存,然后再利用RDMA传输到计算机2,计算机2的GPU还要做一次数据从系统内存到GPU内存的搬移动作。GPUDirect RDMA技术进一步减少了GPU通信的数据复制次数,进一步降低了通信延迟。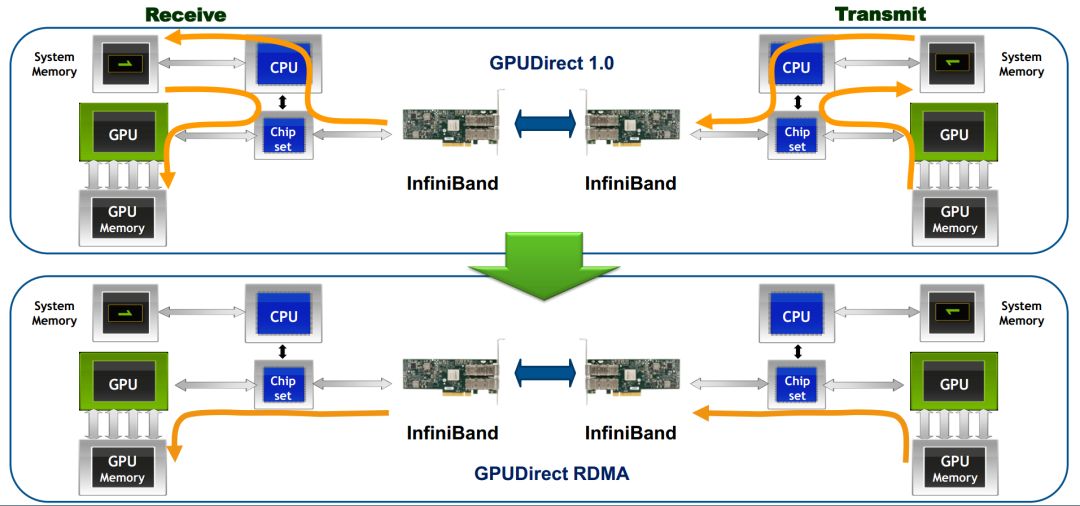
3.2 使用
需要注意的是,要想使用GPUDirect RDMA,需要保证GPU卡和RDMA网卡在同一个ROOT COMPLEX下,如下图所示: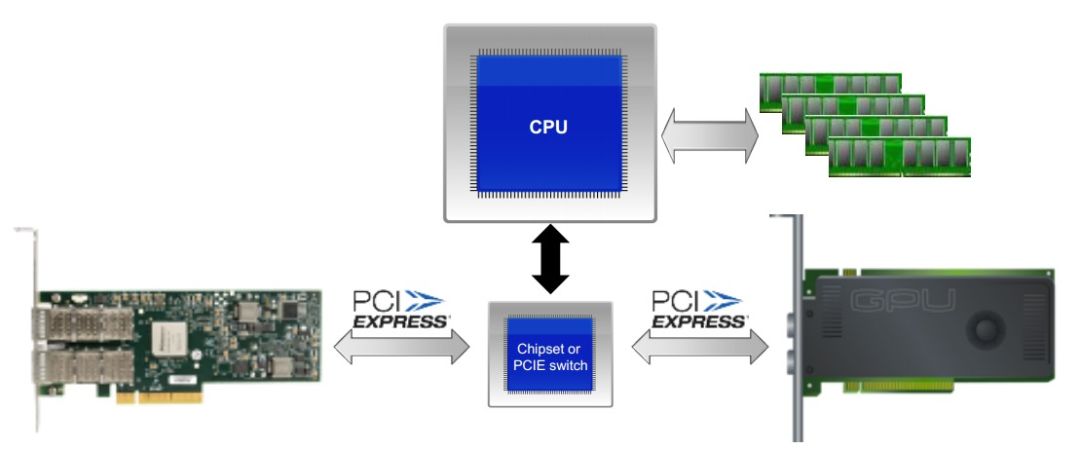
3.3 性能
Mellanox网卡已经提供了GPUDirect RDMA的支持(既支持InfiniBand传输,也支持RoCE传输)。
下图分别是使用OSU micro-benchmarks在Mellanox的InfiniBand网卡上测试的延时和带宽数据,可以看到使用GPUDirect RDMA技术后延时大大降低,带宽则大幅提升: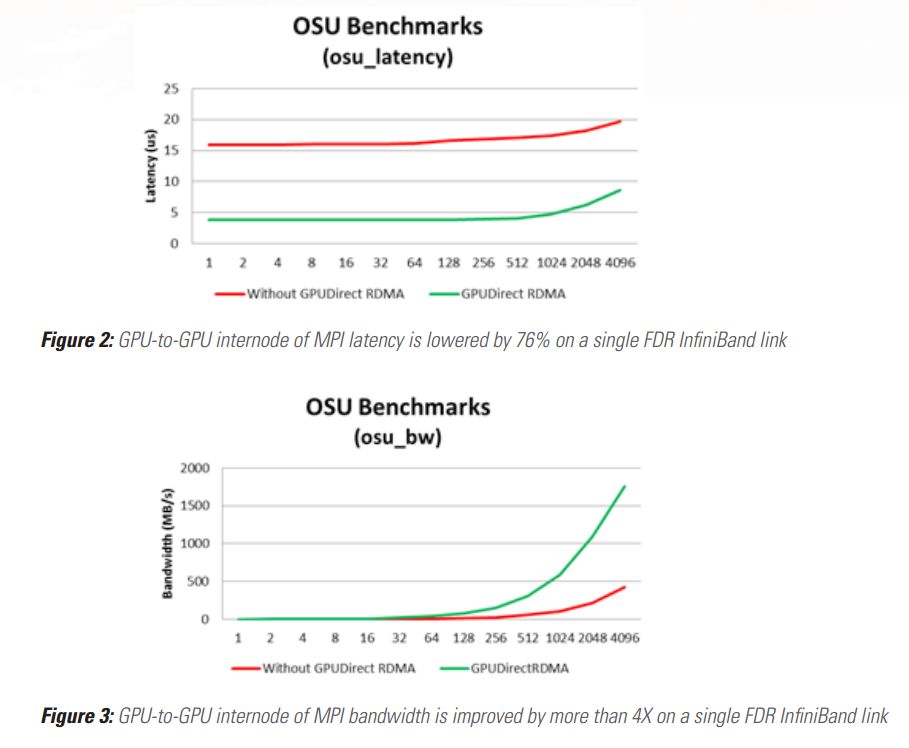
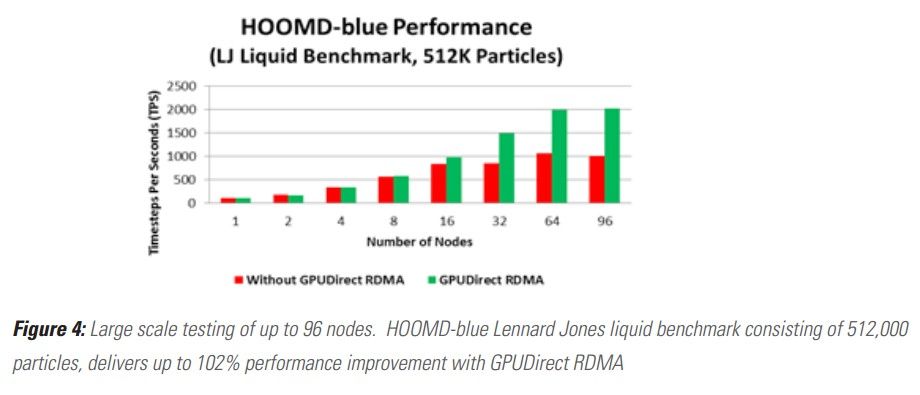
下图是一个实际的高性能计算应用的性能数据(使用HOOMD做粒子动态仿真),可以看到随着节点增多,使用GPUDirect RDMA技术的集群的性能有明显提升,最多可以提升至2倍: