Notes about network RFS and aRFS
本文将mark下network的RFS(Receive Flow Steering)和aRFS(Accelerated Receive Flow Steering)相关notes。
RFS
RSS/RPS很好地保证了数据包处理的负载均衡,可以将处理任务合理的分配到所有的 CPU 上。
但是,有时候我们还需要考虑其他的因素。比如,网卡收到了属于一个运行在 CPU0 上的进程的数据包,那么这些数据包被 CPU0 处理会比其他 CPU 处理更高效。
原因很简单直观,数据在 CPU 内传递比跨 CPU 传递要更节省时间。因此,我们希望数据包尽量能够被其所属的进程所在的CPU处理,至少能够被同属一个 NUMA域的CPU处理。
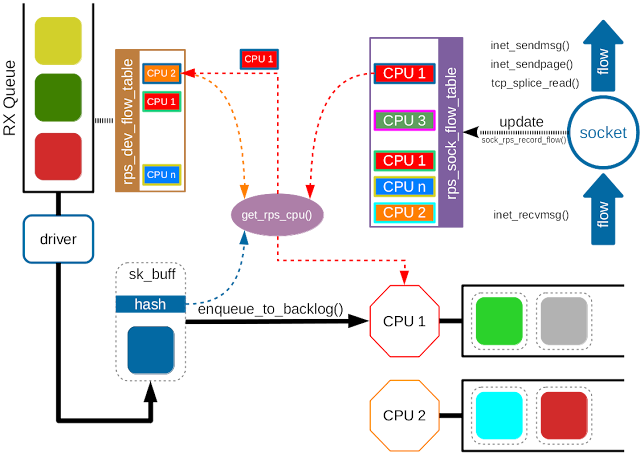
RFS 机制就是为了实现这一点。使用 hash 函数根据包头信息计算得到一个 hash 值,然后作为索引查表。RFS 所查找的匹配表(rps_sock_flow_table)中存储的是数据包所属进程所在的 CPU。1
2[hash value] : [CPU id]
...
如果能查找到有效的CPU,就将数据包入队到CPU对应的backlog队列中;如果查找不到,那么就直接按照 RPS 机制转发。
与 RPS 预先配置好的 CPU 列表不同,rps_sock_flow表是动态更新的。如果有数据包的收发操作,如 inet_recvmsg(), inet_sendmsg(), inet_sendpage(), tcp_splice_read() 等操作,则会插入新的值。类似的情况还发生在进程被调度到新的 CPU 的时候。这时候就需要更新匹配表中的值。如果原来的 CPU 队列上还有未处理完的数据包,那么就会发生乱序。
为了避免乱序,RFS 使用了另一个表 —— rps_dev_flow 表,每个网卡队列对应一个该表。该表的索引依旧是包头的 hash 值,每个表项对应两个字段:1) 现在的 CPU(也就是该数据包所属流已经把数据包放在其队列上等待其内核处理的 CPU)号。2) 当该流最后一个数据包到达后,该 CPU 的 backlog 队列的尾计数器值(用来判断原CPU 队列上有没有未处理完的包)。
当进程切换 CPU 时,先判断原 CPU 队列上有没有未处理完的包,如果有就不切换;如果没有,就切换。
aRFS
Accelerated RFS 之于 RFS 相当于 RSS 之于 RPS。Accelerated RFS 在硬件上就可以选择正确的队列,随后触发该数据包所属流所在的 CPU 的中断。由此可见,如果想要在硬件上实现队列选择,我们需要一个从流到硬件队列的对应关系。
aRFS允许网卡在选择队列时,直接将数据包放入应用程序所在CPU对应的队列。
- 维护规则: 内核自动维护socket五元组、socket应用程序所在的CPU和CPU对应的接收队列的映射关系
- socket五元组 -> CPU(从流到 CPU 的映射关系,记录在
rps_dev_flow表中) - CPU -> RX queue(CPU 和硬件队列的关系,通过
/proc/irq/<irq_num>/smp_affinity进行配置)
- socket五元组 -> CPU(从流到 CPU 的映射关系,记录在
- 下发规则: 内核根据上述映射关系,在用户态接收数据时,将五元组与CPU对应的规则下发到网卡
- 匹配规则: 网卡接收到的所有报文会根据aRFS规则进行匹配并转发到相应的接收队列
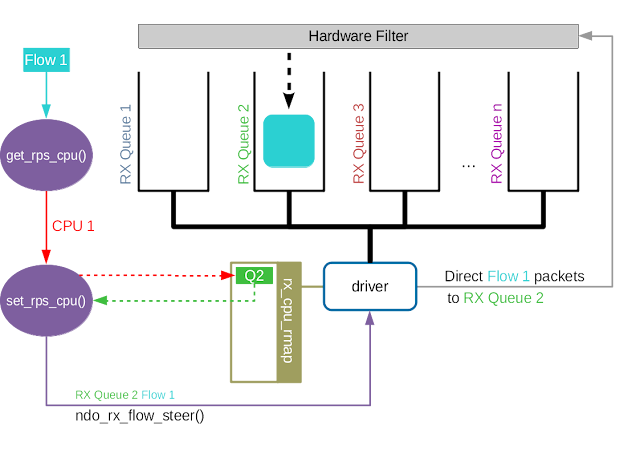
每当rps_dev_flow表中的条目被更新,网络协议栈就会调用驱动中的ndo_rx_flow_steer函数来更新流到硬件队列的对应关系。
Modern NICs support aRFS by (1) providing the OS with an API that allows it to associate networking flows with Rx queues, and by (2) steering incoming packets accordingly. When the OS migrates thread T away from core C, the OS updates the NIC regarding thread T ’s new queue using the aRFS API. The actual update is delayed until the original queue is drained from packets of socket file descriptor S(flow在old core上的排空), to avoid out-of-order receives.
总结
- 理解aRFS或许更为关键
- aRFS允许网卡在选择队列时,直接将数据包放入应用程序所在CPU对应的队列
参考资料: