(转)用户态GPU池化技术
本文转载自: 用户态GPU池化技术。主要mark下内核态虚拟化和用户态虚拟化两类方案。
1. 概述
目前有若干种软件技术方案能实现GPU虚拟化,这些方案可以分为内核态虚拟化和用户态虚拟化两类。本文主要论述这两种方案的差异。
2. 内核态与用户态解析
以英伟达的GPU为例,应用到硬件从上至下分为用户态、内核态、GPU硬件三个层次(见下图:CUDA软件栈)。
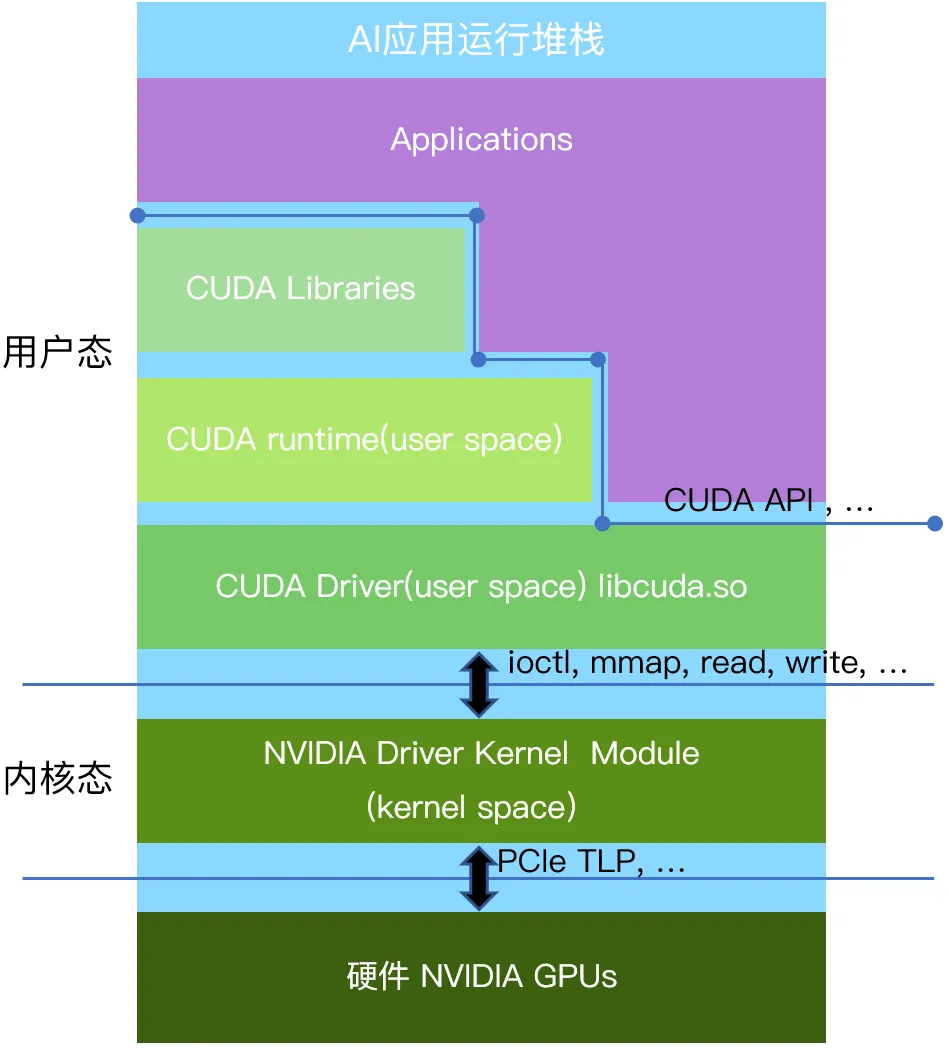
2.1 用户态层
用户态是应用程序运行的环境。各种使用英伟达GPU的应用程序,比如人工智能计算类的应用,2D/3D图形渲染类的应用,都运行在用户态。为了便利编程以及安全因素,英伟达提供了用户态的运行库CUDA(Compute Unified Device Architecture)作为GPU并行计算的编程接口(类似的接口也包括由社区共同制订的OpenGL、Vulkan接口等),应用程序可以使用CUDA API来编写并行计算任务,并通过调用CUDA API与GPU用户态驱动进行通信。GPU用户态驱动再通过ioctl、mmap、read、write接口直接和GPU的内核态驱动进行交互。
2.2 内核态层
该层主要运行的是GPU的内核态驱动程序,它与操作系统内核紧密集成,受到操作系统以及CPU硬件的特殊保护。内核态驱动可以执行特权指令,提供对硬件的访问和操作接口,并对GPU硬件进行底层控制。出于系统安全考虑,用户态的代码只能通过操作系统预先定义好的标准接口(Linux下有例如ioctl,mmap,read,write 等少量接口),调用内核态的代码。通过这些接口被调用的内核态代码一般是预先安装好的设备的内核态驱动。这样保证内核态和用户态的安全隔离,防止不安全的用户态代码破坏整个计算机系统。GPU的内核态驱动通过PCIe接口(也可能是其他硬件接口)以TLP报文的形式跟硬件进行通信。
特别的,包括英伟达在内的各类AI芯片产品的内核态和用户态之间的接口定义并不包含在例如CUDA、OpenGL、Vulkan等协议标准里面,他们也未曾向行业公开这一层的接口定义。因此各类行业应用也不会基于这一层的接口进行编程。
3. 两种虚拟化技术难度解析
从技术可能性的角度来看,用户态与内核态各有相应的接口可以实现GPU虚拟化或者GPU池化:用户态的CUDA、OpenGL、Vulkan等应用运行时接口;内核态暴露的 ioctl、read、write等设备驱动接口。
3.1 用户态虚拟化
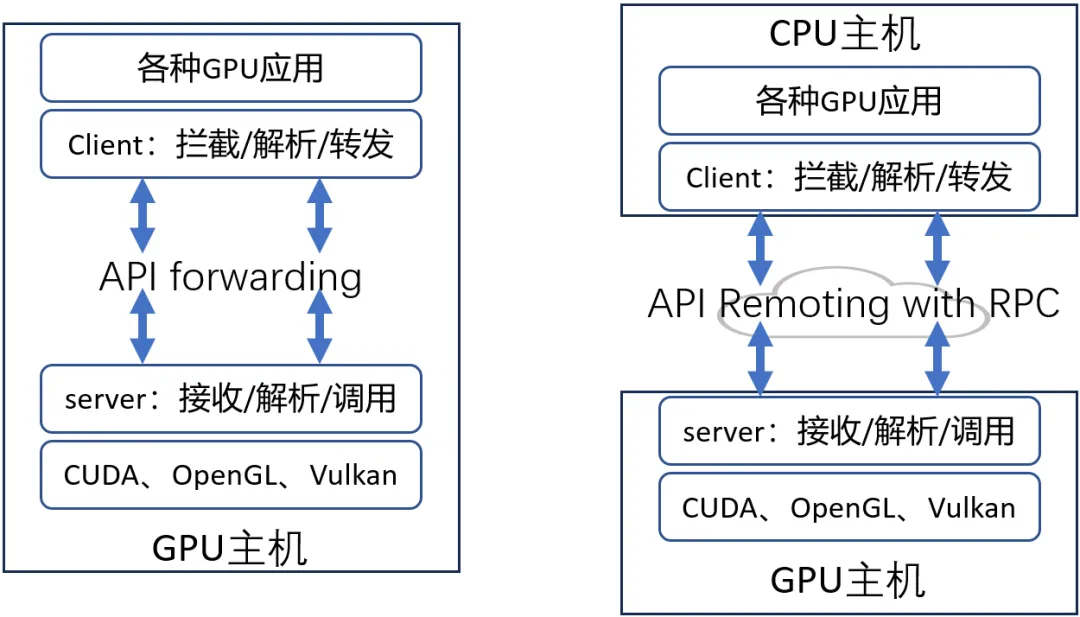
利用CUDA、OpenGL、Vulkan等标准接口,对API进行拦截和转发,对被拦截的函数进行解析,然后调用硬件厂商提供的用户态库中的相应函数(见上图)。拦截CUDA等用户态接口不需要在OS内核层进行设备文件的插入,因为这些接口的使用方式是操作系统在运行可执行文件的时候(例如Linux下的elf二进制),由操作系统的加载器自动在系统中按照固定的规则来寻找其依赖的外部接口,学术名称做符号(symbol)。那么根据操作系统寻找依赖的规则,很容易可以通过替换symbol的来源,使得当可执行文件发生例如CUDA接口调用的时候,调用的不是英伟达的闭源用户态软件提供的接口,而是一个经过修改后的同名接口,从而拦截到例如CUDA接口的调用。
经过API拦截之后,用户态虚拟化方案还可以利用RPC的方式进行远程API Remoting(见上图),即CPU主机可以通过网络调用GPU主机的GPU,实现GPU的远程调用。如此一来,多个GPU服务器可以组成资源池,供多个AI业务任意调用,达到实现GPU池化的目的。用户态虚拟化是一种软件的实现方案。目前业内已经成型的产品有:趋动科技的OrionX GPU池化产品,VMware的Bitfusion产品。这类技术方案拥有几个优点:
- CUDA、OpenGL、Vulkan等接口都是公开的标准化接口,具有开放性和接口稳定性。所以基于这些接口的实现方案具有很好的兼容性和可持续性。
- 因为该方案运行在用户态,因此可以规避内核态代码过于复杂容易引入安全问题的工程实践,可以在用户态通过复杂的网络协议栈和操作系统支持来实现及优化远程GPU的能力,从而高效率地支持GPU池化。
- 由于该方案工作在用户态,从部署形态上对用户环境的侵入性最小,也最安全,即使发生故障也可以迅速被操作系统隔离,而通过一些软件工程的设计可以有很强的自恢复能力。
当然,这类方案也有缺点:相比于内核态接口,用户态API接口支持更复杂的参数和功能,因此用户态API接口的数量比内核态接口的数量要高几个数量级。这导致在用户态层实现GPU虚拟化和GPU池化的研发工作量要比在内核态实现要大得多。
3.2 内核态虚拟化
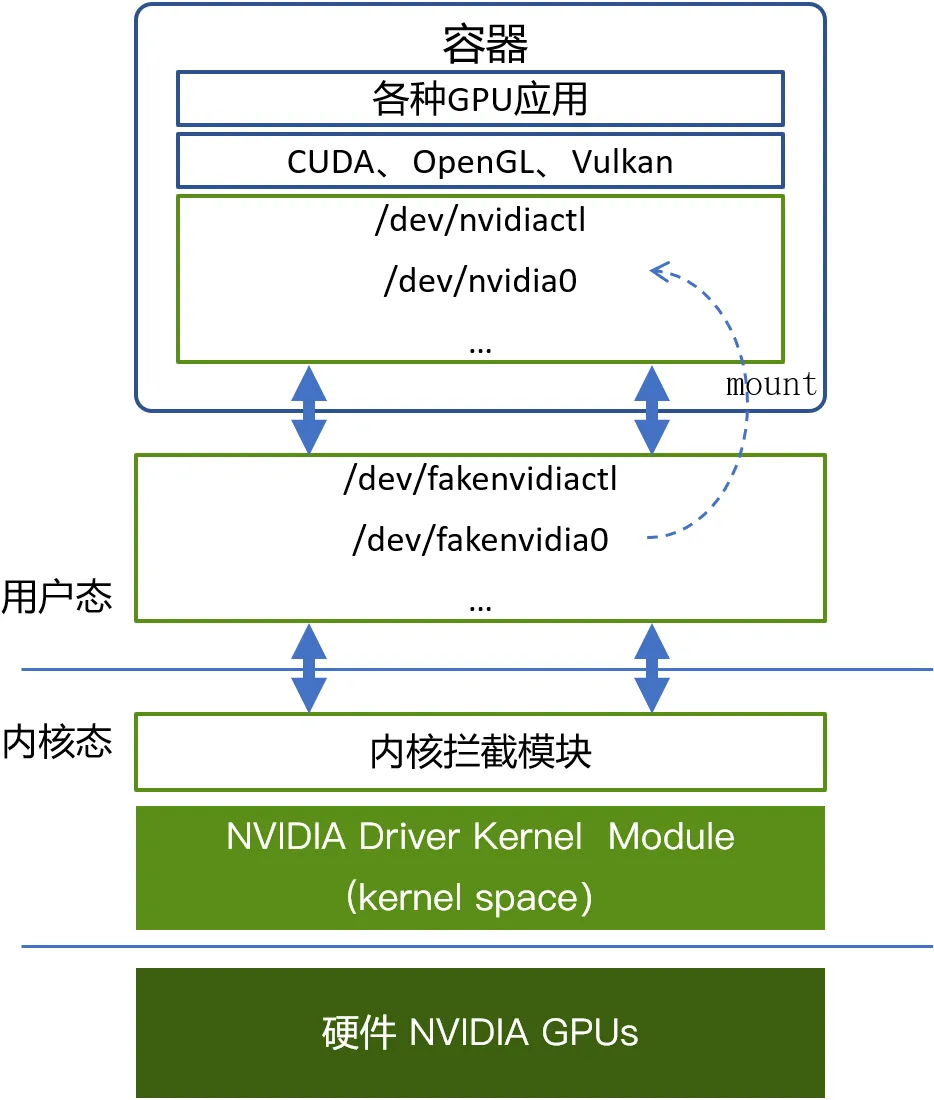
跟上述用户态拦截API类似的,第三方厂商所做的内核态虚拟化方案通过拦截ioctl、mmap、read、write等这类内核态与用户态之间的接口来实现GPU虚拟化。这类方案的关键点在于需要在操作系统内核里面增加一个内核拦截模块,并且在操作系统上创建一些设备文件来模拟正常的GPU设备文件。例如,英伟达GPU在Linux上的设备文件有/dev/nvidiactl、 /dev/nvidia0等多个文件。因此,在使用虚拟化的GPU时,把虚拟化出来的设备文件mount到业务容器内部,同时通过挂载重命名的机制伪装成英伟达的同名设备文件名,让应用程序访问。这样在容器内部的应用程序通过CUDA去访问设备文件的时候,仍然会去打开例如/dev/nvidiactl 和 /dev/nvidia0这样的设备文件,该访问就会被转发到模拟的设备文件,并向内核态发送例如ioctl这样的接口调用,进而被内核拦截模块截获并进行解析。目前国内的qGPU和cGPU方案都是工作在这一层。这类技术方案的优点是:
- 有较好的灵活性,而且不依赖GPU硬件,可以在数据中心级和消费级的GPU上使用。
- 在GPU共享的同时,具备不错的隔离能力。
- 由于只支持运行在容器环境中,研发工作量相比用户态方案要小得多。
这类方案由于工作在内核态,缺点也是显而易见的:
- 需要在内核态层插入文件,对系统的侵入性大,容易引入安全隐患。
- 由于英伟达GPU内核态驱动的ioctl等接口以及用户态模块都是闭源的,接口也不开放,因此只有英伟达自己可以在这层支持所有的GPU虚拟化能力,其他第三方厂商只能通过一定程度的逆向工程来实现对这些接口的解析。这种行为存在着极大的法律风险和不确定性,可持续性远低于用户态方案。
- 第三方厂商由于缺少完整的接口细节,目前只能通过接口“规避”的方式来支持。所谓“规避”,简单来说就是只解析必要的少数几个接口,其他的不劫持直接放过。为了方便实现“规避”效果,这类方案目前都只能支持基于容器虚拟化的环境(因为很容易实现),无法支持非容器化环境以及KVM虚拟化环境,更加无法跨越操作系统支持GPU池化最核心的远程GPU调用,因此这类方案不是完整的GPU池化方案。
3.3 接口解析
上述两种虚拟化方案在经过接口拦截之后,就可以在当前的接口调用中被激活,接下来就是对该接口进行解析。不管是 ioctl 接口还是 CUDA接口,从计算机设计上,都可以表达为interface_name(paramerA, parameterB, …)这样的形式。也就是接口名称,接口参数(返回值也是一种参数形式)。而不管基于哪一层接口的拦截,这里的解析又分为两种:
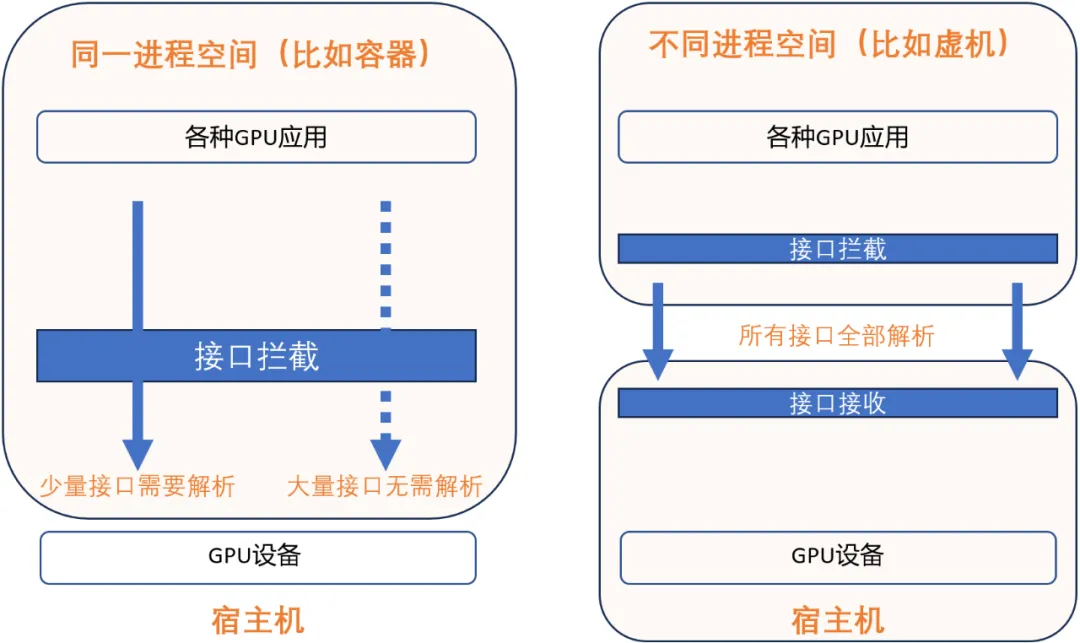
同一个进程空间的接口解析(见上图):在现代操作系统中,不管在用户态还是内核态,代码都执行在由CPU硬件 + 操作系统维护的一个进程空间里面,在一个进程空间里面有统一的进程上下文(context),并且所有的资源在进程空间内都是共享的,视图是统一的,包括访存地址空间(address space),也包括GPU设备上的资源。这个现代操作系统的设计可以为同一个进程空间的接口解析带来极大的便利。因为对于一个接口interface_name(paramerA, parameterB, …),即使存在不公开含义的参数,例如parameterB是不公开的,但是利用一个进程空间内所有的资源都是共享且视图统一的这个特点,只要确定该部分内容不需要被GPU虚拟化模拟执行所需要,那么虚拟化软件可以不需要对其进行解析,在截获之后,直接透传给英伟达自己的闭源模块就可以。实际上,只有少量接口,少量参数会被需要在一个进程内被解析并且模拟执行,因此选择这个技术路线可以“规避”掉绝大多数接口、参数的解析工作。具体以针对英伟达的GPU为例,只有非常少的接口、参数需要被真正解析并模拟执行。一些产品之所以能在非公开的内核接口层实现GPU虚拟化,是利用了同一个操作系统的特点,基于少量接口信息,来达到GPU虚拟化的目的。但是这样的技术路线也有一个非常明显的限制,就是只能在同一个进程空间内进行接口的拦截、解析和执行。因此这种技术路线从原理上就无法支持跨OS内核的KVM虚拟化,更无法跨越物理节点做到远程调用GPU。
不同进程空间的接口解析(见上图):当GPU应用所在的操作系统和管理物理GPU所在的操作系统是两个不同的操作系统的时候,要达到GPU虚拟化、GPU池化的目的,就需要跨进程对选定的GPU接口层进行跨进程的接口解析。典型的场景如 KVM虚拟机,还有跨物理节点调用GPU。由于应用程序和GPU管理软件栈(例如GPU驱动)已经不在一个操作系统的管理下,因此资源就不再是共享的了,视图也不再是统一的了。例如,同样的一个虚拟地址(virtual address)在不同的进程空间代表的很可能是不一样的内容。所以对于所有接口interface_name(paramerA, parameterB, …),都要进行完善的解析、处理,并通过例如网络的方式跨越操作系统进行传送。以英伟达的 CUDA 为例有数万个接口,需要对每一个接口都进行跨进程空间的接口解析,然后进行行为模拟。因此,在不公开的接口层进行跨进程空间的接口解析,原理上是行不通的。
经过接口解析之后,则需要向GPU应用提供一个模拟的GPU执行环境,这个模拟的动作是由GPU虚拟化和GPU池化的软件来完成的。不同软件提供的模拟的能力是有差异的,但是其基础的能力,都是要保持对上层应用的透明性,使得应用不需要改动实现,不需要重新编译。
3.4 总结
对于GPU虚拟化和资源池化,由于在接口层的的选择上有两个分支,在接口解析上也有两个分支,所以排列组合起来有4种可能,下面对4种方式做一个对比。
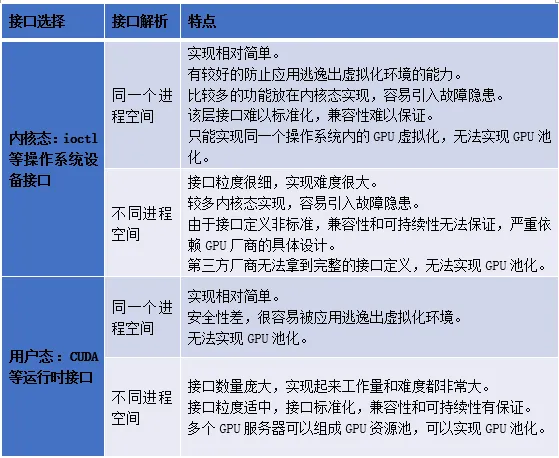
通过对比这4种可能的方式,我们做个总结:
- 内核态方案仅能在同一个进程空间工作,无法跨机,因此无法实现GPU池化。
- 内核态方案要在同一个进程空间实现GPU虚拟化是相对简单的。
- 只有用户态方案可以实现跨不同进程空间工作,可以跨机,因此可以实现GPU池化。
- 用户态方案要想跨不同进程空间实现GPU池化,有大量接口需要解析,难度与门槛很高。