linux kernel中链表的解析
链表
链表是linux内核中最简单,同时也是应用最广泛的数据结构。
1.1 头文件简介
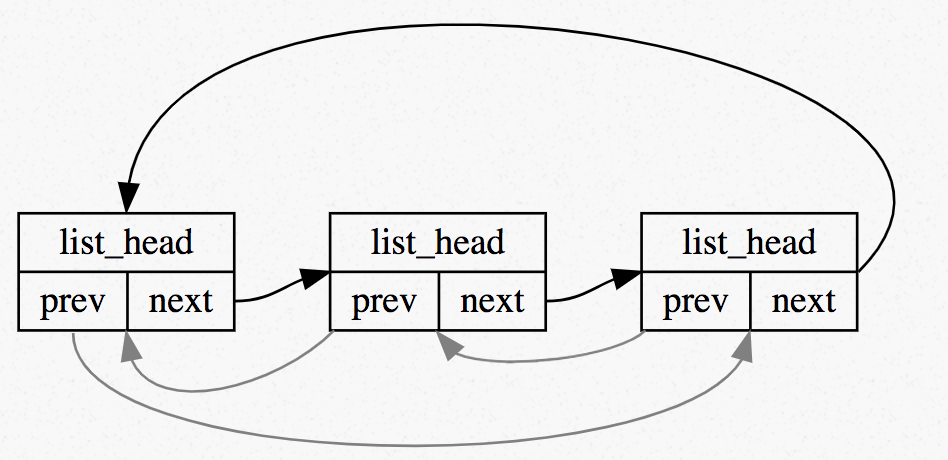
内核中关于链表定义的代码位于: include/linux/types.h1
2
3struct list_head {
struct list_head *next, *prev;
};
include/linux/list.h文件中对每个函数都有注释,我们将在1.3节中介绍常用的链表操作(增加,删除,遍历)的使用方法。
list_empty(head)- tests whether a list is emptylist_add(new_entry, head)- adds a new entry. Insert a new entry after the specified head.list_del(entry)- deletes entry from list.list_for_each(pos, head)- iterate over a list
1.2 链表结构的特点
在阅读list.h文件之前,有一点必须注意:linux内核中的链表使用方法和一般数据结构中定义的链表是有所不同的。
一般的双向链表一般是如下的结构,
- 有个单独的头结点(head)
- 每个节点(node)除了包含必要的数据之外,还有2个指针(pre,next)
- pre指针指向前一个节点(node),next指针指向后一个节点(node)
- 头结点(head)的pre指针指向链表的最后一个节点
- 最后一个节点的next指针指向头结点(head)
具体见下图: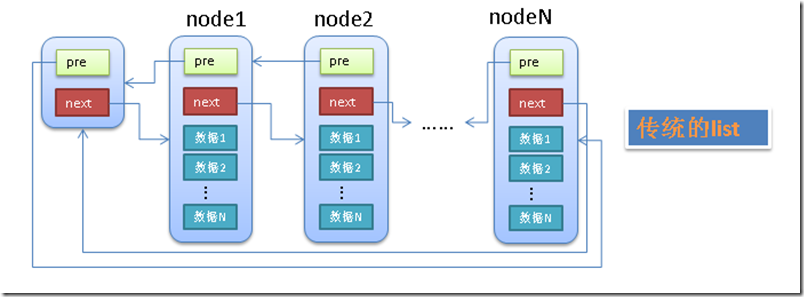
传统的链表有个最大的缺点就是不好共通化,因为每个node中的data1,data2等等都是不确定的(无论是个数还是类型)。
linux中的链表巧妙的解决了这个问题,linux的链表不是将用户数据保存在链表节点中,而是将链表节点保存在用户数据中。
linux的链表节点只有2个指针(pre和next),这样的话,链表的节点将独立于用户数据之外,便于实现链表的共同操作。
具体见下图: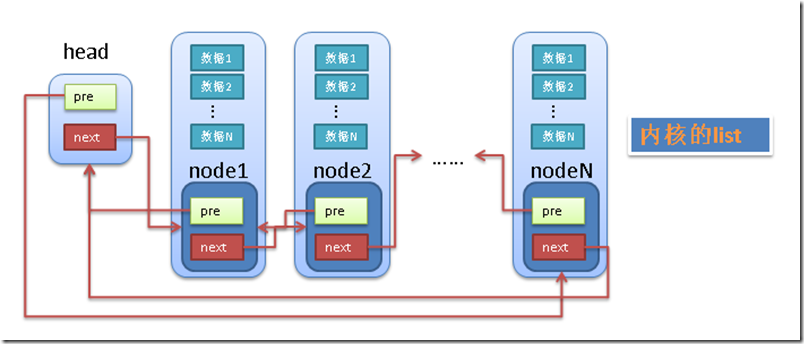
linux链表中的最大问题是怎样通过链表的节点来取得用户数据?
和传统的链表不同,linux的链表节点(node)中没有包含用户的用户data1,data2等。
整个list.h文件中,我觉得最复杂的代码就是获取用户数据的宏定义1
2
container_of(ptr, type, member)
1.3 使用接口
- 向链表中增加结点
给链表增加一个结点:1
list_add(struct list_head *new, struct list_head *head)
该函数向指定链表的head结点后插入new结点。
- 从链表中删除一个结点
从链表中删除一个结点,调用list_del():1
list_del(struct list_head *entry)
该函数从链表中删除entry元素。
- 遍历链表
遍历链表最简单的方法就是使用list_for_each()宏,该宏使用两个list_head类型参数,第一个参数用来指向当前项,这是一个你必须要提供的临时变量,第二个参数是需要遍历的链表的以头结点形式存在的list_head。每次遍历中,第一个参数在链表中不断移动指向下一个元素,直到链表中的所有元素都被访问为止。用法如下:1
2
3
4struct list_head *p;
list_for_each(p, fox_list) {
/* p 指向链表中的元素 */
}
1.4 使用示例
构造了一个内核模块来实际使用一下内核中的链表。
1 |
|
具体运行可参见linux kernel 模块化编程入门。
参考资料:
- cnblogs wang_yb
- republick.gitbooks.io
- List, HList, and Hash Table
- 《Linux内核设计与实现》第六章