Notes about Intel Advanced Matrix Extensions (AMX)
本文将mark下Intel Advanced Matrix Extensions (AMX)的相关notes。
Overview
To significantly improve the throughput of the CPU for machine learning (ML) applications, Intel has integrated AMX, an on-chip matrix-multiplication(矩阵乘法) accelerator, along with Instruction Set Architecture (ISA) support, starting from the 4th generation Xeon CPUs (SPR), released in 2023.
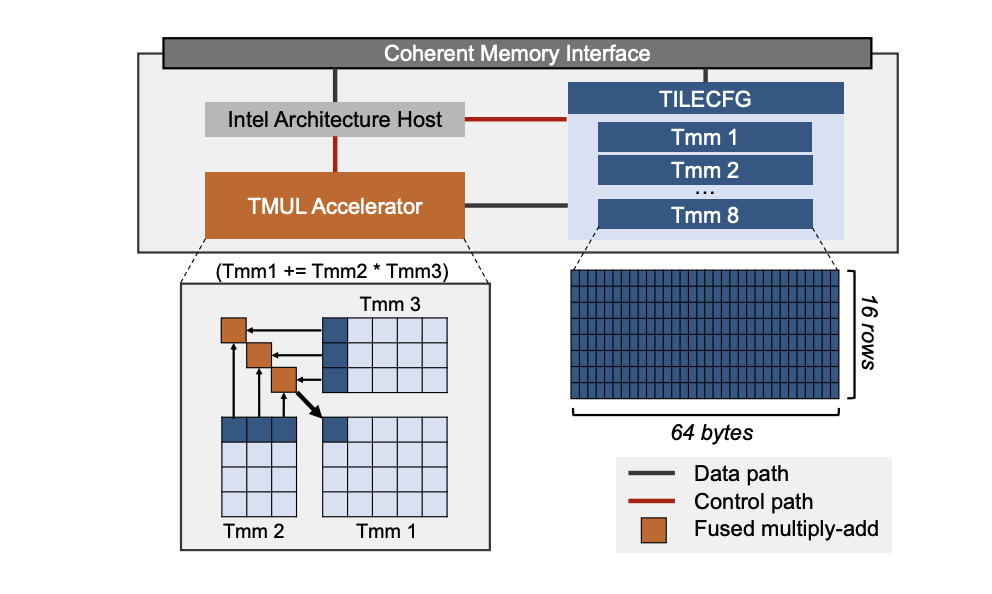
The above Figure depicts the accelerator architecture consisting of two core components: (1) a 2D array of registers (tiles) and (2) Tile matrix multiply unit (TMUL), which are designed to support INT8 and BF16 formats. The tiles store sub-arrays of matrices and the TMUL, a 2D array of multiply-add units, operate on these tiles. The 2D structure of TMUL delivers significantly higher operations/cycle through large tile-based matrix computation, which operates with greater parallelism than 1D compute engines such as AVX engines. The CPU dispatches AMX instructions, such as tile load/store and accelerator commands, to the multi-cycle AMX units. The accelerator’s memory accesses remain coherent with the CPU’s memory accesses.
How
AMX 通过其两个核心组件协同工作来加速矩阵运算:
- Tile:这是一组 8 个二维寄存器(TMM0-TMM7),每个大小为 1 KB,专门用于存储较大的数据块(矩阵)
- TMUL(Tile Matrix Multiply Unit,Tile矩阵乘法单元):这是一个专用的矩阵乘法加速引擎,直接与 Tile 寄存器连接,用于执行 AI 计算中至关重要的矩阵乘法运算
AMX 支持 BF16 和 INT8 两种数据类型。BF16 在保持足够精度的同时提高了计算效率,适用于训练和推理;INT8 则主要用于推理场景,以进一步追求速度和能效。
XSAVE的支持
Tile的状态分为两部分: TILECFG和TILEDATA


1 | // https://github.com/qemu/qemu/blob/master/target/i386/cpu.h |
总结
Intel AMX 是 Intel内置在其现代服务器 CPU 中的专用矩阵计算加速硬件,它通过专门的寄存器和执行单元,大幅提升了 CPU 执行 AI 训练和推理任务(尤其是矩阵乘法)的效率。对于希望利用现有服务器基础设施进行高效 AI 计算、同时控制成本和复杂性的企业来说,AMX 提供了一项值得关注的技术。
参考资料:
- Intel SDM vol1
- LIA: A Single-GPU LLM Inference Acceleration with Cooperative AMX-Enabled CPU-GPU Computation and CXL Offloading(ISCA’25)
- deepseek prompt:简要介绍下Intel的amx技术