每周分享第37期
文章目录
CubeSandbox
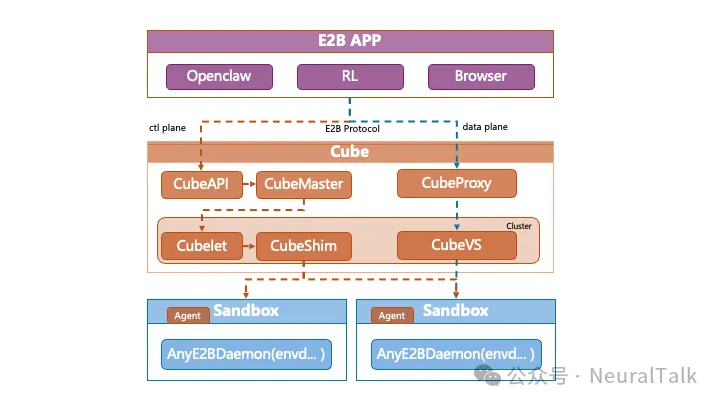
核心优势
- 极致冷启动: 基于资源池化预置和快照克隆技术,直接跳过耗时初始化流程。整个沙箱服务端到端冷启动一个可服务的沙箱时间平均 < 60ms
- 单机千例的高密部署: 基于 CoW 技术实现极致内存复用,用 Rust 重构底层极致裁剪,使得单实例内存开销低至 <5MB,轻松在一台机器上跑起数千个 Agent。
- 真正的内核级隔离: 告别不安全的 Docker 共享内核(Namespace)。每个 Agent 拥有独立的 Guest OS 内核,杜绝容器逃逸,放心运行任何大模型生成的未知代码。
- 零成本迁移(E2B 完美平替): 原生兼容 E2B SDK 接口规范。只需替换一个 URL 环境变量,无需业务代码改动就可切换到免费的 Cube Sandbox,并获得更好的性能体验。
- 网络安全: 基于 eBPF 的 CubeVS 在内核态实现严格的沙箱间网络隔离,支持细粒度出站流量过滤策略。
- 开箱即用: 可一键快速部署,同时支持单机部署和集群部署。
- 事件级快照回滚(coming soon): 百毫秒级的高频快照回滚能力,基于快照快速创建分叉探索环境
历史文档:
IPADS开源SkVM
上海交大IPADS开源SkVM:让Agent Skill”一次编写,处处高效运行”
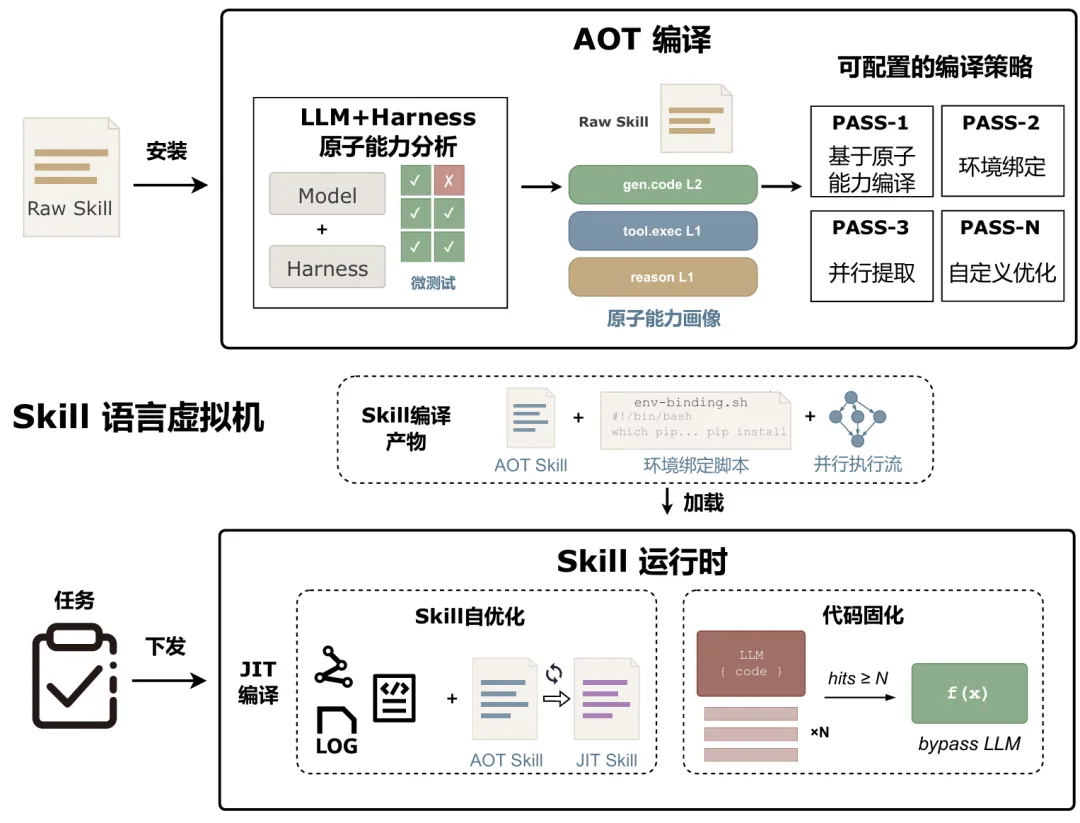
Agent时代重新思考编译技术:Skill是代码,LLM+Harness是异构处理器,借鉴语言虚拟机(Language VM)的设计理念,首次将传统编译器与运行时思想系统性地引入Agent技能领域,SkVM让Skill一次编写,到处高效执行。
核心理念:把Skill当作程序来编译
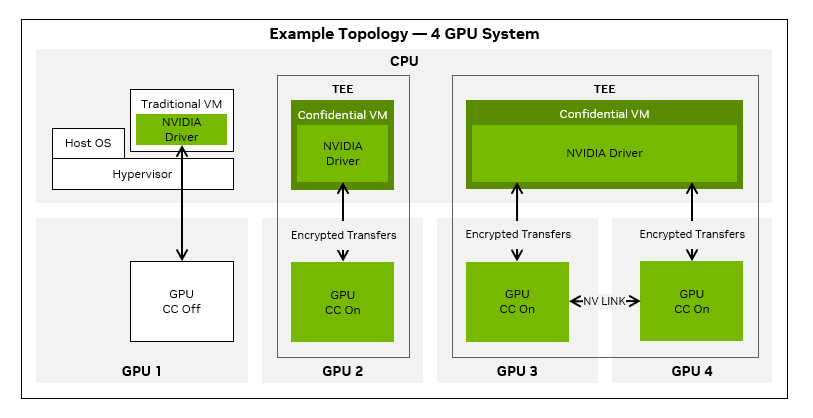
英伟达 GPU 机密计算
传统机密计算主要保护 CPU 执行环境中的数据与代码,其目标是在操作系统、虚拟化层乃至平台管理员不完全可信的前提下,仍然保证工作负载的机密性与完整性。Intel TDX、AMD SEV-SNP 和 Arm CCA 虽然实现路径不同,但本质上都属于 CPU 侧可信执行环境基础设施:通过硬件隔离、内存保护、启动测量和远程证明,为虚拟机或受保护执行域建立一个不依赖宿主软件信任的安全边界。它们解决的核心问题是,应用在 CPU 和系统内存中运行时,如何不被宿主环境窥探或篡改。
但在 AI 基础设施中,仅有 CPU 侧保护并不充分。因为真正承载高价值数据和核心计算的,往往已经不是 CPU,而是 GPU。模型权重、推理输入、检索增强数据、中间激活值乃至部分业务逻辑,都会进入 GPU 显存并在加速器上执行。如果机密计算只覆盖 CPU 虚拟机,而无法覆盖 GPU 执行路径,那么对 AI 而言,这种保护就是不完整的。英伟达 GPU 机密计算的意义,正是在于把机密计算的保护边界从 CPU 扩展到 GPU,使 GPU 成为整个可信执行体系的一部分,保护模型参数、数据和其他重要客户资产。
为什么 AI 时代值得重新讨论 OS:从 Linux Kernel 到 GPU 执行栈的系统重构
https://mp.weixin.qq.com/s/dVpd5_99co4wk0L-tOpiJQ
AI时代的操作系统革新,核心不在于推翻Linux,而在于围绕tensor、graph、kernel、KV cache等新的一等对象,建立一套从驱动、编译器到运行时服务的全新系统抽象,以管理和调度异构计算资源。
DPU PCC
DOCA 官方给出的定义非常直接:Programmable Congestion Control(PCC)允许用户设计并实现自定义的拥塞控制算法,以更灵活地处理集群中的网络拥塞问题。
PCC 不是一个具体的拥塞控制算法,而是一个拥塞控制开发框架。它的目标是提供一套 API 和执行环境,让客户可以自己写算法、加载算法、运行算法,并基于网络反馈动态调整每条流的发送速率。
DPU PCC 的本质,是把拥塞控制从一个封闭的网卡内置算法,升级成一个运行在 DPU 数据路径加速环境中的可编程控制框架。它让开发者能够围绕真实业务需求,自定义反馈机制、流状态管理和速率调节逻辑,从而在 AI、存储和多租户集群中获得更合适的网络行为。
Sandlock:最轻量级的 AI Agent 沙箱
The lightest AI sandbox. A process-based sandbox for Linux, no container, no VM, no root.
应对AI Agent的安全问题,不应盲目堆叠重量级的硬件隔离,而应针对其应用层的行为模式,设计精细、轻量的访问控制策略。Sandlock正是这一理念的实践,它提供了一种更贴合Agent本质的安全方案。
Lightweight process sandbox for Linux. Confines untrusted code using Landlock (filesystem + network + IPC), seccomp-bpf (syscall filtering), and seccomp user notification (resource limits, IP enforcement, /proc virtualization). No root, no cgroups, no containers.
1 | sandlock run -w /tmp -r /usr -r /lib -m 512M -- python3 untrusted.py |
Bubblewrap vs Sandlock
Bubblewrap和Sandlock是两种设计理念和实现路径都截然不同的沙箱工具。简单来说,Bubblewrap是一个通用的、轻量级的“容器构建工具箱”,而Sandlock是一个为AI Agent场景专门设计的、高密度的“进程执行沙箱”。
目标定位不同
Bubblewrap是一个通用的工具,旨在安全地运行一个浏览器或一个游戏等普通应用。而Sandlock则是专为AI Agent量身定做,它思考的问题是:“如何安全、高效地让大模型生成的上万个代码片段并发执行?”。
安全模型的根本分歧
这源于它们对“敌人”的不同理解。
- Bubblewrap默认环境中可能存在主动的攻击者,因此首要任务是利用Namespace创建一个与外界隔绝的**“硬边界”**。
- Sandlock则认为Agent不是攻击者,真正的风险是提示词注入。它的核心不是建立边界,而是通过Landlock和Seccomp执行一套精细的访问控制策略(Policy),例如这个Agent只能读
/data目录,只能写/tmp。
效率的极致追求
在AI场景中,常需同时运行成百上千个沙箱实例。Bubblewrap每个实例都需要独立的初始化过程,资源开销会线性增长。而Sandlock通过其写时复制(COW) 技术,可以瞬间从一个“黄金镜像”克隆出上千个实例,共享内存,极大节省了时间和空间。同时,Sandlock的开销极低,启动仅需5毫秒,远快于传统容器或虚拟机。
如何选择
选择Bubblewrap,如果你的目标是:
- 为普通桌面应用(如一个闭源游戏或聊天软件)提供一个基础的运行沙箱。
- 需要一个无需守护进程、轻量级的通用沙箱工具。
选择Sandlock,如果你的目标是:
- 在AI Agent系统中安全地执行由模型生成的不可信代码。
- 需要高并发、低延迟地执行大量短暂任务(如批量代码评估)。
- 需要精细到每个工具调用的访问控制策略。
基于GPU加速的内存回收方案
vivo的ZRAM异构压缩技术:基于GPU加速的内存回收方案
key idea: 将zram压缩内存数据的操作由CPU offload到GPU以进行加速。