Notes about IBGDA(InfiniBand GPUDirect Async)
本文将mark下IBGDA(InfiniBand GPUDirect Async)的相关notes。内容主要转载自浅析DeepSeek中提到的IBGDA。
Background
Additionally, we leverage the IBGDA (NVIDIA, 2022) technology to further minimize latency and enhance communication efficiency.
Without IBGDA
在使用了GPU Direct RDMA的GPU中,网卡是怎么和GPU配合,实现将GPU的HBM的数据发送到远端的呢?
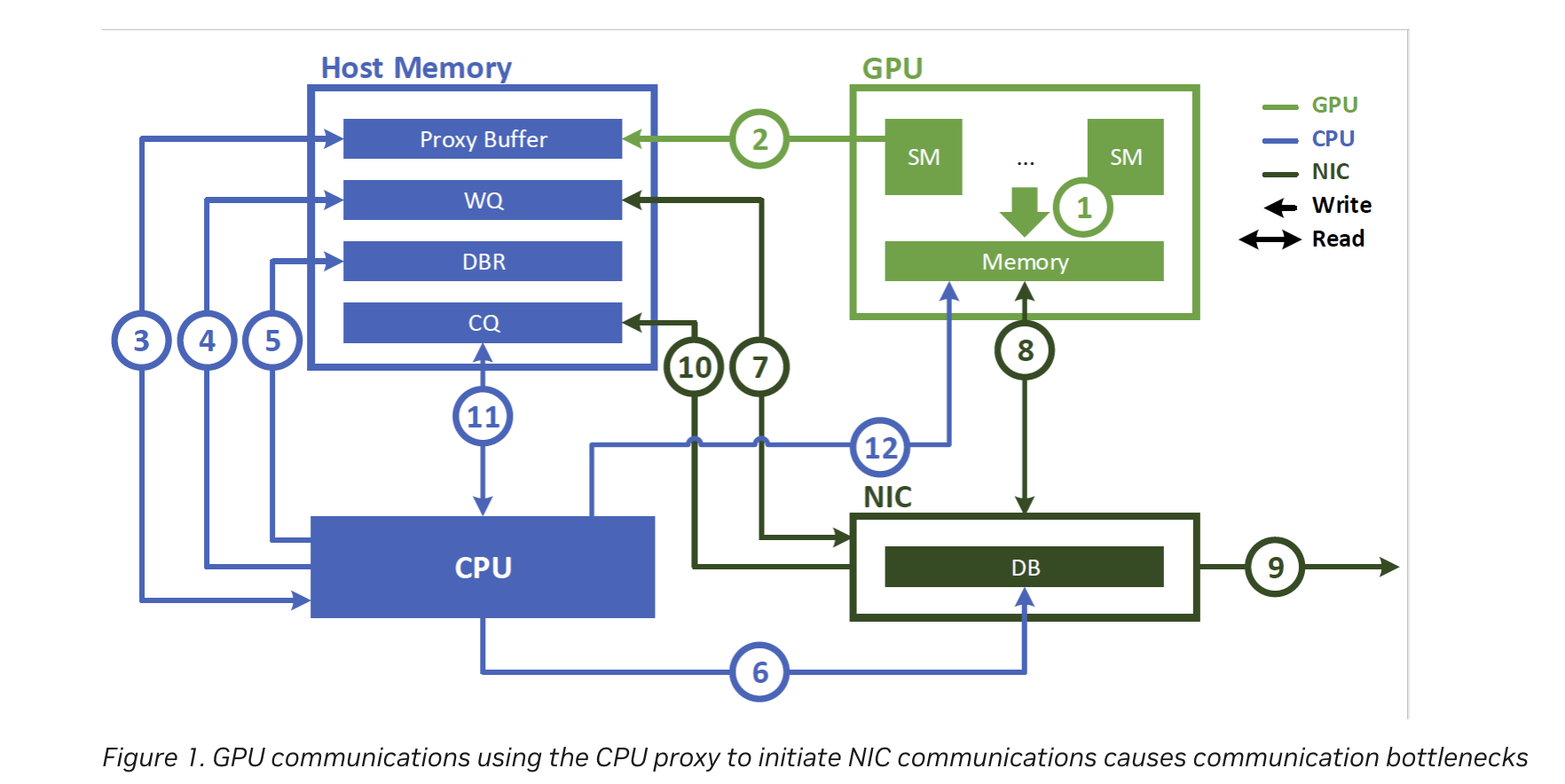
在引入InfiniBand GPUDirect Async(IBGDA)之前,是使用CPU上的代理线程来进行网络通信的。
此时流程是这样的:
- 应用程序启动一个CUDA kernel,在GPU内存中产生数据
- kernel function通过往CPU memory中的proxy buffer写入数据的方式,通知CPU要进行网络操作。我们将这个通知称为work descriptor, 它包含源地址、目标地址、数据大小及其他必要的网络信息
- CPU上的proxy thread读取worker descriptor
- CPU上的proxy thread发起相应的网络操作,将请求写入WQ
- CPU会更新host memory中的doorbell record (DBR) buffer。(This buffer is used in the recovery path in case the NIC drops the write to its doorbell. 就是用来记录doorbell的信息,万一硬件来不及及时响应doorbell并把它丢掉,你还能从DBR buffer中恢复doorbell)
- CPU通过写入NIC的 doorbell (DB)通知NIC。DB是NIC硬件中的一个寄存器
- NIC从WQ中读取work descriptor
- NIC使用GPUDirect RDMA直接从GPU内存搬运数据
- NIC将数据传输到远程节点
- NIC通过向主机内存中的CQ写入事件来指示网络操作已完成
- CPU轮询CQ以检测网络操作的完成
- CPU通知GPU操作已完成
可以发现,这个过程竟然需要GPU, CPU, NIC三方参与。CPU就像是一个中转站,那么显然它有一些缺点:
- proxy thread消耗了CPU cycles
- proxy thread成为瓶颈,导致在细粒度传输(小消息)时无法达到NIC的峰值吞吐。现代NIC每秒可以处理数亿个通信请求。GPU可以按照该速率生成请求,但CPU的处理速率低得多,造成了在细粒度通信时的瓶颈。
With IBGDA
优化的方法显而易见,能否绕过CPU,让GPU自己来和网卡做交换呢?IBGDA给出了这样的功能。
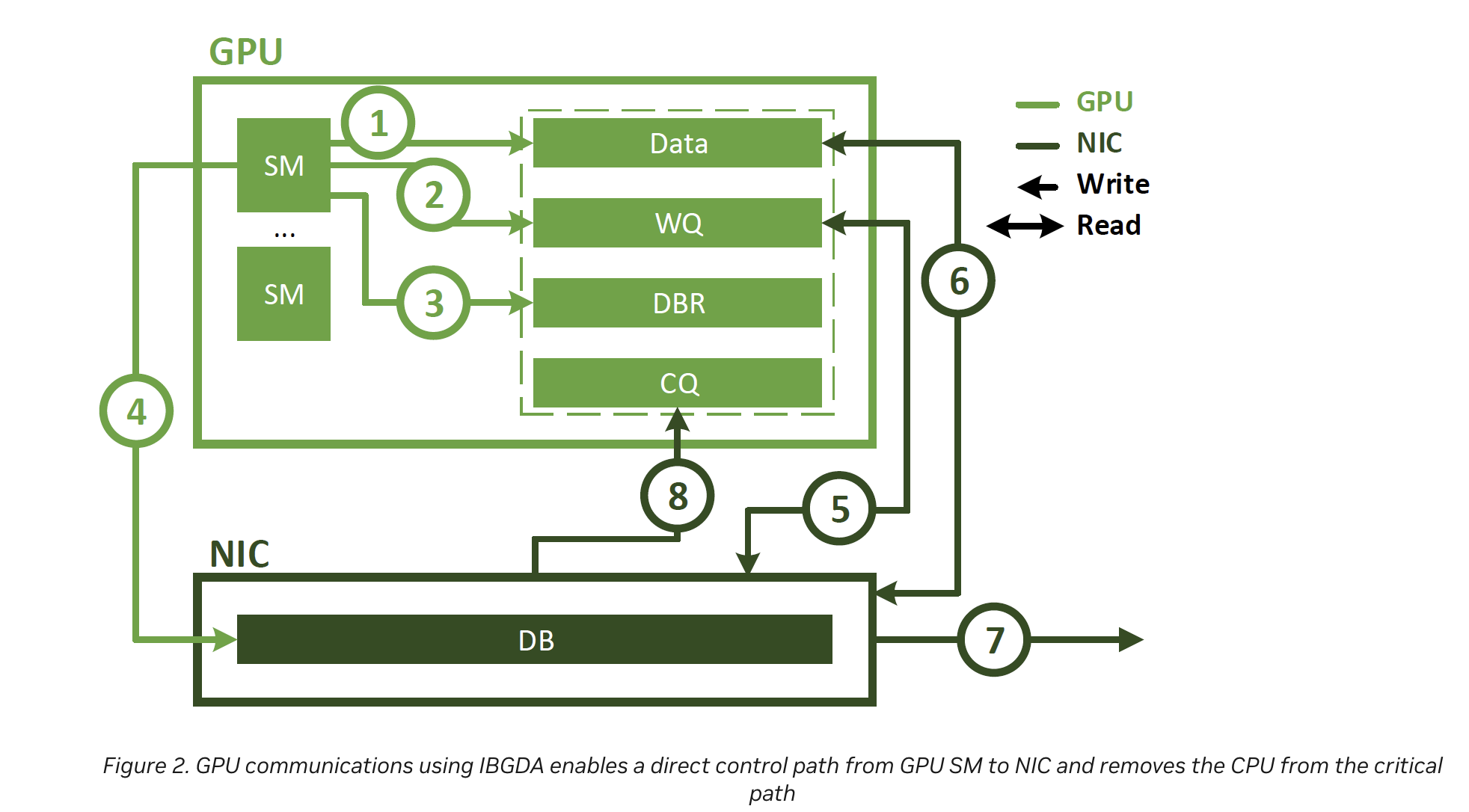
- CPU程序启动一个CUDA kernel function,在GPU内存中生成数据
- 使用SM创建一个NIC work descriptor,并将其直接写入WQ。与CPU proxy thread不同,该WQ区位于GPU内存中
- SM更新DBR buffer,它也位于GPU内存中
- SM通过写入NIC的DB寄存器通知NIC
- NIC使用GPUDirect RDMA从WQ读取工作描述符
- NIC使用GPUDirect RDMA读取GPU内存中的数据
- NIC将数据传输到远程节点
- NIC通过使用GPUDirect RDMA向CQ缓冲区写入事件,通知GPU网络操作已完成
可见,IBGDA消除了CPU在通信控制路径中的作用。在使用IBGDA时,GPU和NIC直接交换进行通信所需的信息。WQ和DBR buffer也被移到GPU内存中,以提高SM访问效率。
参考资料: