一致性DMA映射与流式DMA映射
本文内容主要转载自:smc的Cache和DMA一致性。mark下一致性DMA映射(Consistent DMA mappings)与流式DMA映射(Streaming DMA mappings)的相关内容。
1. Background
我们知道DMA可以帮我们在I/O和主存之间搬运数据,且不需要CPU参与。高速缓存是CPU和主存之间的数据交互的桥梁。而DMA如果和cache之间没有任何关系的话,可能会出现数据不一致。例如,CPU修改了部分数据依然躺在cache中(采用写回机制)。DMA需要将数据从内存搬运到设备I/O上,如果DMA获取的数据是从主存那里,那么就会得到旧的数据。导致程序的不正常运行。这里告诉我们,DMA通过总线获取数据时,应该先检查cache是否命中,如果命中的话,数据应该来自cache而不是主存。但是是否需要先检查cache呢?这取决于硬件设计。
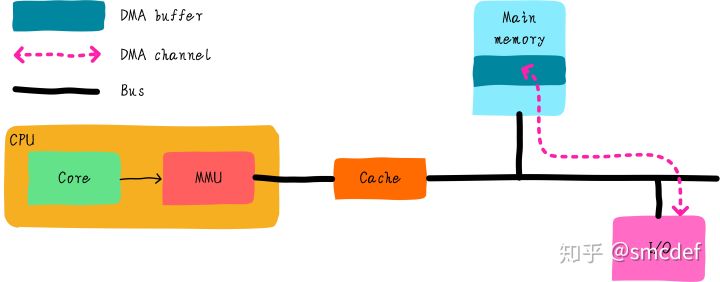
1.1 Terms
cache hit与write hit的定义:
2. 总线监视技术
什么是总线监视技术呢?其实就是为了解决以上问题提出的技术,cache控制器会监视总线上的每一条内存访问,然后检查是否命中。根据命中情况做出下一步操作。总线监视对于软件来说是透明的,软件不需要任何干涉即可避免不一致问题。但是,并不是所有的硬件都支持总线监视(x86_64硬件保证了DMA一致性),同时操作系统应该兼容不同的硬件。因此在不支持总线监视的情况下,我们在软件上如何避免问题呢?
主要有两种方法:
- 一致性DMA映射
- 流式DMA映射
3. 一致性DMA映射
当使用DMA时,需要在内存中申请一段内存当做buffer。为了避免cache的影响,可以将这段内存映射nocache,即不使用cache。映射的最小单位是4KB,因此在内存映射上至少4KB是nocahe的。这种方法简单实用,但是缺点也很明显:如果只是偶尔使用DMA,大部分都是使用数据的话,会由于nocache导致性能损失。这也是Linux系统中dma_alloc_coherent()接口的实现方法。
4. 流式DMA映射
为了充分使用cache带来的好处。内存映射依然采用cache的方式。但是需要格外小心。根据DMA传输方向的不同,采取不同的措施。
- 如果DMA负责从I/O读取数据到内存(DMA Buffer)中,那么在DMA传输之前,可以invalid DMA Buffer地址范围的高速缓存。在DMA传输完成后,程序读取数据不会由于cache hit导致读取过时的数据。
- 如果DMA负责把内存(DMA Buffer)数据发送到I/O设备,那么在DMA传输之前,可以clean DMA Buffer地址范围的高速缓存,clean的作用是写回cache中修改的数据。在DMA传输时,不会把主存中的过时数据发送到I/O设备。
注意,在DMA传输没有完成期间CPU不要访问DMA Buffer。例如以上的第一种情况中,如果DMA传输期间CPU访问DMA Buffer,当DMA传输完成时。CPU读取的DMA Buffer由于cache hit导致取法获取最终的数据。同样,第二情况下,在DMA传输期间,如果CPU试图修改DMA Buffer,如果cache采用的是写回机制,那么最终写到I/O设备的数据依然是之前的旧数据。所以,这种使用方法编程开发人员应该格外小心。这也是Linux系统中流式DMA映射dma_map_single()接口的实现方法。
4.1 DMA Buffer cacheline对齐要求
假设我们有2个全局变量temp和buffer,buffer用作DMA缓存。初始值temp为5。temp和buffer变量毫不相关。可能buffer是当前DMA操作进程使用的变量,temp是另外一个无关进程使用的全局变量。1
2int temp = 5;
char buffer[64] = { 0 };
假设,cacheline大小是64字节。那么temp变量和buffer位于同一个cacheline,buffer横跨两个cacheline。

假设现在想要启动DMA从外设读取数据到buffer中。我们进行如下操作:
- 按照上一节的理论,我们先invalid buffer对应的2行cacheline。
- 启动DMA传输。
- 当DMA传输到buff[3]时,程序改写temp的值为6。temp的值和buffer[0]-buffer[59]的值会被缓存到cache中,并且标记dirty bit。
- DMA传输还在继续,当传输到buff[50]的时候,其他程序可能读取数据导致temp变量所在的cacheline需要替换,由于cacheline是dirty的。所以cacheline的数据需要写回。此时,将temp数据写回,顺便也会将buffer[0]-buffer[59]的值写回。
在第4步中,就出现了问题。由于写回导致DMA传输的部分数据(buff[3]-buffer[49])被改写(改写成了没有DMA传输前的值)。这不是我们想要的结果。因此,为了避免出现这种情况。我们应该保证DMA Buffer不会跟其他数据共享cacheline。所以我们要求DMA Buffer首地址必须cacheline对齐,并且buffer的大小也cacheline对齐。这样就不会跟其他数据共享cacheline。也就不会出现这样的问题。
5. 总结
x86_64硬件保证了DMA一致性,无需考虑一致性DMA映射与流式DMA映射。
流式DMA映射根据数据方向对cache进行”flush/invalid”,既保证了数据一致性,也避免了完全关闭cache带来的性能影响。既然如此,为什么不抛弃一致性DMA映射,全面拥抱“更强大”的流式DMA映射呢?
考虑如下情况:当CPU和DMA需要频繁的操作一块内存区域的时候,如果采用流式DMA映射的话,需要频繁的”cache flush/invalid”操作(没有cache hit或者write hit的话,cache存在的意义就不大了),而刷cache是比较耗时的,就会导致开销比较大。这个时候,更适合采用一致性DMA映射。
From Using IOMMU for DMA Protection in UEFI Firmware:
The x86 architecture can guarantee the DMA and the cache are consistent. An I/O agent can perform the direct memory access (DMA) to write-back memory and the cache protocol maintains cache coherency.
From A Primer on Memory Consistency and Cache Coherence:
It is straightforward to provide coherent DMA by adding a coherent cache to the DMA controller, and thus having DMA participate in the coherence protocol. In such a model, a DMA controller is indistinguishable from a dedicated core, guaranteeing that DMA reads will always find the most recent version of a block and DMA writes will invalidate all stale copies.
参考资料: