Notes about TP && PP && DP
本文将mark下TP(Tensor Parallelism)、PP(Pipeline Parallelism)和DP(Data Parallelism)的相关notes,本文内容转载自不是多卡,而是多种“切法”:一文讲透 TP、PP、DP。
标定前提
本文统一用这个场景来讲:
- 模型:70B
- 精度:FP16
- 模型参数体量:约 140GB
- 服务器:单机 8 张 GPU
- 每张 GPU 显存:80GB
140GB模型参数体量意味着:如果你把模型参数按 FP16 存,总共大约要占140GB 显存。而单张卡只有 80GB。
所以第一件马上成立的事就是:单卡装不下。
这一步非常关键,因为它决定了一个基本事实:
这不是“要不要多卡”的问题。这是“必须多卡”的问题。
但“必须多卡”,并不自动等于你知道该怎么切。
因为你接下来马上会碰到第二个问题:既然 8 张卡总显存有 640GB,那是不是直接随便分一分就行?也不行。因为大模型不是一块静态硬盘文件。
它在跑的时候,除了参数本身,还有:
- 激活值
- 中间结果
- KV Cache(推理时)
- 梯度(训练时)
- 优化器状态(训练时更大)
- 通信缓存
- 框架额外开销
所以真正的问题,不是“640GB 总显存是不是大于 140GB”。而是:你打算怎么把模型和计算过程,拆到这 8 张卡上。
这就引出了今天的主角:
- TP:Tensor Parallelism
- PP:Pipeline Parallelism
- DP:Data Parallelism
它们都和“多卡”有关。但不是一回事。
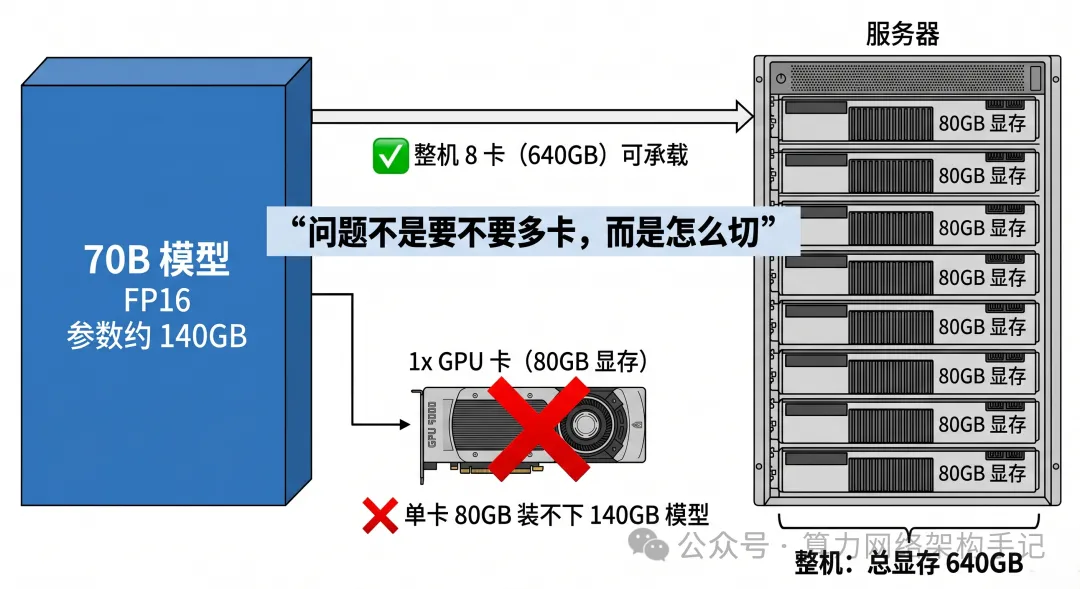
三种“切法”
TP 是横着切。
PP 是竖着切。
DP 不是切模型,而是复制模型、切数据。
TP 在切什么?
它在切的是:同一层内部的张量计算。
也就是说,一层本来是一个大矩阵乘法。TP 会把这个大矩阵,拆到多张卡一起算。
PP 在切什么?
它在切的是:模型的层。
也就是说,模型原本是一层接一层串起来的。PP 会把前面几层放到一组卡,后面几层放到另一组卡。
DP 在切什么?
它不切模型结构。它切的是:输入数据 / batch。
也就是说,每一份模型副本都长得一样。但不同副本同时处理不同的数据,然后再同步梯度。
总结
TP 解决“单层太大”。
PP 解决“整模型太长、装不下”。
DP 解决“吞吐不够,想并行处理更多数据”。
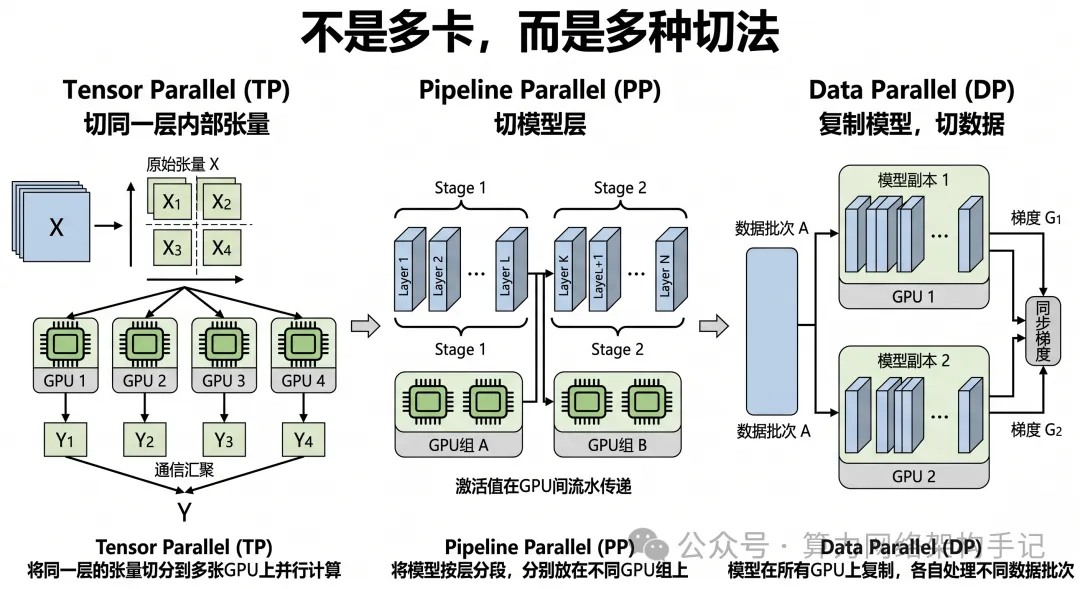
PP
PP最先回答一个现实问题:140GB 模型,单卡 80GB 装不下,怎么办?
最直观的办法是什么?把模型按层切开。
比如,一个大模型本质上可以粗略理解成很多层堆起来:
- Embedding
- Transformer Block 1
- Transformer Block 2
- …
- Transformer Block N
- 最后输出层
这时候,PP 的思路就是:
既然一整本书放不进一个抽屉,
那就把这本书按章节拆开,前半本放一个抽屉,后半本放另一个抽屉。
在工程上,这就叫Pipeline Parallelism。
PP=2是最自然的第一步
70B 模型 140GB。
如果按 PP=2 去切,意味着:
- 模型前半段放在一组 GPU
- 模型后半段放在另一组 GPU
从参数体量角度粗略看,就是:140GB/2=70GB
这就意味着:每一段模型参数大约 70GB,而 70GB 小于单卡 80GB。
于是,一个非常重要的事实出现了:从“参数能否装下”这个角度看,PP=2 已经足够。
PP首先是在解决“模型按层分段存放”,这是它最核心的意义之一。
PP=2不代表只用2张卡
很多人一看到 PP=2,就会下意识理解成:那是不是只用 2 张卡?
不一定。PP=2 的意思,是模型被分成2段。至于每一段用几张卡,那要看你这一段内部是否还继续做TP,或者做别的切法。
也就是说:
- PP 决定的是“分几段”
- 不是“总共几张卡”
这一点必须记住。
比如后面我们很可能会用:
- PP=2
- 每段再用 TP=2
- 那总共就是 2 × 2 = 4 张卡
甚至还可能在更多机器上叠加 DP。
所以 PP 和卡数之间,不是简单一一对应关系,它更像“先把模型分成几大段”
PP的代价
PP 解决了装不下的问题,但它不是免费的。
因为一旦按层分段,数据在前向传播时就必须这样走:
- 输入先进入第 1 段模型
- 第 1 段算完,把中间激活传给第 2 段
- 第 2 段再继续算
反向传播也是一样,要一段一段回传。
所以 PP 带来的代价是:跨 stage 的激活传输,以及更重要的:流水线气泡(pipeline bubble)。
因为模型是串行分段的,如果流水线调度不好,就会出现:
- 前一段忙
- 后一段在等
- 某些 GPU 一部分时间没有活干
这就是为什么PP虽然很适合解决“装不下”,但它并不是性能上永远最优的切法。
它优先解决的是:模型太长、显存不够的问题。
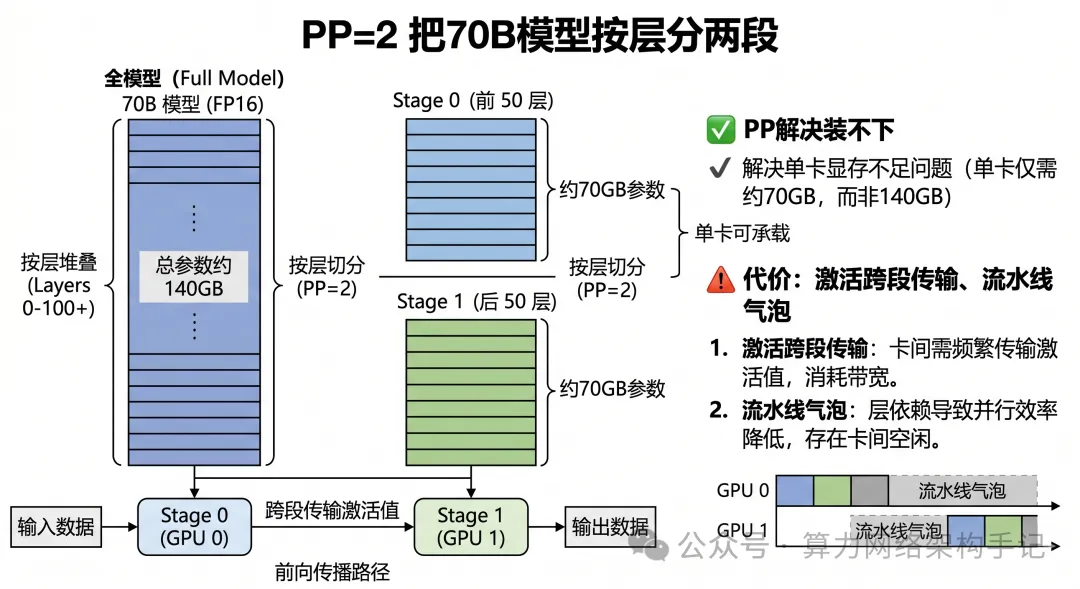
TP
如果说 PP 像是“把一本书按章节撕成上下两半”,那 TP 更像是:把同一页内容,左右拆开,让两个人同时看。
大模型里的核心计算,本质上大量来自矩阵乘法。
比如一个线性层,本来可能是这样:Y = XW
这里的 W 可能非常大。
如果这个矩阵很大,大到一张卡算它已经很吃力,或者你想进一步并行加速,那就可以用 TP。
TP 的思路是:
不是把“前面几层”和“后面几层”分开。
而是让“同一层”本身,拆成几块,放到多张卡一起算。
在层内切矩阵
比如一个很大的权重矩阵 W,你可以按列切成两半,或者按行切成两半。
这样:
- GPU0 算一部分
- GPU1 算另一部分
- 最后再把结果拼起来,或者做归约
这就是 TP 的核心。
所以 TP 不是“层和层之间分工”。而是:同一层内部,多张卡协同完成。
为什么要做 TP?
主要有两个原因:
原因一:单层太大
有些单层参数和中间计算规模本来就很大。即使整模型通过 PP 已经分段了,某一段内部的某些层仍然很重。
原因二:想提升单层并行度
即便显存够,你也可能想让同一层在多张卡上并行算,加快速度。所以 TP 解决的不是“整本书放不下”。而是:同一页太宽,一个人看不过来。
代价
TP 最核心的代价是:层内通信。
为什么?因为同一层被拆到了多张卡上。那每次前向和反向过程中,多张卡之间都要交换部分结果。
比如常见的:
- AllReduce
- AllGather
- ReduceScatter
你一旦做了 TP,这些 collective 通信几乎就绕不过去。也就是说,TP 带来的好处是:
- 同一层可以多卡一起算
- 单卡显存压力更小
- 单层算力更容易并行起来
但它的代价就是:通信更频繁。
而这件事一旦放到多机环境,就会和 NCCL、AllReduce、Incast、ECN 这些网络问题直接撞上。
这也是为什么很多人后来会发现:
TP 不是“白赚性能”。
它经常是在“更多并行”和“更多通信”之间做权衡。
DP
如果 PP 解决“装不下”,TP 解决“同一层太大或想并行更快”,那 DP 解决的是什么?答案是:吞吐。
也就是:
我希望同一时间处理更多样本,让更多 GPU 一起吃不同数据。
这就是 Data Parallelism。
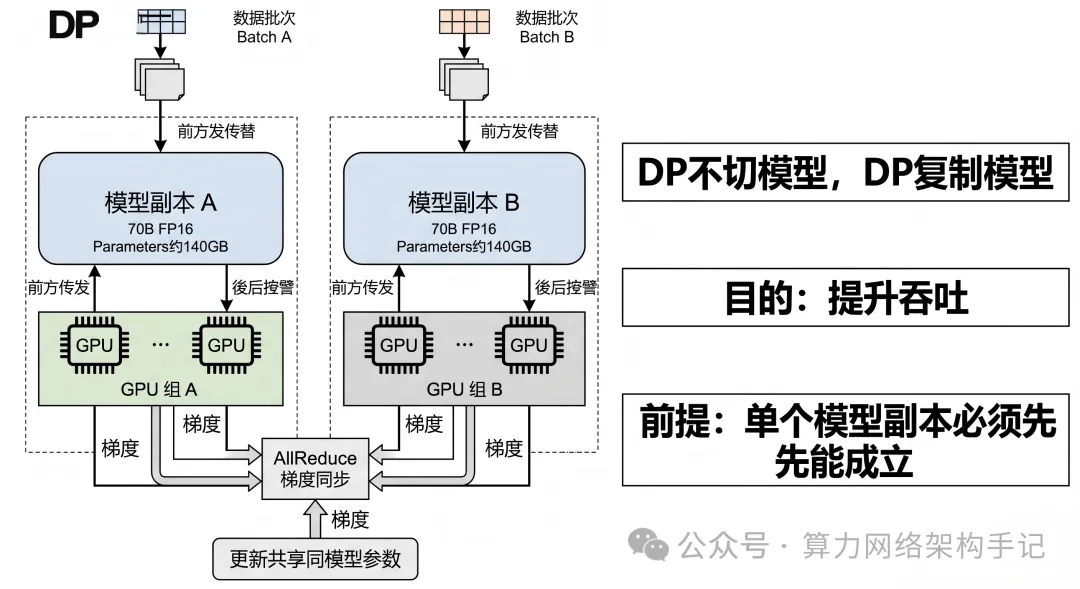
DP的本质:每份模型副本都长一样
这是理解 DP 的第一关键点。
DP 不会把模型切开,它会做的,是把同一份模型复制多份。
比如你有两个 DP 副本,那就是:
- 副本 A:一整份模型
- 副本 B:一整份模型
这两份模型参数初始相同,但它们分别处理不同的数据 batch。
为什么最后还要同步?
因为虽然两份模型处理的是不同数据,但你希望训练完之后,它们还是同一个模型。
所以每一轮反向传播结束后,不同副本的梯度要做同步。
这一步最经典的就是:AllReduce。
也正因为如此,DP 一旦规模上去,网络压力会迅速增大。因为它不是偶尔同步,而是每一步都在同步。
在我们的这个场景里,单机8卡适合直接做DP吗?
如果你只从“模型装不装得下”看,答案是:不能先直接谈 DP。
为什么?因为 DP 的前提是:每个副本本身得先成立。
也就是说,你得先能把“一份模型副本”放到某些卡上,然后才谈复制成多份。
而我们这里,70B 模型 140GB,单卡 80GB,单卡本身放不下。
所以如果没有 PP 或 TP 先把单副本做成立,你根本没法谈 DP,这一步非常关键。
很多人第一次接触时,会本能问:
8 张卡,DP=8 行不行?
不行。因为 DP=8 的含义是:你要有 8 份完整模型副本。
而完整模型 140GB,单卡 80GB 放不下,所以你不能把一份完整模型直接塞到一张卡上,再复制 8 份。
这也是为什么我们说:
DP 不是第一步。
它通常建立在 TP/PP 已经先让“单副本可运行”之上。
具体例子
直接回到这个问题:
70B 模型,FP16,140GB。
单机 8 张 GPU,每张 80GB。
TP、PP、DP 到底该怎么理解?
最关键的是先建立一个顺序。
第一步:先解决“单副本能不能成立”
这个问题最先决定的是:不能先想 DP。
因为 DP 是复制副本。但一份副本本身都放不下,复制无从谈起,所以要先考虑 TP 和 PP。
第二步:最直观的第一刀,通常是 PP=2
因为 140GB ÷ 2 = 70GB。
从参数体量上看,每段 70GB,可以落进 80GB 卡,所以从“装下参数”这件事出发,PP=2 是一个非常自然的第一步。
但这里你要立刻意识到:这只是“参数大致装下”,并不等于实际运行一定完美,因为还有激活、缓存、框架开销等。
第三步:再考虑每一段内部要不要 TP
如果某个 stage 内部的单层计算仍然很重,或者你希望更高的并行度,那就可以在每个 stage 内部再做 TP。
比如一个很常见的思路:
- PP=2
- 每个 stage 再 TP=2
那总共就用到:2 × 2 = 4 张 GPU,这时,每个模型副本占 4 张卡。
这一步很重要,因为它让你第一次看到:PP 和 TP 是可以叠加的。不是二选一,而是先按层分段,再在段内继续拆张量。
第四步:剩余 GPU 才有可能拿来做 DP
如果你总共有 8 张卡,而一份模型副本用了 4 张卡(PP=2 × TP=2),那你剩下的还能干什么?
答案是:可以再复制一份副本。
于是就得到:
- PP=2
- TP=2
- DP=2
因为:PP × TP × DP = 2 × 2 × 2 = 8
刚好用满 8 张卡。
这就是为什么很多人第一次听到这种组合时,会突然“通了”,它不是在背一个缩写组合,而是在做一件非常具体的资源分解:
- 先按 PP=2 解决模型分段装载
- 再按 TP=2 解决段内并行与层内切分
- 最后按 DP=2 利用剩余资源复制两份副本,提升吞吐
这就是一个完整的思考链。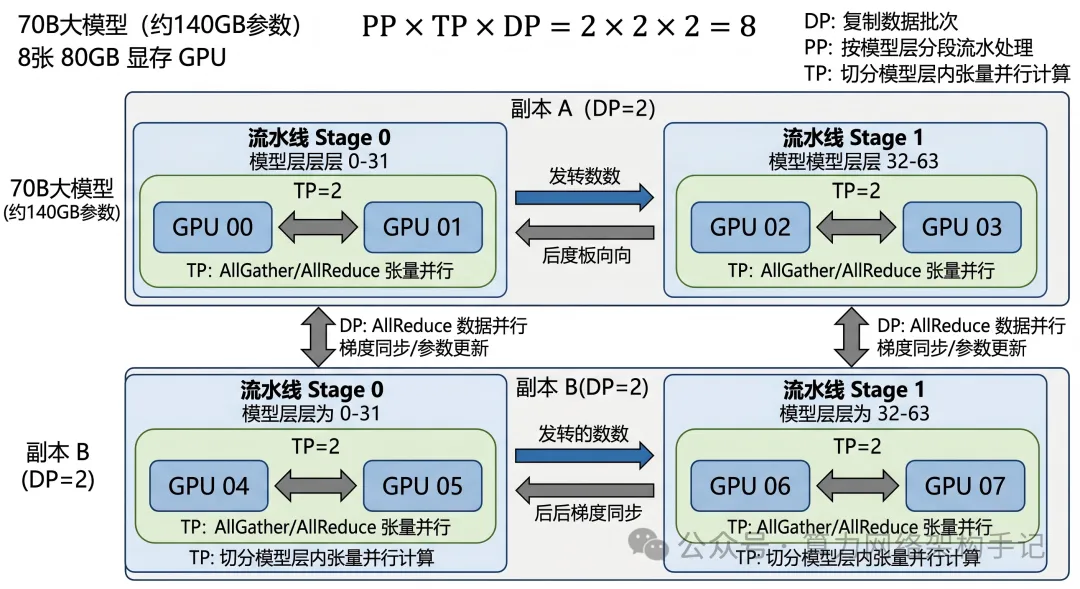
DP的计算
比如你可能会听到这样的问题:
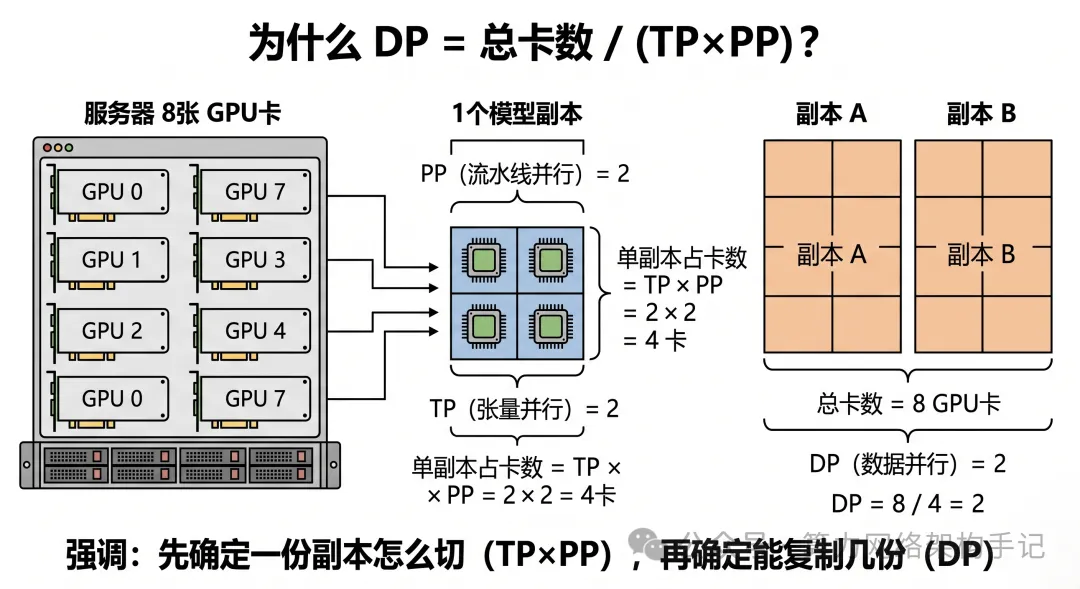
70B 模型,8 张卡,PP=2,TP=2,那 DP 到底是不是 2?
答案是:如果你总共只有 8 张卡,而且一份副本占 4 张卡,那 DP 就是 2。
因为 DP 的定义不是“我想设几就设几”,而是由总卡数和单副本占卡数一起决定的。
公式其实非常简单:DP = 总GPU数 / (TP × PP)
在这个例子里:DP = 8 / (2 × 2) = 2
所以很多人真正没想明白的,不是数学,而是逻辑顺序:
- TP × PP
先定义了“一份模型副本需要多少卡” - DP
再定义“在总卡数里,可以复制多少份副本”
也就是说:DP 不是凭空来的,DP 是在 TP/PP 先把单副本做成立之后,剩余资源所能容纳的副本数。
代价
真正理解这三个东西,不能只看它们“怎么切”,还要看:它们分别引入了什么代价。
因为工程上最难的,从来不是名词,而是代价。
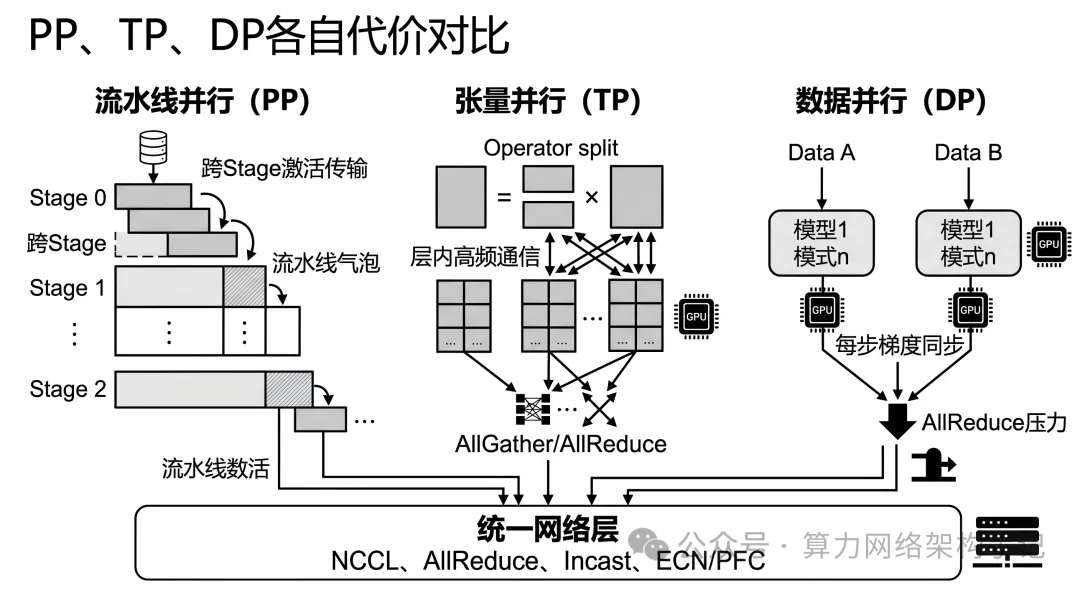
PP 的代价:段间依赖 + 流水线气泡
PP 把模型按层切成几段,它最大的优点是:
- 最直观地解决“装不下”
- 每段模型相对独立
但它的问题是:
- 前后段天然串行依赖
- 要传激活
- 流水线不饱满时容易空等
所以 PP 更像是在说:我接受一定的串行和调度复杂度,换模型能装下。
TP 的代价:层内高频通信
TP 的优点是:
- 同一层可以多卡一起算
- 单层规模可拆
- 层内并行度提高
但它的问题是:
- 每层都要频繁 collective 通信
- 通信会非常密
- 一旦跨机,网络压力会快速放大
所以 TP 更像是在说:我接受更多层内通信,换单层并行和显存拆分。
DP 的代价:每一步都要梯度同步
DP 的优点是:
- 思路最直观
- 最容易提高吞吐
- 每个副本内部逻辑一致
但它的问题是:
- 训练时每一步都要 AllReduce 梯度
- 副本越多,同步压力越大
- 网络会直接成为性能关键因素
所以 DP 更像是在说:我接受更大的梯度同步压力,换更高吞吐。
网络通信
因为一旦你不再是单卡,而是 TP/PP/DP 混合,通信就不再只是“有一点”。
而是会分成不同形态:
- TP:层内高频通信
- PP:段间激活传输
- DP:副本间梯度同步
这些通信最终都会落到:
- NCCL
- AllReduce
- AllGather
- ReduceScatter
- P2P
- Incast 风险
- ECN / PFC / queue 管理
也就是说,TP/PP/DP 不只是“模型切法”。
它们本质上也在定义:你的网络压力会长成什么样。
总结
到这里,我们把全文压缩成三句话。
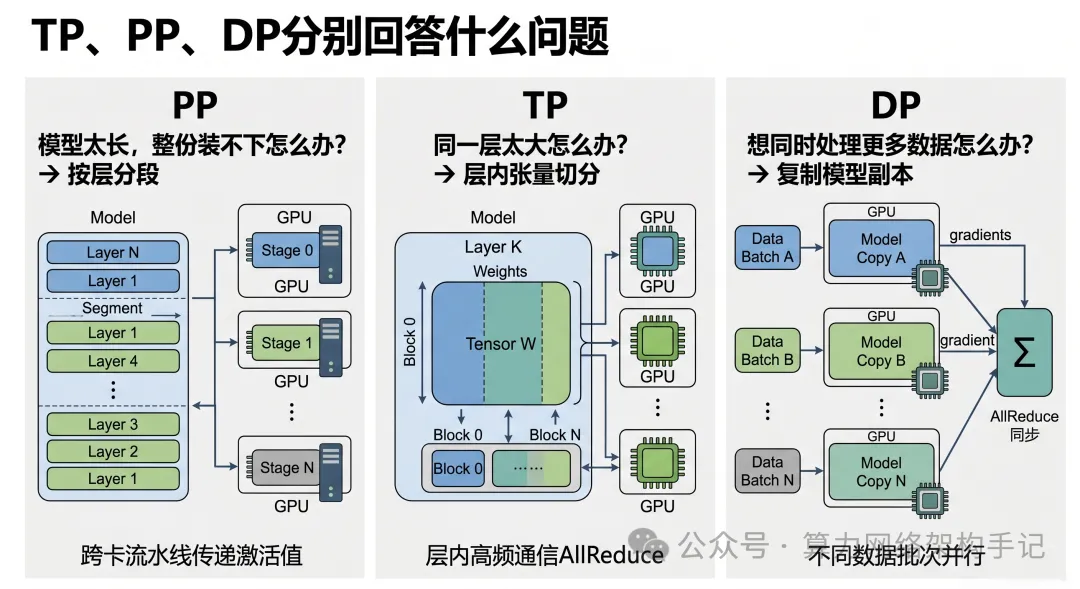
PP 在回答:模型太长、整份装不下,怎么办?
答案是:按层分段。
TP 在回答:同一层太大,或者想让同一层多卡并行,怎么办?
答案是:把同一层内部的张量拆开。
DP 在回答:单副本已经能跑了,但我想同时处理更多数据,怎么办?
答案是:复制模型副本,切数据。
参考资料: