Notes about IB交换机中的SHARP技术
本文将mark下IB交换机中SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)技术的相关notes。
In-Network Computing
在网计算(In-Network Computing),可以简单理解为:让网络在传输数据的过程中,顺便完成一部分原本属于主机的计算任务。这里的“计算”通常不是通用计算,而是聚合、归约、统计、筛选,以及某些固定模式的算术或逻辑操作。
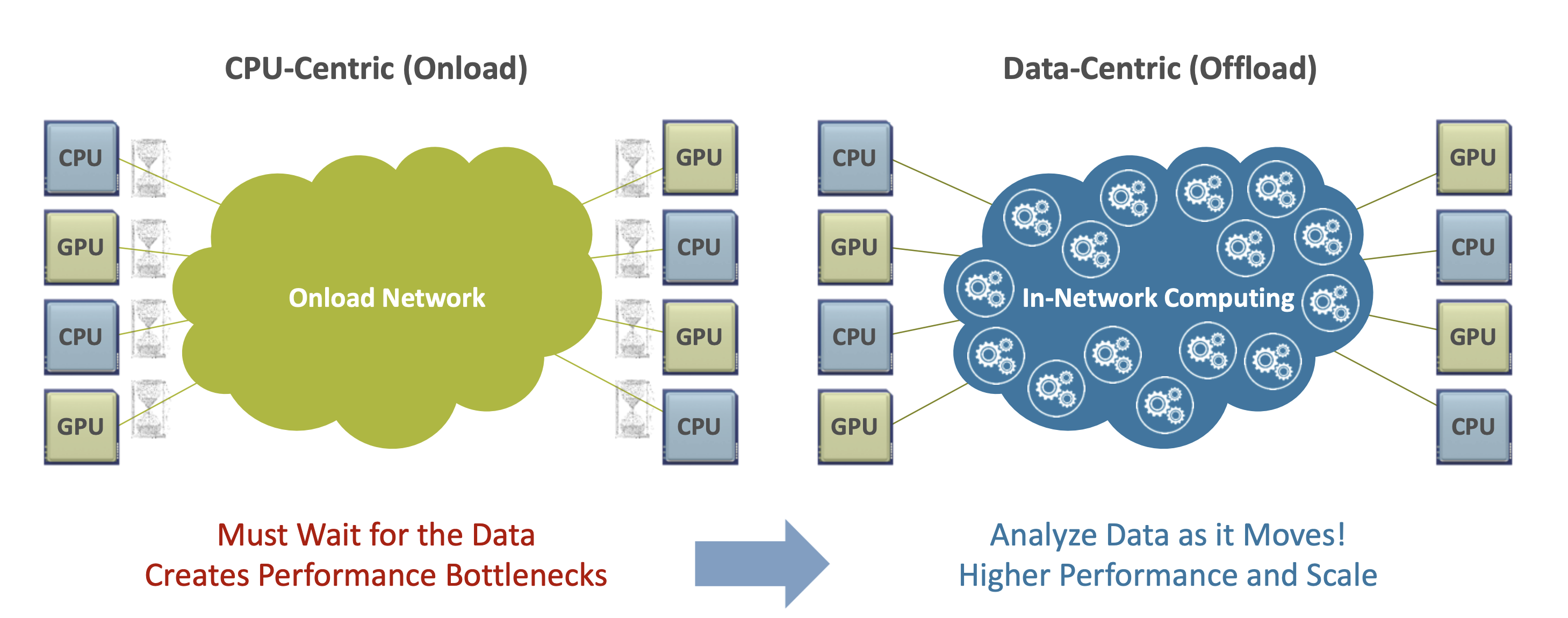
在 AI 和 HPC 场景中,最有价值的一类在网计算,就是对集合通信中的归约操作进行卸载。因为归约是最常见、最频繁、也最容易在规模扩展后成为瓶颈的环节;如果交换机能够在数据流经时,先把多个节点发来的数据做一轮聚合,那么继续向上传输的数据量就会变少,最终回到端点的也不再是大量原始中间值,而是更接近结果的数据。
这会同时带来几个好处:
- 降低端点参与归约的负担
- 减少网络中传输的中间数据
- 缩短集合通信完成时间
- 提高系统扩展效率
而 SHARP,就是这种思想在高性能网络中的代表性实现。
SHARP的介绍
传统模式下,交换机只负责收包、转发、出包;即使是 AllReduce 这类高度结构化的操作,交换机本身也并不真正“理解”归约,因此大量中间数据仍需要在端点之间来回流动,归约主要还是由主机侧完成。
SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)是 NVIDIA 的一种in-network computing技术,用来把 AllReduce、Reduce、Broadcast 等集合通信操作从 CPU/GPU 卸载到 InfiniBand 交换网络中执行。
AllReduce
现代AI训练(如大语言模型)和科学计算严重依赖于集合通信,尤其是 AllReduce 操作(用于同步梯度、参数等)。AllReduce的通信开销常常成为训练瓶颈。
- 传统AllReduce(无SHARP)
- 数据在GPU间多次传输。
- 最终聚合计算由某个GPU的CUDA核心完成。
- 占用宝贵的GPU计算资源(尽管是轻量计算)。
- 产生大量网络流量,消耗带宽,增加延迟。
- 使用SHARP的AllReduce
- 计算卸载: 聚合计算(如求和)由交换机内部的专用硬件引擎执行。
- 流量锐减: 数据在交换机树形网络的每一级就开始聚合,网络中传输的数据量逐级减少,极大降低了最终的网络流量(可降低高达50%以上)。
- 解放GPU: GPU无需处理聚合计算,可以更专注于张量核心的计算。
- 降低延迟: 在网络中就近计算,减少了端到端的通信延迟。
- 核心价值: 将网络从一个被动的“数据搬运工”,转变为一个主动的“计算参与者”,从而打破集合通信的瓶颈。
工作原理
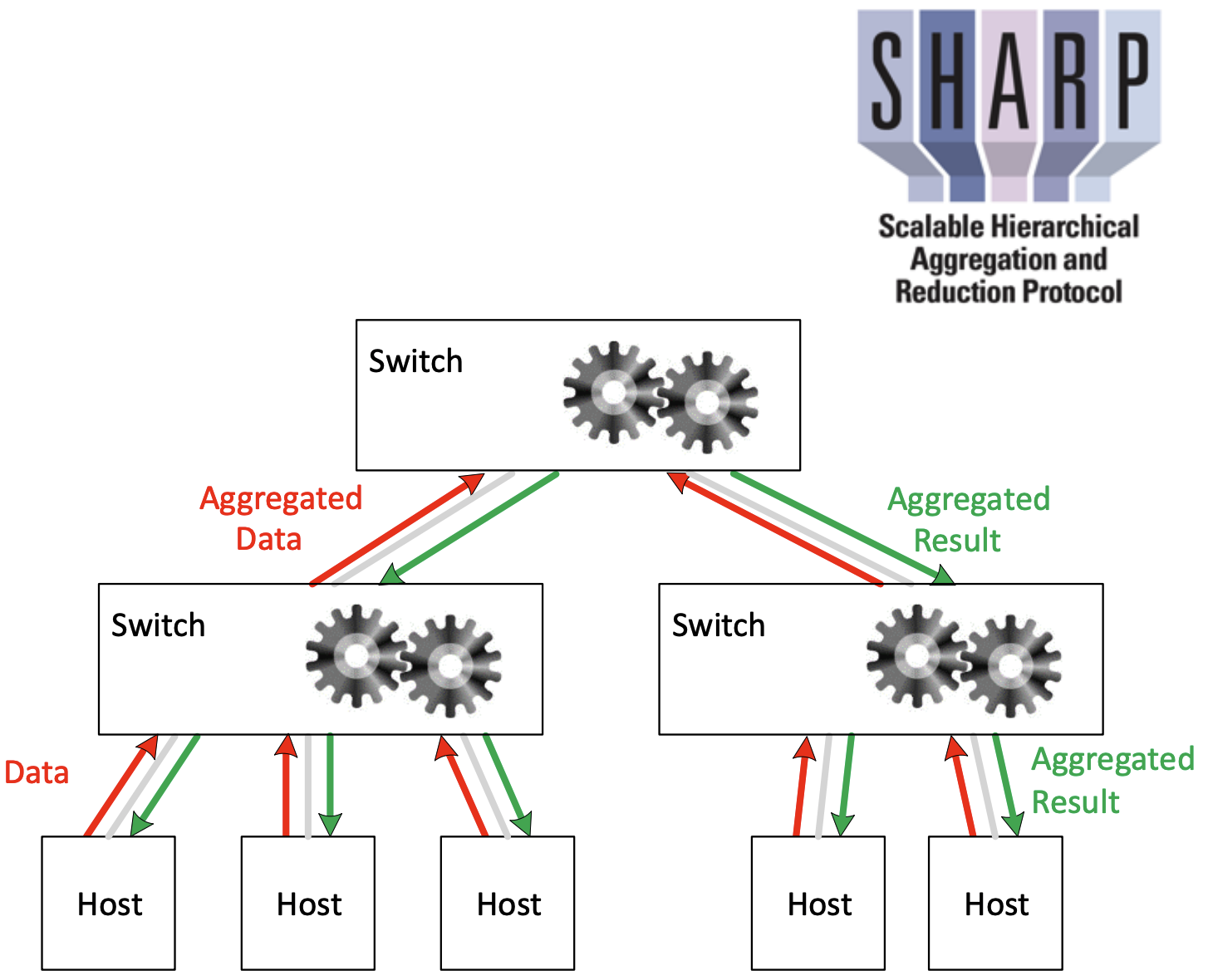
以最常见的“求和”AllReduce为例,剖析SHARP工作原理:
- 初始化与配置: 集群管理软件(如NCCL)识别到支持SHARP的交换机拓扑,并为本次AllReduce操作在交换机上配置一个“聚合树”。
- Leaf叶子节点发送: 每个GPU(主机)将其需要聚合的数据块发送到它所连接的第一级(Leaf叶子)交换机。
- 第一级聚合: Leaf叶子交换机的SHARP引擎接收来自其下所有GPU的数据,在交换机内部硬件中直接进行求和计算,生成一个部分聚合的结果。
- 向上传播: Leaf叶子交换机将部分聚合的结果(数据量已小于原始多份数据的总和)发送到上一级(Spine主干)交换机。
- 递归聚合: Spine主干交换机的SHARP引擎再次接收来自多个下级交换机的部分聚合结果,并进行第二次聚合。此过程在交换机的层次结构中持续向上,直到到达聚合树的根交换机。
- 生成全局结果: 根交换机生成最终的全局聚合结果(所有GPU数据的总和)。
- 结果广播: 根交换机再将这个最终结果沿聚合树向下广播到所有参与计算的GPU。
关键点: 数据在向上传输的过程中不断被“压缩”(聚合),因此从根节点向下广播的数据量是最小的(一份完整结果)。这相比于传统的环状或树状AllReduce算法,显著减少了网络的总数据吞吐量。
SHARP vs. GPUDirect RDMA
- GPUDirect RDMA: 解决的是“路径”问题,允许第三方设备(如网卡)直接访问GPU显存,绕过CPU和系统内存拷贝,降低延迟。它优化的是点对点通信。
- SHARP: 解决的是“流量和计算”问题,在网络内对多个数据流进行聚合计算,优化的是集体通信。
- 关系: 它们是互补的,可以同时启用。GPUDirect RDMA确保数据从GPU到网络的路径最优,而SHARP确保数据在网络中的聚合效率最高。现代AI集群通常同时启用这两项技术。
总结
SHARP是构建大规模、高效率GPU计算集群的一项革命性网络技术。它通过“网络内计算”的理念,直接攻克了分布式AI训练中最耗时的集合通信瓶颈,是当今万卡级GPU集群不可或缺的关键技术之一。
参考资料: