Notes about NVIDIA TMA(Tensor Memory Access)
本文将mark下NVIDIA TMA(Tensor Memory Access)技术的相关notes。
Overview
在GPU中,数据存储在Global Memory(一般为HBM),计算单元(CUDA core/ Tensor core)位于SM中,数据需要搬运到SM内的Shared Memory(SMEM)中用于计算,计算后再搬回Global Memory中。
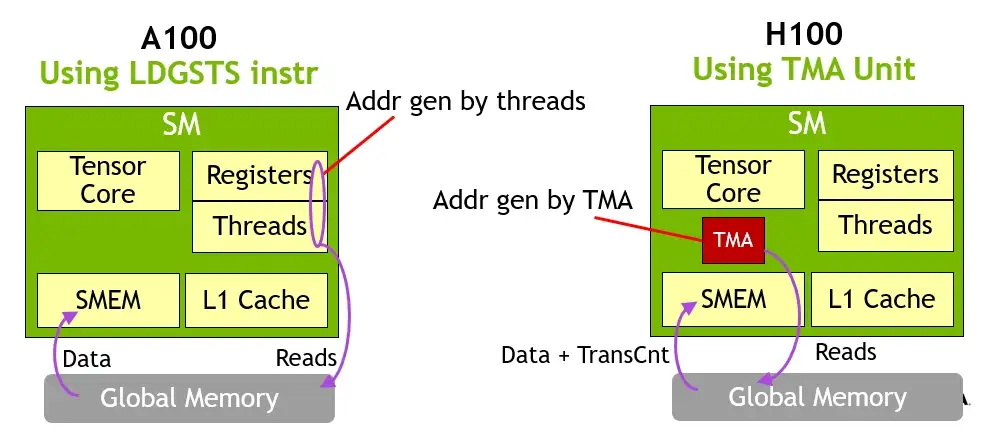
SM中的线程除了负责发起计算外,还要先负责搬运数据。线程需要承担地址计算、越界处理、同步管理等一系列任务。据调查,开发者90%的时间花费在编写数据访问的代码上,10%以上的性能损耗源于内存访问开销。
为了解决这一问题,英伟达在Hopper架构中引入了 Tensor Memory Accelerator(TMA),将数据访问的复杂性从软件层(线程)剥离,交由专用硬件(TMA)处理,实现数据搬运与计算解耦。
背景
在 A100(Ampere 架构)及更早的 GPU 中,线程块(thread block)需要通过 CUDA 线程显式地从全局内存(global memory)将数据加载到共享内存(shared memory),再供给 Tensor Core 使用。这个过程存在以下问题:
- 地址计算开销大:每个线程需手动计算多维张量(如矩阵分块)的内存地址
- 同步复杂:需协调多个 warp 协同完成数据搬运,并使用
__syncthreads()同步 - 带宽利用率受限:非最优的访存模式可能导致内存带宽未被充分利用
核心原理
TMA 是一个独立于 CUDA 核心的硬件单元,可由软件通过异步描述符(descriptor)+ 坐标(coordinate)的方式发起高维张量的内存拷贝操作。
Tensor Descriptor
开发者首先定义一个张量描述符,包含以下信息:
- 张量的形状(shape)
- 内存布局(layout,如行主序、列主序、分块布局等)
- 数据类型(如 FP16、BF16、INT8)
- 起始地址(base address)
该描述符一次性配置后,可被多次复用。
Copy by Coordinate
TMA 不使用传统的一维地址,而是通过逻辑坐标(如 (block_row, block_col))指定要拷贝的子张量(tile)。例如:1
2// 伪代码示意
tma_load(desc, shared_mem_ptr, coord = {tile_m, tile_n});
硬件根据描述符自动:
- 将逻辑坐标映射为物理地址
- 生成最优的内存访问模式(合并访问、对齐等)
- 执行从全局内存到共享内存(或反之)的 DMA 式传输
异步 & 零线程开销
- TMA 操作由专用硬件引擎执行,不占用SM中的 CUDA 核心资源
- CUDA 线程只需发出TMA指令(通过
cp.async.bulkPTX指令触发传输),即可继续执行其他计算,实现计算与数据搬运重叠 - 无需线程参与地址计算或数据搬移,显著降低软件开销
支持高维与非规则布局
TMA 原生支持最多 5 维张量,并能处理:
- 分块循环布局(swizzled/tiled layout)
- 填充(padding)
- 跨步(strides)
这使其特别适合 Transformer、卷积等复杂神经网络中的内存访问模式。
典型应用场景
- GEMM(通用矩阵乘):将 A、B 矩阵的分块自动加载到 shared memory,供 Tensor Core 使用
- Attention 机制:高效搬运 Q、K、V 的分块数据
- 大模型推理/训练:减少数据搬运瓶颈,提升计算吞吐
总结
TMA核心目标是优化张量运算中的数据搬运效率,特别是为 Tensor Core 提供高效、低开销的数据加载与存储能力。
TMA的技术本质是:将“基于地址的、线程驱动的”内存访问,转变为“基于张量语义的、硬件加速的”异步数据传输。
参考资料: